R语言GO富集分析踩坑之HPO.db的安装
之前装clusterProfiler的时候遇到这个问题,死活装不上HPO.db这个依赖包,后来经过了好一番折腾终于解决了。
太长不看版: 从Github上下载 离线安装包 ,然后安装这个版本。
在完成基因差异表达分析以后,GO富集分析和KEGG富集分析常常是我们要进行的流程。
基因本体论(gene ontology)数据库 是一个致力于各种生物学数据标准化的项目,这一项目从三个GO domains上描述我们对生物学领域的了解。在每一个domains中都有大量GO term(GO术语),每一条术语包含与之对应的若干基因。
三个GO domains分别是BP(biological process),MF(molecular function),CC(cellular component)
例如,在BP domain下面有一条术语”regulation of activated T cell proliferation”(活化T细胞增殖的调控),其包含了与这一功能相关的几十个基因,例如 IGF1/IL23A/JAK3/FOXP3/CD274/ARG1/IL12RB1/SLAMF1/IL18 等。
更多的信息,可以参考知乎文章 《Gene Ontology(GO)简介与使用介绍》
GO富集分析,则是使用一些统计检验的方法,帮助我们寻找差异基因与哪些生物学通路或大分子复合物有关,从而对我们在实验中发现的差异基因进行功能注释,或用于更下游的探索。南方医科大学的余光创教授开发了clusterProfiler这一R包,可以让我们在R中方便地进行GO富集分析与可视化。然而,这个包依赖了余教授(aka. Y叔)开发的另外多款R包,包括DOSE 和 HPO.db 等,因此安装过程很漫长,很需要耐心……以及,面对安装失败时的好脾气。
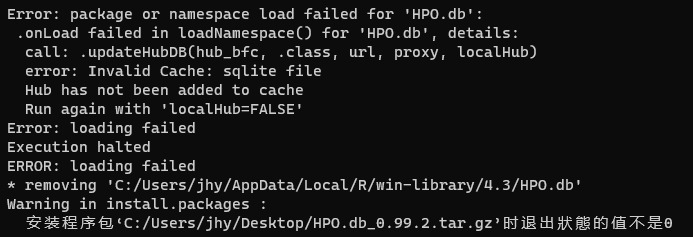
(上图:令人高血压的报错)
关于报错的原因,Y叔专门写了一篇文章来说明(《听说你的clusterProfiler装不上了?》),大意是HPO.db用到了一些云服务,需要靠AnnotationHub获取数据,如果AnnotationHub不对则有可能安装失败,也就是说安装失败的锅他们不背。
但是我们总归是要解决这个问题的,要不然科研进度又双叒叕要拖上一阵子了……
所以我们仔细看看报错是怎么报的:
1 | error: Invalid Cache: sqlite file |
报错信息提示我们加上 localHub=FALSE 再去跑一次。然而我试过了,并不行。
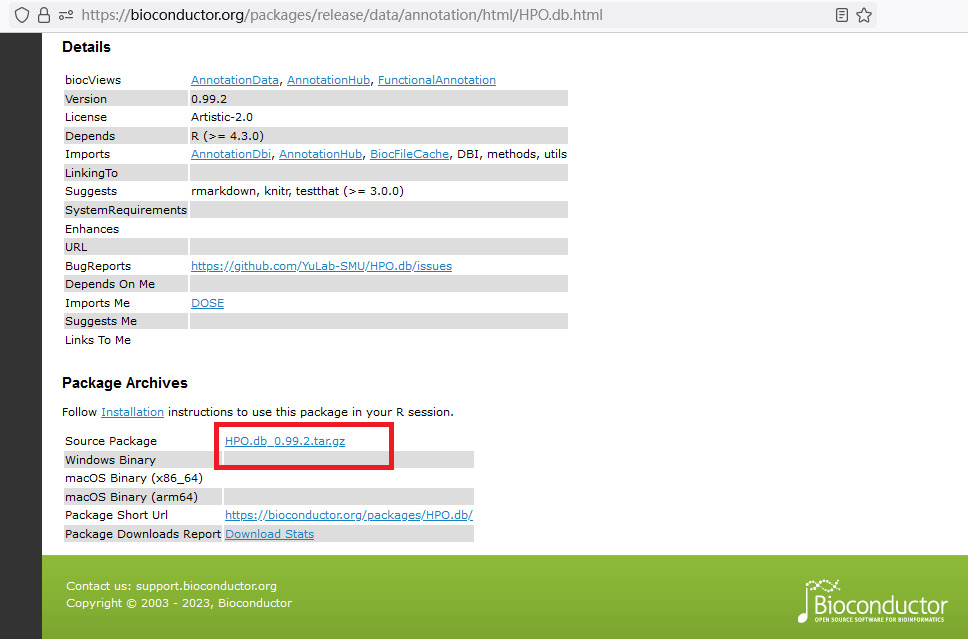
R语言的install.packages()函数提供了安装离线版本安装包的能力。既然作者说HPO.db用到了一些云服务,那么如果我们用离线包安装,会不会好一点呢?Bioconductor上确实提供了离线包的下载链接(如下图红框),我们把它下载下来安装试一下。
1 | # 这个指令用于离线安装,从本地加载安装包 |
本以为这样会好一点,结果还是收到了和刚刚一样的报错。问题出在哪儿呢?百思不得其解。
百般无奈之下,翻起了作者的Github,结果无意中看到一条这样的issue (乐:
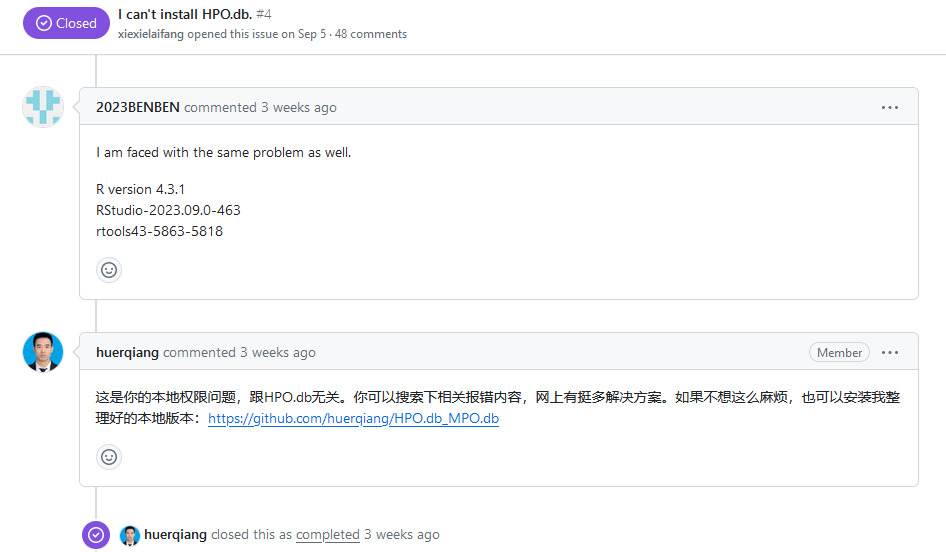
作者大概是知道HPO.db安装失败这回事,于是整理出了一个离线版的包。作者也建议我们从这个存储库(huerqiang/HPO.db_MPO.db)中下载离线版本的HPO.db包用于安装。我们先把这两个文件下载下来:
1 | git clone https://github.com/huerqiang/HPO.db_MPO.db.git |
输出:
1 | total 28M |
从文件体积上看,这个“离线安装版”确实比bioconductor版大了一圈。是离线包无疑了,希望这次能成功。
还用前面的离线安装方法试一下:
1 | # 和前面一样,第一个参数填入安装包的完整文件路径,下面的路径只是一个示范 |
输出:
1 | > install.packages("HPO.db_0.99.0.tar.gz",repos=NULL,type="source") |
如此,终于安装成功!
在这以后,安装clusterProfiler就一帆风顺多了。至于作者提到的AnnotationHub的问题,或许等未来这些依赖库更新后会解决吧。