Linux服务器维护零碎知识点整理
如题。
原先的服务器快到期了,因此这周初新购进一台华为云的服务器。在配置服务器的时候,顺带温习了一下这些知识点。
虚拟内存的分配与开启/关闭操作
所谓虚拟内存,就是把硬盘上面的一部分空间当作内存来用,通过牺牲硬盘的一部分读写性能换取内存的提升。在Windows系统上,这样的技术被称为“分页文件”,而在Linux/Unix上,这样的技术被称为“交换文件”
1. 创建虚拟内存文件(交换文件)
使用下面的指令,可以在当前目录下创建一个名为swapfile的交换文件。其中,dd指令用来将指令写入磁盘上的一片物理空间,bs=1G count=6 代表创建6个1GB大小的块,也就是这个交换文件大小为6GB(可以提供大约6GB的虚拟内存空间)。虚拟内存的大小设置为服务器物理内存大小的1-2倍比较合适,例如2GB的内存可以配4GB的虚拟内存,8GB的内存可以配8-16GB的虚拟内存。
1 | sudo dd if=/dev/zero of=./swapfile bs=1G count=6 |
上述指令的输出:
1 | /$ sudo dd if=/dev/zero of=./swapfile bs=1G count=6 |
2. 将文件设置为交换文件
mkswap 指令可以将指定的文件设置为Linux交换文件。具体而言,指令如下:
1 | sudo mkswap swapfile |
上述指令的输出:
1 | /$ sudo mkswap swapfile |
请注意,将一个文件设置为交换文件不代表开启了服务器的交换文件功能,还需要进一步设置。
3. 启用交换文件(临时)
swapon和swapoff这两个指令用于开启和关闭服务器系统的交换文件功能。具体而言,指令如下:
1 | sudo swapon swapfile |
可以使用free指令查看开启这一功能前后的内存变化情况:
1 | /$ free -h |
4. 启用交换文件(永久有效)
在/etc/fstab 文件中添加下面这样一行内容:
1 | /swapfile swap swap defaults 0 0 |
其中,第一个参数代表交换文件的实际存储位置,此处的示例是/swapfile,在实际使用中请根据实际情况进行设置。另外5个参数的内容就按上述设置即可。
完成这一设置以后,重启系统,则交换文件即可生效。
通过.htaccess 文件控制Apache web 服务器文件的访问权限
.htaccess 文件是 Apache web 服务器中用于配置特定目录的文件。它允许开发者在目录级别上覆盖主配置文件中的一些配置,并可以用于设置权限、重定向、缓存控制等。
以下是一个简单的 .htaccess 文件的示例,以说明其中的一些基本概念:
1 | <Files "sensitive-file.txt"> |
上述示例包含了几个部分:
<Files>部分:这部分指定了对sensitive-file.txt文件的访问控制。在这个例子中,对这个文件的访问被拒绝。<FilesMatch>部分:这里使用正则表达式指定了对以.xml或.txt结尾的文件的访问控制。在这个例子中,对这些文件的访问是允许的。<IfModule>部分:这是一个条件块,只有在 Apache 服务器加载了mod_rewrite模块时才会执行其中的指令。在这个例子中,启用了 URL 重写规则,将请求重定向到index.php。ErrorDocument指令:这部分定义了当发生404错误时,将用户重定向到/errors/not-found.html页面。
这只是一个简单的示例,.htaccess 文件还可以包含其他指令,用于设置许多不同的配置选项。
必须要注意的是,仅仅对.htaccess文件进行设置并不能保证这些访问权限设置能够生效。还需要在web服务器程序的配置文件中启用对访问权限的覆盖功能,才可以生效。
web服务器程序的配置文件路径,根据服务器上具体使用的web服务程序的不同而有所不同,例如apache2的配置文件路径是/etc/apache2/apache2.conf,而httpd的配置文件路径是 /etc/httpd/conf/httpd.conf 。
以apache2为例。假设我们要使用.htaccess文件进行访问权限保护的网页存储在/var/www/html路径下面,那么在apache2配置文件里面,我们需要加上下面这几行内容:
1 | <Directory /var/www/html> |
之后,我们需要重启一下web服务程序:
1 | sudo service apache2 restart |
这样,就可以通过.htaccess进行访问权限控制了。
补充:apache2服务器开启多个端口
在/etc/apache2/sites-available/000-default.conf文件当中添加绑定到端口的网站根目录,例如:
1 | <VirtualHost *:81> |
在<VirtualHost *:81>里设置要开启的端口号,本例子中的端口号是81。
其中的DocumentRoot对应字段更改为网站根目录的位置。
同时,在/etc/apache2/ports.conf 文件中添加对新增端口的监听:
1 | Listen 81 |
在完成这些设置以后,重启apache2服务器,既可完成对新端口的访问。(PS:如果依然无法访问,请去云服务器提供商的控制台看一看,是否在网络安全组中未能放行对应的端口)
Linux的cron定时任务设置与踩坑
crond是Linux上一个用于运行定时任务的守护进程。它的配置文件路径是/etc/crontab,里面的内容大概长这个样子:
1 | # /etc/crontab: system-wide crontab |
每分钟,crond程序都会检查这个配置文件的更新,并在定时任务到时间时执行任务。上述配置文件中说明了添加定时任务的方法:在这个文件中新增一行内容,这一行内容需要包含任务的执行时间、以什么用户身份执行这个任务,以及要执行的任务脚本。
例如,假设我们在/home/warrenz/下有一个爬虫程序spyder.py,需要每天上午9点整准时以warrenz的用户身份执行,那么就需要向crontab中添加下面这样的内容:
1 | 0 9 * * * warrenz /home/warrenz/spyder.py |
前五个数字分别代表定时任务的执行时间(分钟、小时、每个月的第几天、月份、每个星期的第几天),可以使用通配符*代表任何时间都执行。第六个参数是用户名,第七个参数是要执行的脚本内容或文件路径,必须使用完整路径。
另外,crond在执行任务时无法处理标准输入输出(也就是通常我们写程序时的print()那一堆操作)。因此,可以放在定时任务里执行的程序不应该有标准输入输出,即使有,也应该使用Linux输出重定向符号>或>>写入到一个具体文件当中。
crond执行任务没有输出,那么如何确定任务是否执行成功了呢?其中一种方法是查询cron服务的状态:
1 | sudo service cron status |
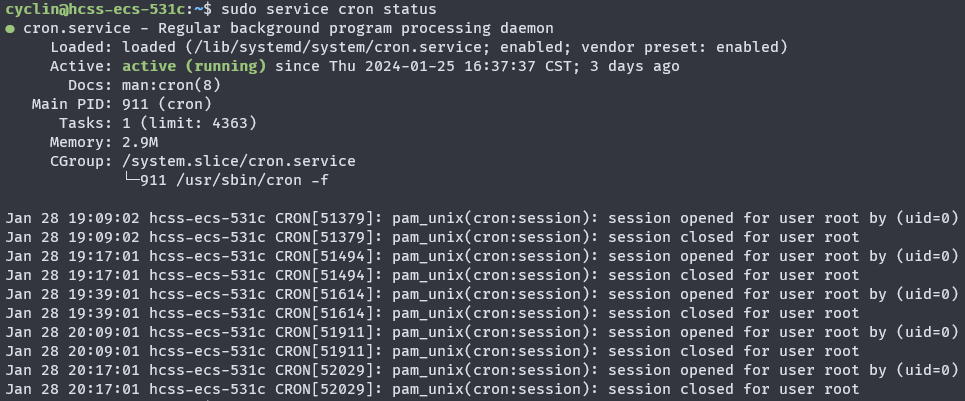
如果这里出现了异常的报错或异常的会话关闭(”session closed“),则有可能是任务出错。(正常情况下执行完任务也会session closed,但这里是可以看crond的任务执行时间的,如果一个任务预估需要三五分钟跑完,结果crond只花了不到一秒就session closed了,那很有可能是程序报错了)
经过本人实践,造成crond定时任务出错的原因大概包括下面这样一些:
- python程序调用了未安装的模块(注意,如果使用root用户进行定时任务执行,则一些模块需要使用
sudo pip或sudo conda进行全局安装)。 - 程序中有标准输入输出且未进行文件重定向。
- 使用非root用户身份执行定时任务时,没有给文件或目录相应的访问权限。
- 软件或程序本身的问题。
按照上面的思路逐个情况排查,最终可以找到原因。