HuggingFace在线大模型部署方法
【点击查看更多】
1. 背景
Hugging Face(抱抱脸🤗)是一家美国公司,专门开发用于构建机器学习应用的工具。Hugging Face成立于2016年,最初是一家开发面向青少年的聊天机器人应用程序的公司。在将聊天机器人模型开源后,这家公司转变方向,专注于成为一个机器学习平台。
目前,Hugging Face的主要服务方向有两个,分别是 Transformers模型库、Hugging Face Hub托管平台。Transformer模型是一种采用自注意力机制的深度学习模型,由谷歌在2017年推出,已逐步取代长短期记忆(LSTM)等RNN模型成为了NLP问题的首选模型,而Hugging Face所开发和维护的 Transformers模型库 则是一个模型实现,通过对三大开源机器学习库 Flax、PyTorch 或 TensorFlow 的封装,可以帮助开发者快速搭建和分享基于Transformer模型的AI工具(更多信息可以参考 官方中文文档 )。
此外,Hugging Face生态系统还包括用于其他任务的库,例如数据集处理(“Datasets”),模型评估(“Evaluate”),模拟(“Simulate”),以及机器学习演示(“Gradio”)。
2. Hugging Face模型任务列表
到目前为止,在Hugging Face Hub上托管的模型数量已经超过了四十万个。包括Meta公司开源的大语言模型LLama及其一众衍生模型都托管于此。此外,除了一众大语言模型,Hugging Face Hub还托管了图像识别、图片生成、文字转语音工具等模型。
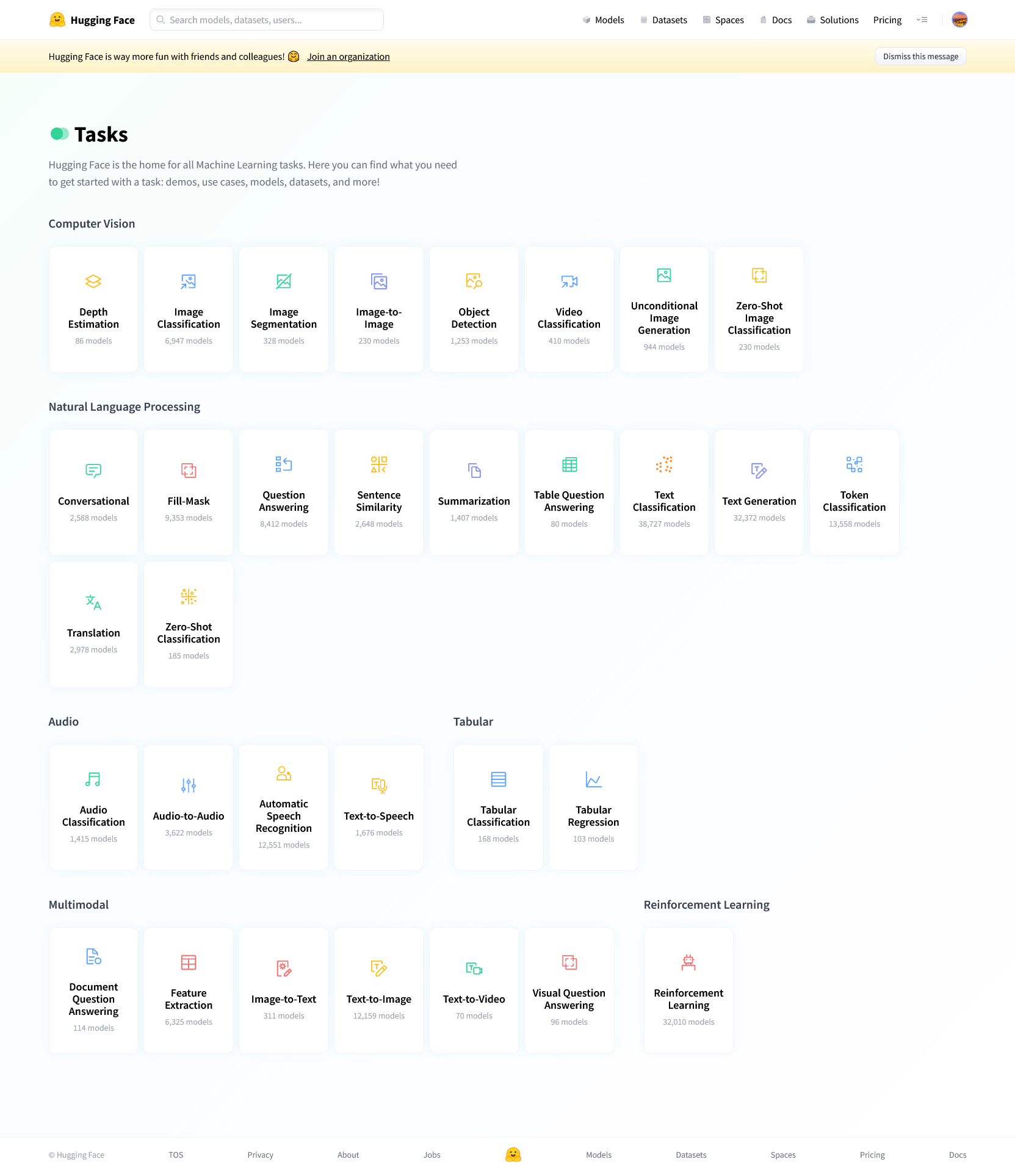
如下图所示,在Hugging Face Hub的 Tasks 页面上列出了所有模型可以实现的任务。这些任务包括图像识别和处理、自然语言处理(对话、填空、相似性计算、文字分类、翻译等等)、语音识别和文字转语音等,几乎涵盖了日常生活中AI工具所能涵盖到的方方面面。
下面举一些比较知名的模型,以及一些个人感觉有趣实用的模型:
- 图生图模型stable-diffusion-xl-refiner-1.0:https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0
- AIGC图像编辑器InstructPix2Pix:https://huggingface.co/timbrooks/instruct-pix2pix
- Meta开源对话模型LLama:https://huggingface.co/meta-llama
- 微软开源生物医药文献大模型BioGPT:https://huggingface.co/microsoft/BioGPT-Large
- 赫尔辛基大学文本翻译模型:https://huggingface.co/Helsinki-NLP/opus-mt-zh-en
- openai语音识别模型whisper:https://huggingface.co/openai/whisper-large-v2
- 微软文字转语音工具:https://huggingface.co/microsoft/speecht5_tts
3. 在线运行Hugging Face上托管的模型
得益于英特尔公司的合作,Hugging Face提供了免费的 基于 CPU 的推理解决方案(Intel Xeon 3rd Gen Scalable cpu) 。对于一些不算太大的模型,可以通过这一功能在线试用这些模型。在这一部分中,我们将介绍使用方法:
3.1 使用推理API窗口在线运行
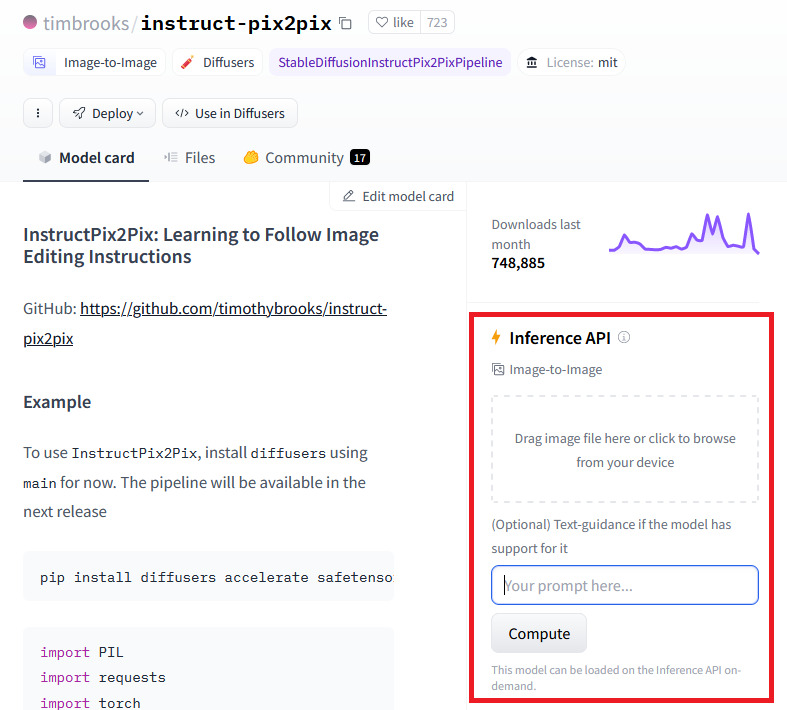
以AIGC图像编辑器InstructPix2Pix为例。打开这一模型的主页以后,可以在页面右侧看到 “Inference API” 窗口(如下图的红框所示)。我们可以在这个窗口中在线试用这一模型。
例如,在图片输入框中上传图片(随手拍摄的街景),再在文本框中输入提示词(“what if it looks when the left white building is a port and the right road is a river”,如果左边的白色大楼是个港口而右边的马路是条河,图片会长什么样子),点击“compute”开始在线推理,大约几秒钟就会得到下面的输出图片:
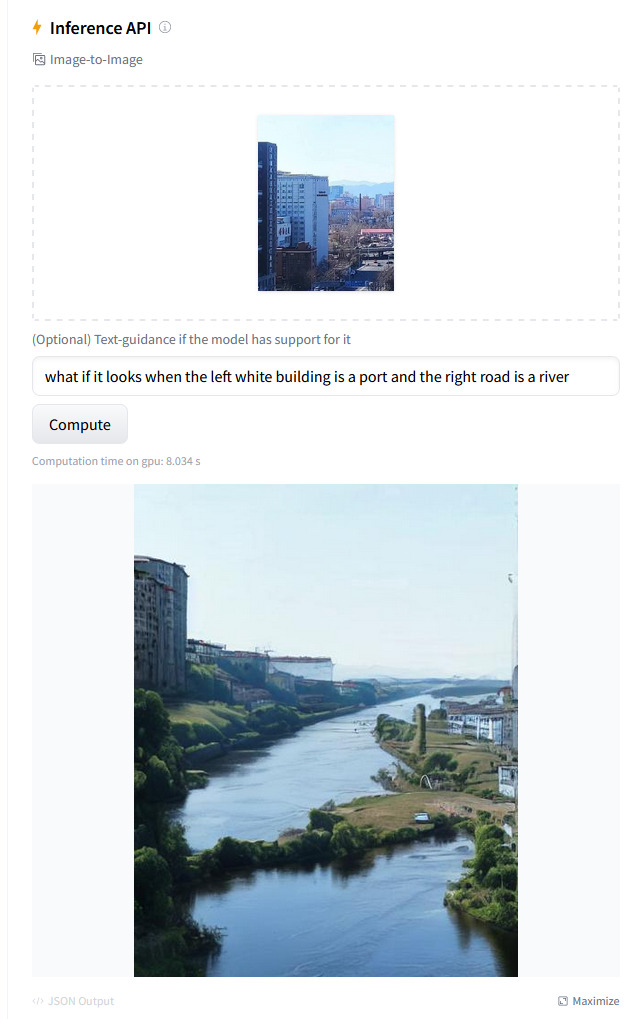
还别说,这个在线推理效果真的很不错,生成的图片比原图还壮观一点有木有!
3.2 在程序中调用在线推理API
在这一部分中,我们以 BioGPT-Large 为例进行讲述。
首先注册并登录Hugging Face,然后在账号设置页面找到tokens设置( https://huggingface.co/settings/tokens ),在此处点击“New token”按钮添加token(如果仅仅只是想跑大模型,而不进行模型训练或微调,token的角色(role)选择read即可)。
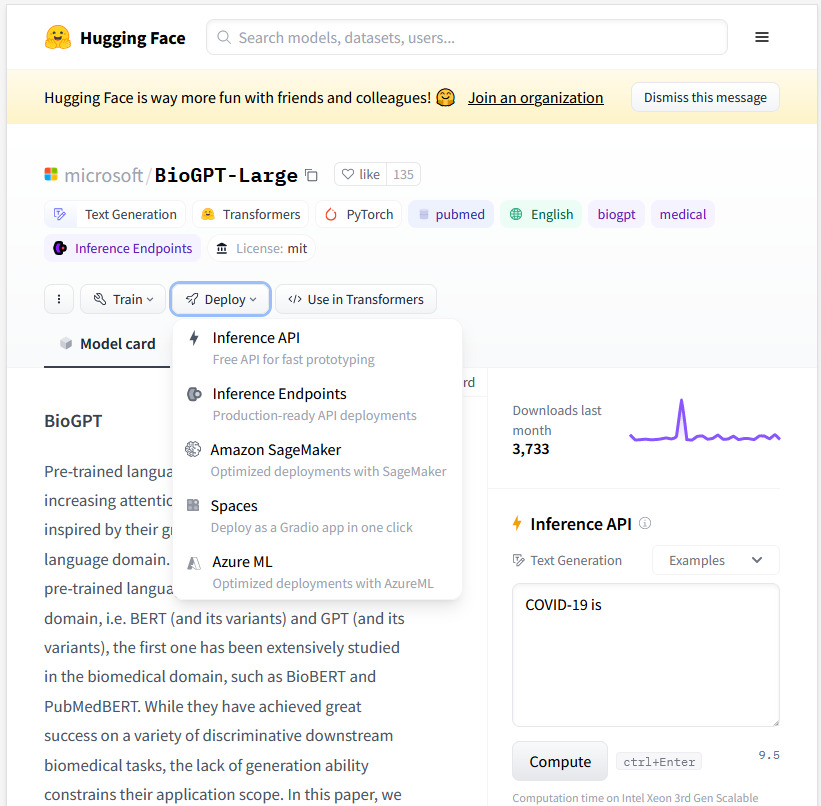
之后打开我们想在线推理的模型,点击Deploy按钮,选择Inference API(如下图),此时会弹出一个窗口。
复制弹出窗口的代码,并将其中的token设置(request标头中的Authorization字段)换成上面我们刚刚获得的token即可(如下图)。
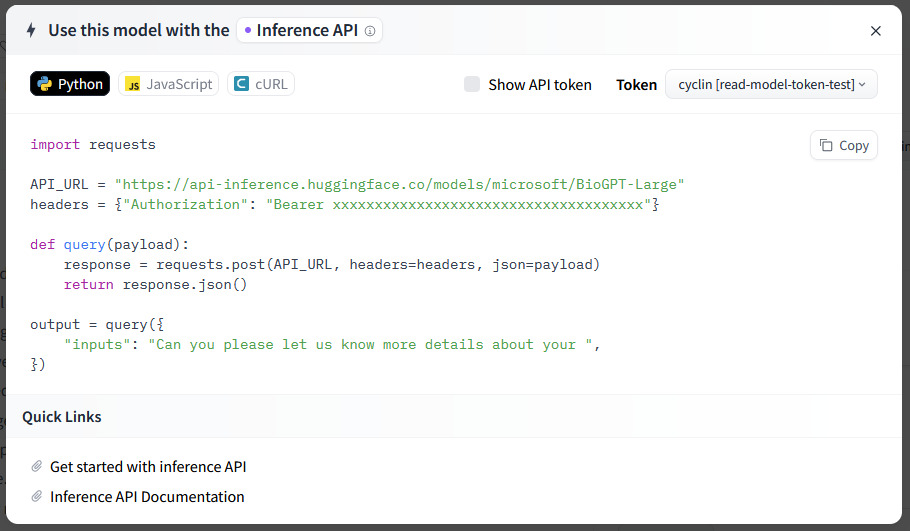
以 BioGPT-Large 的API为例,我们复制得到的调用代码如下:
1 | import requests |
为了得到打印输出,我们在上述代码的最后再添加一行代码(这段代码Hugging Face上不会提供,需要自己添加):
1 | print(output) |
运行结果如下:
1 | [{'generated_text': 'Can you please let us know more details about your case? < / FREETEXT > < / TITLE >'}] |
既然有了API,我们可以做的事情就变多了。例如,我们可以对程序进行改造,获得一个可以循环对话的模型:
1 | import requests |
输出:
1 | (BioGPT) >>> covid-19 is |
3.3 其他注意事项:
- (1)单个账号的在线运行大模型似乎有使用数量的限制(参考 https://huggingface.co/docs/api-inference/faq );
- (2)不是所有在huggingFace上托管的模型都可以在线运行,例如chatGLM、llama等就无法使用这一功能。
4. 将Hugging Face Hub上托管的大模型下载到本地,并离线运行
如题。既然Hugging Face Hub能够托管大模型,那么一定可以下载大模型。半个月前我在博客上发表的文章 《一个PC端的离线翻译程序》 就是示例。
本文则会以另一个模型,微软 speecht5_tts文字转语音工具为例进行讲述。这个模型当然可以在线部署和运行,不过此处讲述如何本地运行。
Hugging Face Hub上的大多数模型,依赖于Transformer架构。因此,下面这些python依赖库必不可少:
对于 speecht5_tts ,还需要安装如下python模块:
datasets用于加载必要的数据集,soundfile则是音频数据处理工具。
此外,如果之前安装过 transformers 模块,那么也需要检查一下是否是最新版,如果不是最新版的话需要进行升级,否则运行下文中的代码可能会出问题。升级指令如下:
1 | pip install --upgrade transformers |
我们可以直接使用文档给出的代码进行程序的运行
1 | from transformers import pipeline |
第一次运行会从Hugging Face Hub上加载模型(大概几百MB,这一过程中需要科学上网)。之后,后面的代码会运行,由此可以得到一段音频speech.wav,里面是我们想要转语音的文本 "Hello, my dog is cooler than you!" 的内容。
如果想要对其他内容进行文本转语音的朗读,可以改写上面代码的speech = synthesiser("Hello, my dog is cooler than you!", forward_params={"speaker_embeddings": speaker_embedding})这一行内容。或者,对模型进一步封装:
1 | #!python |
改写text=后面的内容即可。输出文件依然是speech.wav。