Attention机制、Transformer与GPT(阅读笔记)
之前读到了一篇使用LSTM检测正选择的算法文章,对LSTM以及衍生出的Transformer很感兴趣,于是花了一晚上了解了一下。下面是一些参考链接和笔记,记得不好,权当抛砖引玉了。
参考:
- 《从word2vec开始,说下GPT庞大的家族系谱》
- 《后GPT书:从GPT-3开始,续写Transformer庞大家族系谱》
- 《论文解读:Attention is All you need - 习翔宇的文章 - 知乎》
- 《详解Transformer (Attention Is All You Need) - 大师兄的文章 - 知乎》
- 《详解残差网络》(残差网络是一种将不同层之间的神经元连接起来、跳过一些中间层的模型,其可以应对深层神经网络随着层数增多而出现的退化(degradation)问题)
- The Illustrated Transformer
代码实现与练习(pytorch):
2013年最早提出了attention机制( https://arxiv.org/abs/1409.0473 ),当时的attention机制是与RNN/LSTM一起工作的。
2017年,谷歌机器翻译团队提出了Transformer算法,在这个算法中他们改进了attention,使其以self-attention的方式能够单独工作,相关论文见 Attention is All You Need( https://arxiv.org/pdf/1706.03762.pdf )。
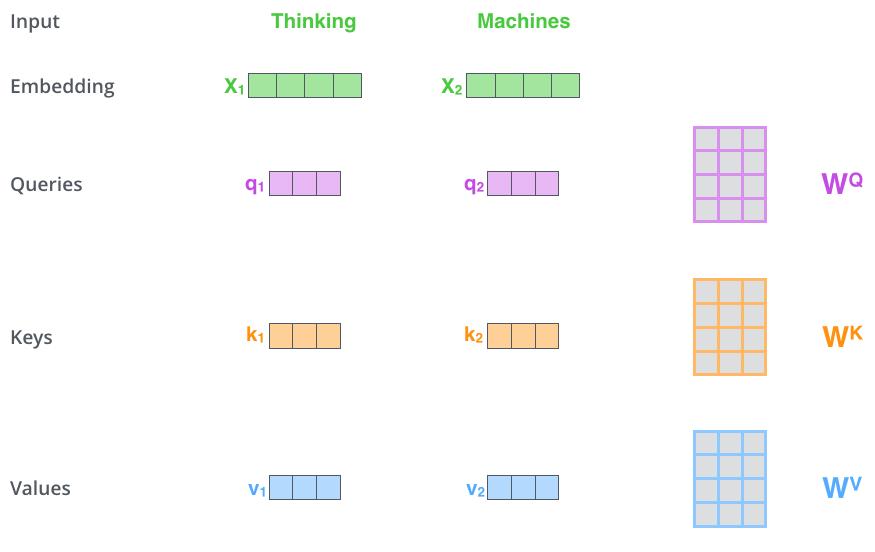
(上图展示了self-attention的计算细节。attention 机制里主要有三个向量 - key, query 和 value,分别对应公式中的三个向量K、Q和V。其实可以将 Attention 机制看作一种软寻址(Soft Addressing):Source 可以看作一个中药铺子的储物箱,储物箱里的药品由地址 Key(药品名)和值 Value(药品)组成,当前有个 Key=Query(药方)的查询,目的是取出储物箱里对应的 Value 值(药品),即 Attention 数值。通过 Query 和储物箱内元素 Key 的地址进行相似性比较来寻址,之所以说是软寻址,指的是我们不只从储物箱里面找出一中药物,而是可能从每个 Key 地址都会取出内容,取出内容的重要性(量的多少)根据 Query 和 Key 的相似性来决定,之后对 Value 进行加权求和,这样就可以取出最终的 Value 值(一副中药),也即 Attention 值。所以不少研究人员将 Attention 机制看作软寻址的一种特例,这也是非常有道理的)

(对于一个词(query),attention可以给出这个词与句子中其他词的相关性概率值)
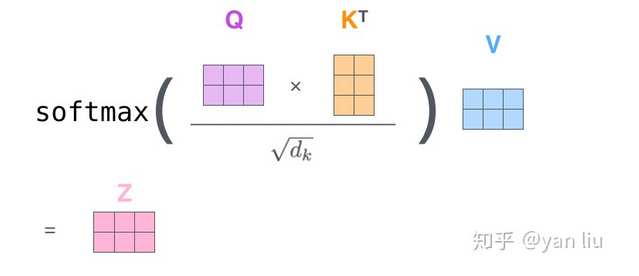
(self-attention的机制总结为公式的话就是上图。分母中的 $\sqrt{dk}$ 是为了score归一化,从而保证梯度稳定)
transformer的模型架构如下:
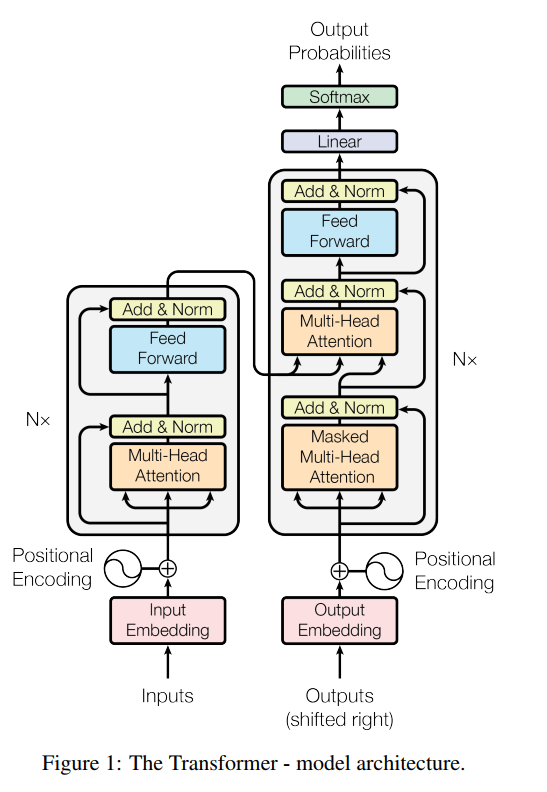
如果这个图过于复杂,可以参考下面这个简化版的卡通图(来自 http://jalammar.github.io/illustrated-transformer/ ):
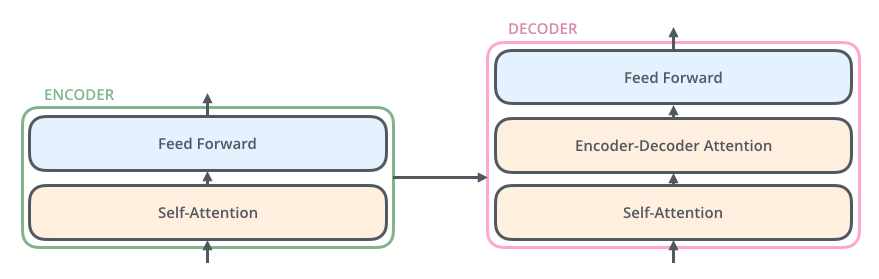
输入层被一个Encoder处理,再经过一个decoder得到输出。decoder模块比encoder模块多一个encoder-decoder attention层,这个层结合了decoder的输入和encoder的输出。
transformer最初用于机器翻译模型,后来被迁移到文本处理和图像处理上,衍生出了一大堆模型,比较出名的有语言模型GPT和BRAT,以及图像识别模型ViT。其中,ViT抛弃了传统的CNN结构,而是将图形分割成多个区域,并学习不同区域之间的关联性。
其中,GPT继承了decoder的部分,而BRAT继承了encoder的部分。BRAT在文本分类的任务上表现很好,而GPT则展现出了更加通用的能力。