文献阅读笔记:从祖先重组图推断选择性扫荡的深度学习方法
论文信息: Hejase, Hussein A et al. “A Deep-Learning Approach for Inference of Selective Sweeps from the Ancestral Recombination Graph.” Molecular biology and evolution vol. 39,1 (2022): msab332. doi:10.1093/molbev/msab332

背景
这篇文章提出了一种基于LSTM神经网络的正选择检测方法。
作者介绍
本文的通讯作者是来自冷泉港西蒙斯定量生物学中心的Adam Siepel,他的实验室在发表本方法前已经在包括Nature、Nature genetics在内的期刊上发表了一百多篇文章,并开发了PHAST、ARGweaver等知名群体遗传学方法。
两位共同一作分别是博士后学生侯赛因和博士研究生Mo ZIYI

关于LSTM
本文是深度学习方法在群体遗传学中的一个重要应用。深度学习方法又称为深度神经网络,其可以基于给定的数据训练出预测模型,用于分类任务或者回归任务。由于神经网络中不同神经元连接方式的灵活性,经过精心设计和训练的深度学习模型可以达到很好的预测效果(如下图, Zou J, Huss M, Abid A, Mohammadi P, Torkamani A, Telenti A. Nat Genet. 2019;51(1):12-18 )
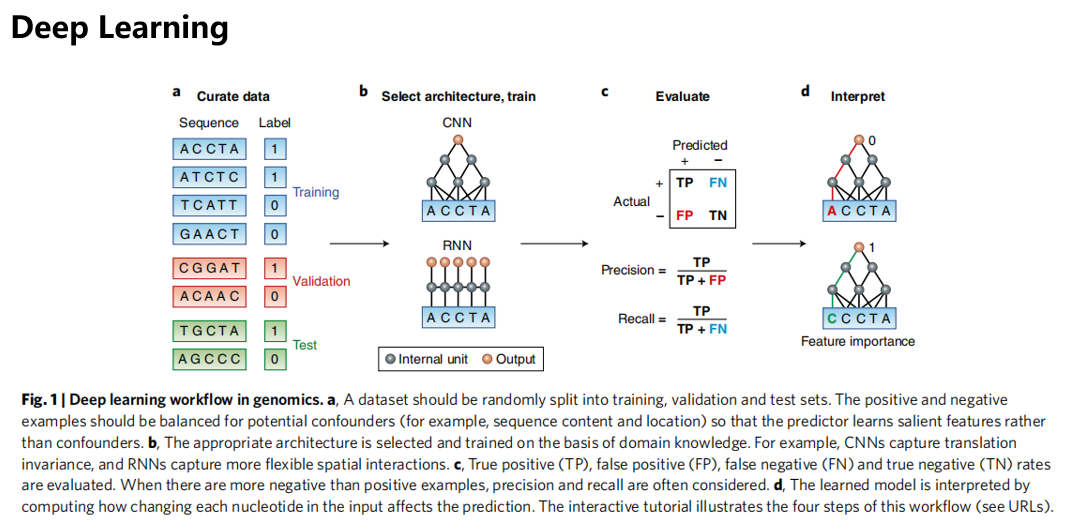
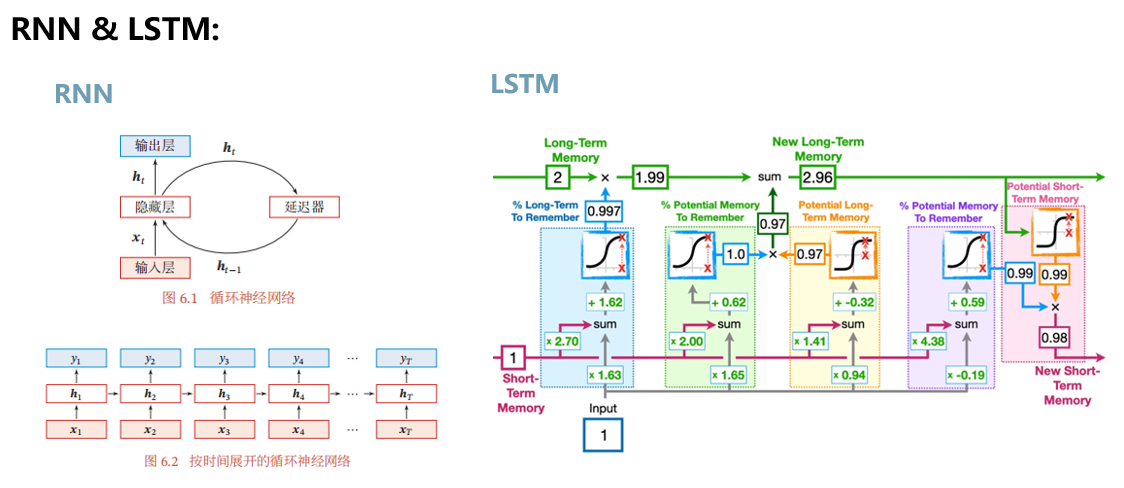
循环神经网络(RNN,如下图)是深度神经网络的一种类型,其输入为序列数据,而模型的输出会基于当前神经元的输入和之前的若干神经元的输出,这样的结构很适合基因组这样的序列数据。
长短时程记忆神经网络(LSTM)是一种经过改进的RNN模型,其单个神经元的模型如右图所示。LSTM引入了长时程记忆的机制,因此可以很好的应对传统RNN模型在训练中容易发生的梯度爆炸和梯度消失问题,因此有着非常广泛的应用。在LSTM的基础上发展出了Transform模型,这是今天非常火爆的chatGPT等大型语言模型的基础。
这篇文章则是将LSTM应用在了祖先重组图谱(ARG)当中,从而实现了对选择压力即所谓selective sweep的检测。
关于祖先重组图(ARG)
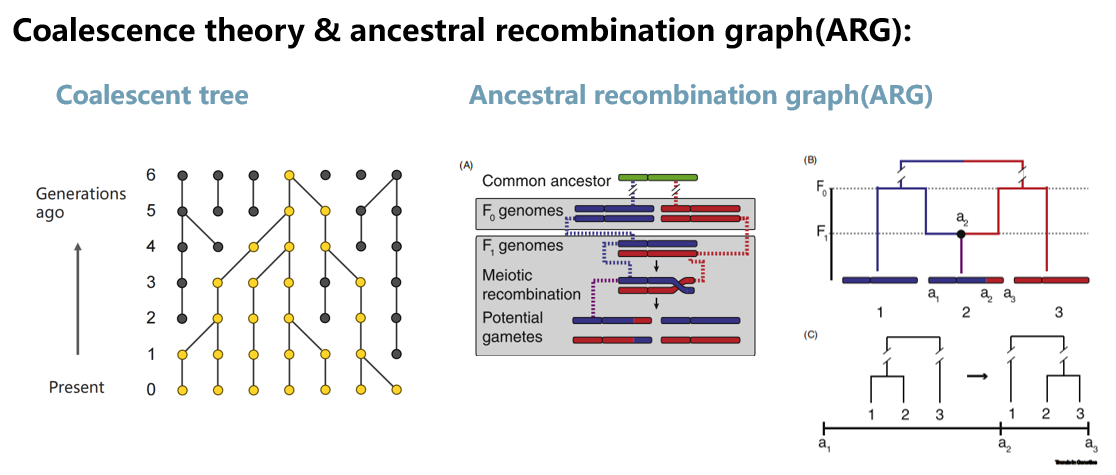
我们先介绍一下祖先重组图(ARG)。在说ARG之前,我们简单回顾一下溯祖模型。如下图,所谓溯祖(Coalescence)是指在时间上回溯,一组等位基因的谱系在共同祖先处合并的过程。我们可以通过从一个群体中采样的等位基因来研究基因的祖先历史,从而推断群体的遗传特征(如果想要了解更多,可以阅读 Principle Of Population Genomics(3rd) 中 chapter3 的相关章节)。
例如,下图左图,当前群体的所有等位基因(黄色圆圈)经过6个世代的回溯能够找到同一个共同祖先,在这个回溯过程中我们可以得到一棵遗传谱系树,其拓扑结构和枝长等属性包含了许多重要的信息,可以帮助我们确定每个等位基因的出现时间以及群体频率变化情况。
由于基因组不同区域存在重组,因此如果我们根据基因组不同区域去建立溯祖树,那么我们将得到一系列枝长和拓扑结构存在差异的树,当我们把这些差异考虑进去以后就构成了一个祖先重组图(如下图的右图)。
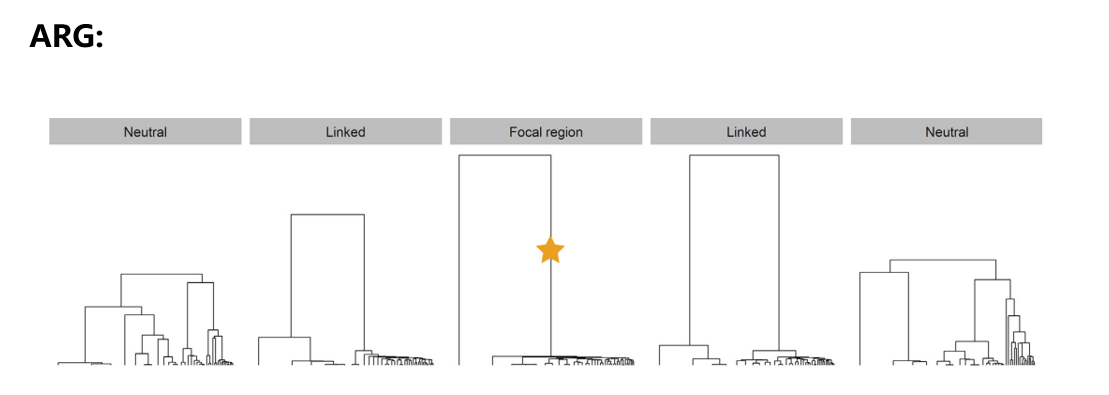
不同选择压力条件下,基因组区域所呈现出的ARG的拓扑结构也存在差异。下图中,黄色五角星标记了群体中出现的有益突变,从图中可以看出在有益突变出现后,携带该有益突变的谱系在短期内出现了大量扩张,产生了大量极短的分支,这是受到选择的基因组区域的ARG的显著特征之一( Hejase HA, Dukler N, Siepel A. Trends in Genetics. 2020;36(4):243-258. )。因此,我们可以利用ARG的这种拓扑结构特点进行正选择检验。
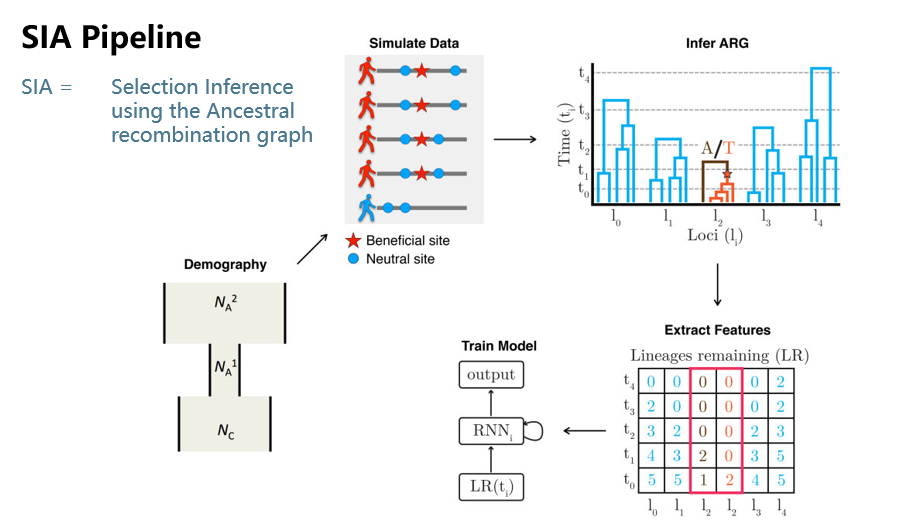
方法构建
本文提出了SIA方法,基于LSTM和ARG信息检测正选择信号。其大体流程分为这样几步:
- 1、估计研究对象的群体历史
- 2、基于群体历史的参数,我们使用discoal simulator获得了中性区域和正选择区域的基因组模拟数据。
- 3、对模拟数据进行ARG的推断
- 4、进行特征提取
- 5、基于上述数据进行神经网络的训练,并将训练好的模型用于真实数据,从而推断正选择事件、选择强度、等位基因频率轨迹
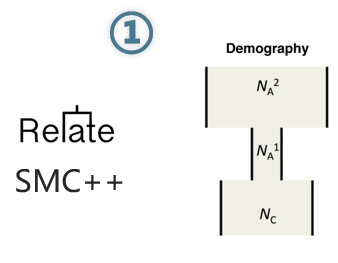
第一步:估计研究对象的群体历史。
选择事件和群体历史事件(如群体的扩张和收缩)常常在基因组中留下相似的印记。为了避免这些混杂因素的干扰,需要先对研究对象的群里历史进行推测。这篇文章的研究对象是CEU人群,即有北欧和西欧祖先血统的犹他州居民人群,因此使用了前人研究的结果;然而,这一步也可以用软件进行估计,例如Relate、smc++等
第二步,训练数据的获得,这里采用的是数据模拟的方法。作者使用了discoal simulator这一模拟软件,基于群体历史参数,获得了中性区域和正选择区域的基因组模拟数据。

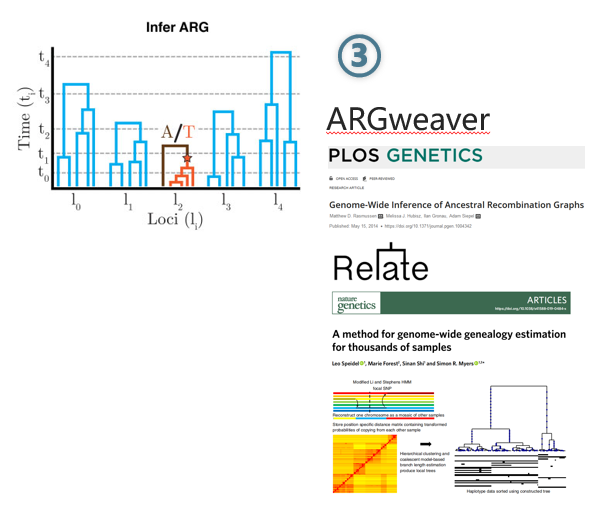
第三步,对模拟数据进行ARG的推断。本文作者推荐使用Relate这个软件做ARG推断。
这里其实有一个很有意思的点,前面在介绍作者的时候提到过,本文通讯作者Adam Siepel实验室开发过多款软件,其中就有一个名叫ARGweaver的软件是专门做ARG推断的。但是此处作者却使用了另一个软件Relate,实在有些奇怪。
Relate是牛津大学的Leo Speidel和Simon R. Myers开发的一款基于隐马尔科夫链的ARG推断工具,据作者宣称Relate可以处理几千甚至上万级别的基因组数据,并且速度比ARGweaver快得多,或许这就是SIA方法不用ARGweaver却用Relate的原因。
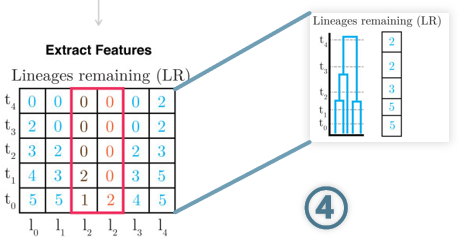
第四步,进行特征提取。
如图所示,特征提取方法如下:将树分成100个离散的时间点,这些时间点以指数函数均匀分布在树上,然后统计每个时间点上的祖先谱系数量和衍生谱系数量,这样就构成了一个100维的特征向量。为了增强泛化能力,SIA方法还会考虑上下游各两个侧翼位点,因此最终获得的是一个600维的向量。
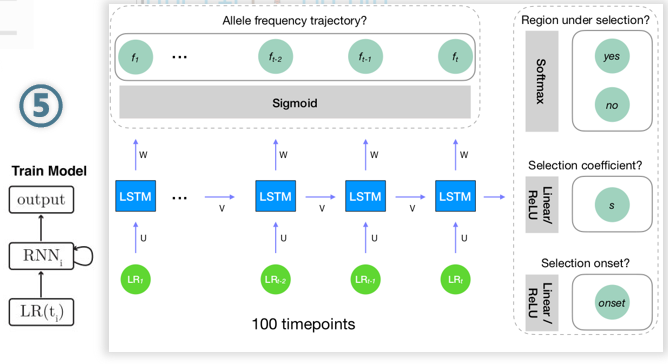
第五步,基于上述数据进行神经网络的训练,并将训练好的模型用于真实数据,从而推断正选择事件、选择强度、等位基因频率轨迹。
由于LSTM的输入是ARG树上不同时间点的谱系数量,这在一定程度上可以反映ARG树的拓扑结构,因此训练出的模型可以学会用ARG树的拓扑结构预测正选择。
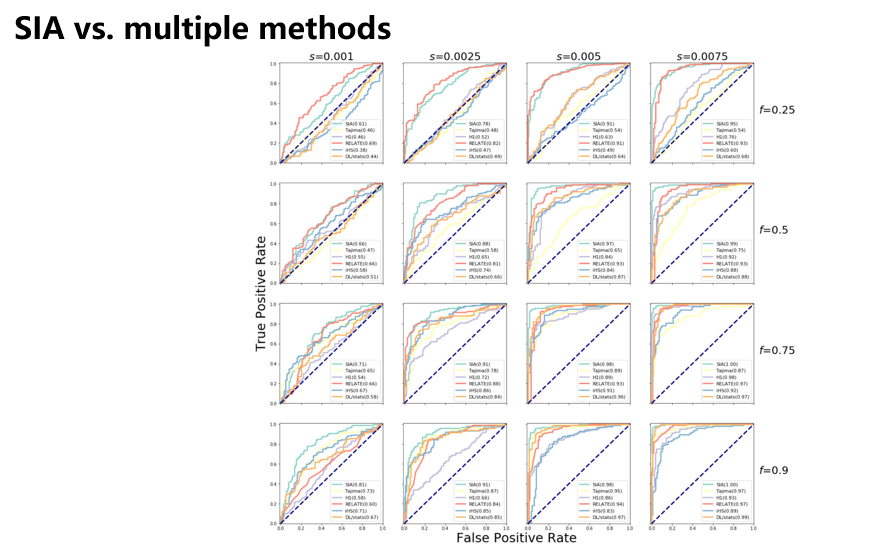
与其他方法的比较
作者在不同的选择强度参数(s)和等位基因频率参数(f)下比较了SIA方法和其他模型的性能(包括Tajima’s D, iHS, RELATE等)。
当选择压力更强【右】、DAF更高【下】时,所有方法的效果普遍都很好。
但是,如果选择压力更弱一点【左】、DAF更低一点【上】时,则SIA表现最好。
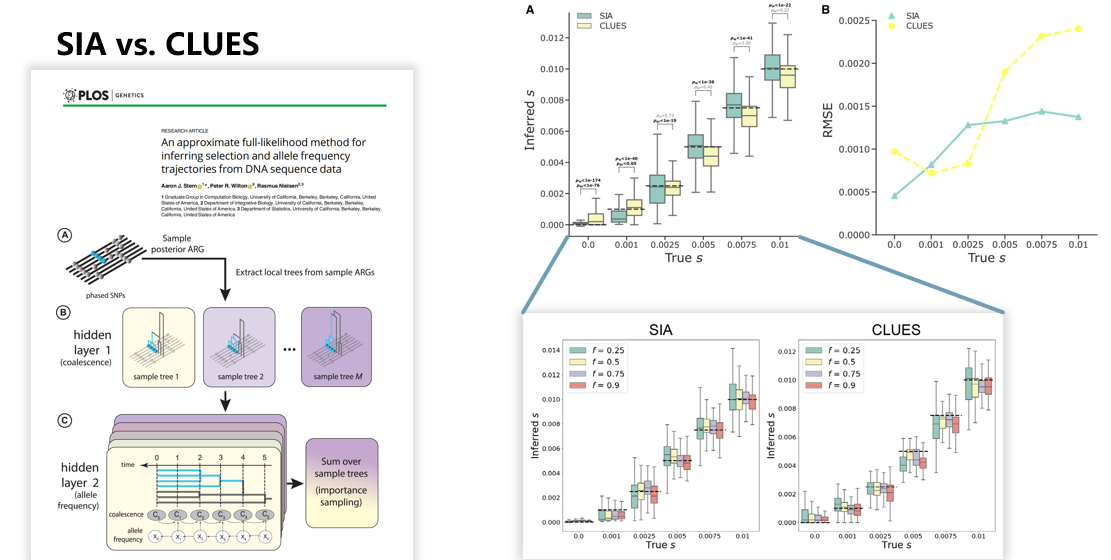
作者还在有真实ARG树的数据上比较了SIA方法和CLUES方法,以排除ARG推断过程中的误差对结果的干扰。
CLUES也是一种基于ARG的正选择推断工具,由加州大学伯克利分校的Aaron J. Stern(亚伦J.斯特恩)等人开发,于2019年发表于PLOS genetics杂志上,其文献和原理如下图的左图所示。与SIA不同,CLUES使用马尔科夫链蒙特卡洛模型(MCMC)进行建模,这是一种无监督学习算法,因此不需要预先生成模拟数据和训练,这排除了模拟数据过程中可能产生的偏差;然而,CLUES只考虑中心位点的ARG树,而不考虑侧翼树,因此在某些情况下预测结果可能存在偏差。
本文的作者在同一个数据集上比较了SIA方法和CLUES方法,结果如右图所示。
CLUES与SIA表现相似,但是在中性区域(S=0)处对选择强度(S)有些高估,在选择压力较高的区域对选择强度(S)有些低估,这在S=0和S=0.01的情况下尤为明显。
此外,SIA在估计选择强度(S)时的错误率比CLUES低,这可能是SIA考虑了侧翼序列带来的好处。
讨论
首先是SIA与CLUES的对比。
| SIA | CLUES | |
|---|---|---|
| 算法 | LSTM,是一种监督学习 | HMM,是一种无监督学习 |
| 训练集 | 使用模拟软件生成,对参数敏感 | 不需要 |
| 输入 | Focal site及上下游位点的ARG | 只考虑focal site的ARG |
| 各自优势 | 稳健性更强,对推断的ARG所包含的偏差更加不敏感 | 不会受到训练集的分布偏差带来的影响 |
然后是以SIA、CLUES等方法为代表的基于ARG树和机器学习算法的新方法与传统方法的比较。
传统方法主要指的是基于等位基因频率谱(SFS)等信息汇总得到的统计量,例如Tajima’s D,Fay and Wu’s H,Fu and Li test等,这些传统方法的优点在于数学原理简单,且计算量相对较小,可以更快速的获得检测结果。
相比于传统方法,基于ARG的诸多方法使用了祖先重组图(ARG)的数据,这使得计算过程更多地考虑到了群体的基因组特征,因此更加精准。当然这样的精确性是有代价的,SIA一类的方法的算法更复杂,需要的计算量也更大。
| 传统方法 | SIA(以及类似方法) | |
|---|---|---|
| 数学基础 | 汇总统计量、等位基因频率谱等 | ARG |
| 算法 | 各个方法都有自己的算法,但是数学表达式都比较直观 | 深度神经网络(LSTM) |
| 优点 | 速度快,原理简单 | 尽可能多地考虑到了基因组特征,更加精准 |
| 缺点 | 不够精准;在计算汇总统计量时丢失了许多基因组所携带的信息 | 算法比较复杂 |
作者也反思了SIA目前存在的一些问题:
- (1)SIA的输入是一系列离散时间点上ARG树的谱系数量,这样的向量并不能精确表示整棵树
- (2)SIA依赖上游ARG树的构建方法,因此会受到ARG构建方法的影响。这也是作者推荐用Relate建树的原因
- (3)SIA需要用模拟数据训练,模拟数据的生成参数对于训练结果有影响。因此需要先估计群体历史,再用群体历史参数生成训练集
但即使这样,SIA依然是一个非常优秀的正选择推断方法,可以在正选择检测中发挥重要作用。