统计功效(power)与效应量(effect size)
本文介绍了统计推断中的两个重要指标,分别是统计功效和效应量,它们是p-value指标之外的重要补充。
文章和例题的内容来自近期生统课的备课记录。
一、定义
(一)效应量
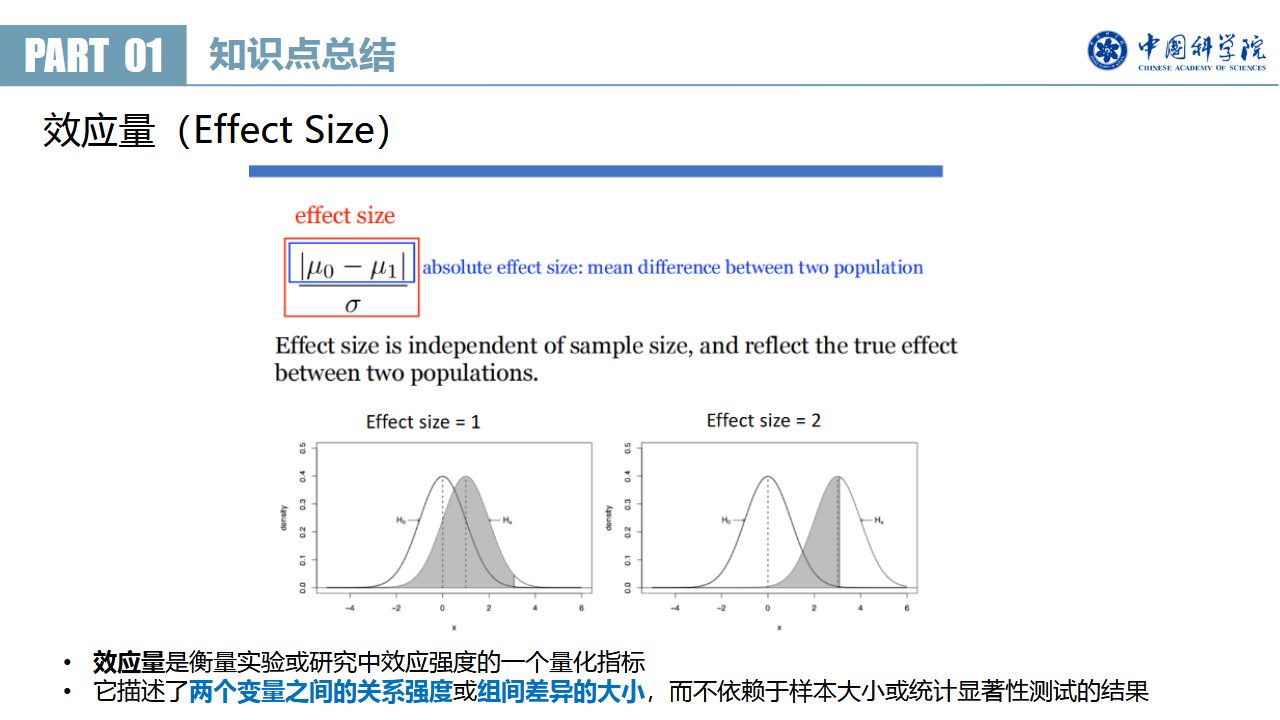
效应量(effect size)是衡量现象本身的大小或强度的一个统计指标,回答的问题是“实验效果大不大”。它可以看作是统计检验中的另一个指标p-value的补充。
p-value的大小反映的是“现象是否存在”,p-value越显著,则某个现象(或者差异)越有可能存在;但是关于这种现象(或者差异)的大小和强度,单从p-value是无法得到的,此时效应量(effect size)的大小就很有意义。
效应量的一个定义(这个定义又被称之为Cohen’s d): $\text{Effect size}=\frac{|\mu_0-\mu_1|}{s_{pooled}}$ 。
在大多数情况下,两个样本之间的方差不相等,因此上面公式的分母部分要使用合并标准差。合并标准差的计算公式为: $s_{pooled}=\sqrt{\frac{(n_1-1)s_1^2+(n_2-1)s_2^2}{n_1+n_2-2}}$
根据 Cohen 标准,d=0.2 小,0.5 中,0.8 大。可以根据这个标准,大致判断现象的强弱程度。
(二)统计功效

统计功效 (Power)指的是,假设检验中,当H0 为假时,正确拒绝的概率。其数学定义为power=1-β,其中β是type II错误率。
在机器学习中,有另一个概念,即查全率 (Recall / TPR,有时候也叫召回率 / 敏感度 / sensitivity),在数学定义上,查全率 和 统计功效 完全相同,都反映的是在原假设错误的条件下统计检验方法能够正确拒绝原假设的概率。在某些问题中(比方说,用试剂盒在高危人群中筛选患者),我们会希望查全率(或者说统计功效)越高越好。

有很多因素会影响统计功效。比方说:
- α增加,β降低,则power=1-β也一并增加。这就是说,较不保守的显著性水平可以提高统计功效;代价就是type I错误(假阳性)会增高,例如试剂盒把许多健康人当作患者筛选了出来。
- 增加样本量会提高统计功效。这是因为,基于中心极限定理,样本的抽样分布的方差会随着样本量的增加而降低(也就是Ha的分布曲线更瘦);于是在相同的α水平下,β会降低,则power=1-β增加。
- 增加效应量也可以提高统计功效。效应量的增加,反映在样本的抽样分布上,就是Ha的分布与H0的分布之间的距离更远;于是在相同的α水平下,β会降低,则power=1-β增加。
power的计算涉及到概率分布函数的累积分布的计算,因此需要具体问题具体分析。下面我们可以看一下具体的问题。
二、一道例题
为了研究两种抗生素对抑菌圈直径(mm)的影响,实验中随机选取了独立的培养皿(非配对设计)。已知抑菌圈直径服从正态分布,且两组方差相等。
- 实验组(抗生素A):18.5, 19.2, 17.8, 20.1, 19.5, 18.9
- 对照组(抗生素B):15.2, 16.8, 14.9, 16.3, 15.8, 16.1
使用t-test检验两种抗生素的抗菌效果是否存在显著差异(双侧检验,α=0.05),并计算效应量(effect-size)和统计功效(power)。
参考答案
1. t-test
对两组数据的t-test部分,我们首先设定原假设H0:“两组数据之间没有差异”;以及备择假设H1:“两组数据之间存在显著差异”。
易得: $\mu_1=19, \mu_2=15.85, \text{var}_1=0.64, \text{var}_2=0.499, n1=n2=6$
经过F检验,我们可以确定两组数据符合方差齐性假设(过程略),因此可以用标准t-test流程进行计算。于是我们可以得到: $s_{pooled}^2 =\frac{(n1-1)*var1 + (n2-1)*var2}{n1 + n2 - 2}=0.5695$
进一步得到 $t =(\mu_1 - \mu_2) / s_{pooled}^2=7.229767, df=n1 + n2 - 2=10$
查询自由度为10的t分布表,可得在双侧检验条件下的 $p = 2.825066\times 10^{-5}$ 。这是一个很显著的p值,远小于α=0.05,因此我们拒绝原假设H0,可以认为两组数据之间存在显著差异。
这道题t检验部分的R代码如下:
1 | group1 <- c(18.5, 19.2, 17.8, 20.1, 19.5, 18.9) |
2. 计算效应量
按照前面讲述的方法,我们可得:
$s_{pooled}=\sqrt{\frac{(n_1-1)s_1^2+(n_2-1)s_2^2}{n_1+n_2-2}}\approx 0.7546$
$\text{Effect size}=\frac{|\mu_0-\mu_1|}{s_{pooled}}=\frac{|19-15.85|}{0.7546} \approx 4.174$
根据 Cohen 标准,d=0.2 小,0.5 中,0.8 大,本题中的两组数据d=4.174,这是一个极其巨大的效应量。意味着抗菌效果差异显著,远大于随机波动。
3. 计算统计功效power
回顾课件,统计功效的定义是power=1-beta,而beta(type II错误率)和alpha(type I 错误率)是一组相互关联的统计量。题目中给出了双侧检验alpha=0.05,我们可以以此为切入点计算power。
为了算统计功效,我们需要先理解非中心 t 分布。
- 中心 t 分布:零假设为真时(均值差=0),t 值围绕 0 波动。
- 非中心 t 分布:备择假设为真时(均值差≠0),t 值围绕一个非中心参数(NCP,Non-Centrality Parameter)波动。非中心参数 $\delta$ 的计算公式为 : $\delta=d\sqrt{\frac{n_1n_2}{n_1+n_2}}$ 其中 $d$ 为效应量。
题目中给出了两组数据,基于这两组数据我们可以算出零假设下的t分布($\sim t(\delta=0,df=10)$)和备择假设下的t分布($\sim t(\delta=7.23,df=10)$),如下图所示。

上图展示了两个t分布的曲线,而我们要求的power和beta就在两个临界t值所围成的曲线下面积中【具体而言,t=±2.228这两条线与红色的t分布曲线围成的曲线下面积,对应着beta;红色的t分布曲线下的所有面积,减去前面的beta,剩下的就是power】。我们可以按照下面的方法step-by-step的计算出power:
- 首先,计算双侧alpha=0.05情况下的临界t值:运行
qt(0.025, df = 10)和qt(0.975, df = 10)得到临界t值为 $\pm 2.228$ - 接下来,计算在H1 t分布($t(\delta=7.23,df=10)$)下,两个临界t值之间的曲线下面积,这个曲线下面积即为beta:运行
pt(q=2.228, df=10, ncp=7.23)-pt(q=-2.228, df=10, ncp=7.23),得到 $\beta=3.81025\times 10^{-06}$ - 于是我们有: $\text{power}=1-\beta=1-3.81025\times 10^{-06}\approx 0.9999962$ 。这是一个非常大的power值,意味着检测出该差异的概率接近 100%。
我们还可以使用R语言的pwr包进行计算:
1 | > library(pwr) |
结果和我们手动计算的一样。注意到,这是一个非常大的power值,意味着在这道题的数据上,检出真实效应的能力非常强。