基于RSS订阅源以及LLM的文献订阅追踪工具
如题。最近利用闲暇时间,攒了一个自动化处理RSS论文订阅源的工具(并接入了AI论文总结的功能),相关代码已开源,见 cyclinbox/RSS-report-with-AI-process 。欢迎大家试用和提意见!
一、背景
(一)想法的起因
作为一名生物医学专业的在读研究生,跟踪期刊论文发表情况是一个很重要的工作。虽然目前有各种学术公众号(例如 BioArt、生物世界、iNature)、网站(例如玻尔、中科院磐石系统)可以提供类似的功能,但是直接从源头追踪文献订阅依然有重要的意义。
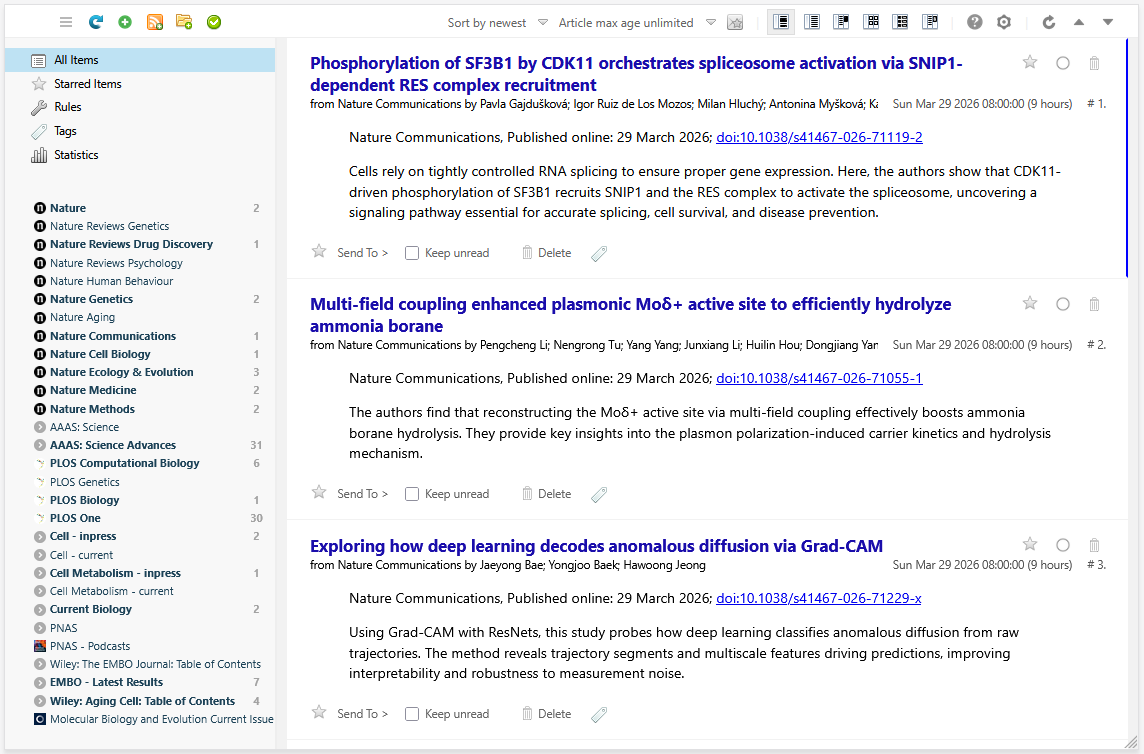
先前我使用FeedBro浏览器插件进行文献订阅追踪,每周抽出固定的时间整理和阅读新上线的论文。但是随着订阅的论文数量增多,手动处理需要耗费大量时间(如下图;每周合计刷新论文200到300篇),因此萌生了编写一个自动化处理工具的想法。
大体拆解了一下项目:要实现自动化处理,需要以下模块联动配合:
- RSS订阅源解析模块:加载和解析RSS订阅源,获取近期发表(或上线)的论文。
- 论文全文爬取模块:RSS订阅源一般只提供标题和摘要,如果想要更好的了解论文内容,最好需要获取论文全文。这里有两种思路:①获取论文的PDF版+使用MinerU之类的OCR工具转换为文本②通过网页爬虫直接获取论文的文本。考虑到工程实现的难度,我选择了思路②这种相对更为简单的思路。
- AI论文解析。这一部分其实相对简单,因为我有现成的API接口,只需要编写好prompt模板然后调用接口即可
- 报告生成。这一部分也很简单,只需要编写好markdown模板然后按实际情况填写内容即可。
- (可选)定时运行和生成报告,并发送给用户。这个模块我没有做,是因为对我来说每周定时手动运行足以满足我的需求。但其实想要实现定时也很简单,只需要拥有一台Linux服务器,然后通过设置cron定时任务+邮件接口发送即可。现在的openClaw、CoPaw之类的自动化AI agent工具也可以实现类似的功能。
这里面最为困难的是模块1和2。以至于,我其实早在去年就萌生了创建这样的一个项目的想法,却一直拖到现在才真正实现。
(二)补充一些知识点(此章节部分内容由DeepSeek生成)
什么是 RSS
RSS(Really Simple Syndication,简易信息聚合)是一种基于 XML 格式的网络内容订阅规范。您可以将它理解为一种“信息推送管道”。
- 工作原理:网站(如期刊官网、博客、新闻站)将其最新发布的内容(标题、摘要、发布日期、链接等)按照 RSS 规范格式生成一个特殊的 XML 文件(即 RSS Feed 源)。用户通过一个称为 RSS 阅读器 (如您使用的 FeedBro,或 Feedly、Inoreader 等)的工具,订阅这个 Feed 地址。
- 核心优势:RSS 阅读器会定期自动检查所有已订阅的 Feed 源,将所有网站的新内容聚合在一个界面中呈现给用户。这彻底改变了被动刷新、逐一访问网站的信息获取模式,实现了信息的主动、高效聚合。对于科研人员而言,订阅心仪期刊的 RSS Feed,是确保不会错过任何一篇新发表论文的高效方式。
- 在本项目中的作用:本项目中的 “RSS订阅源解析模块” ,其本质就是一个程序化的 RSS 阅读器。它取代了手动使用 FeedBro 等浏览器插件,自动抓取并解析您订阅的所有期刊 RSS Feed,获取最新的论文条目列表,为后续的自动化处理提供数据源头。
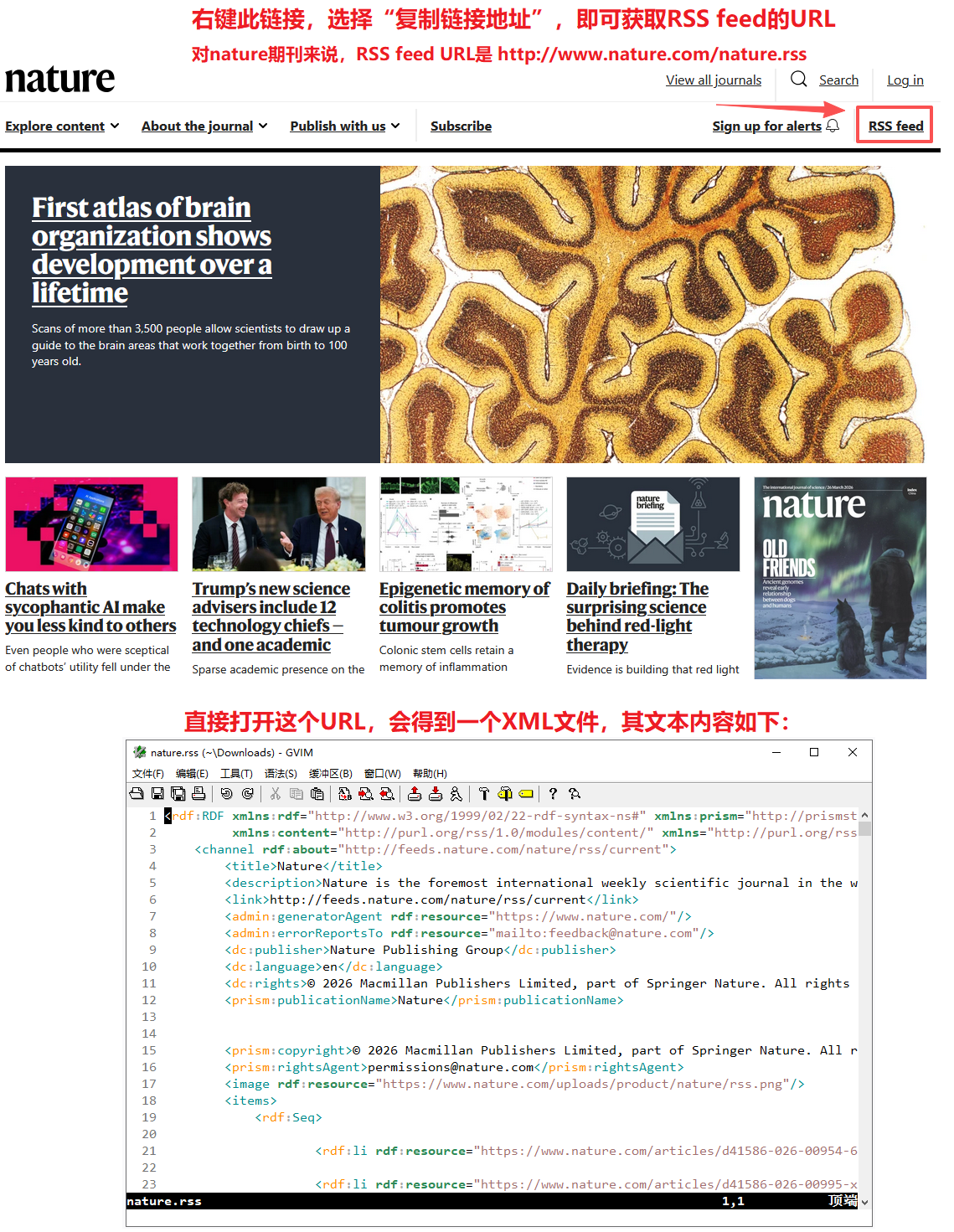
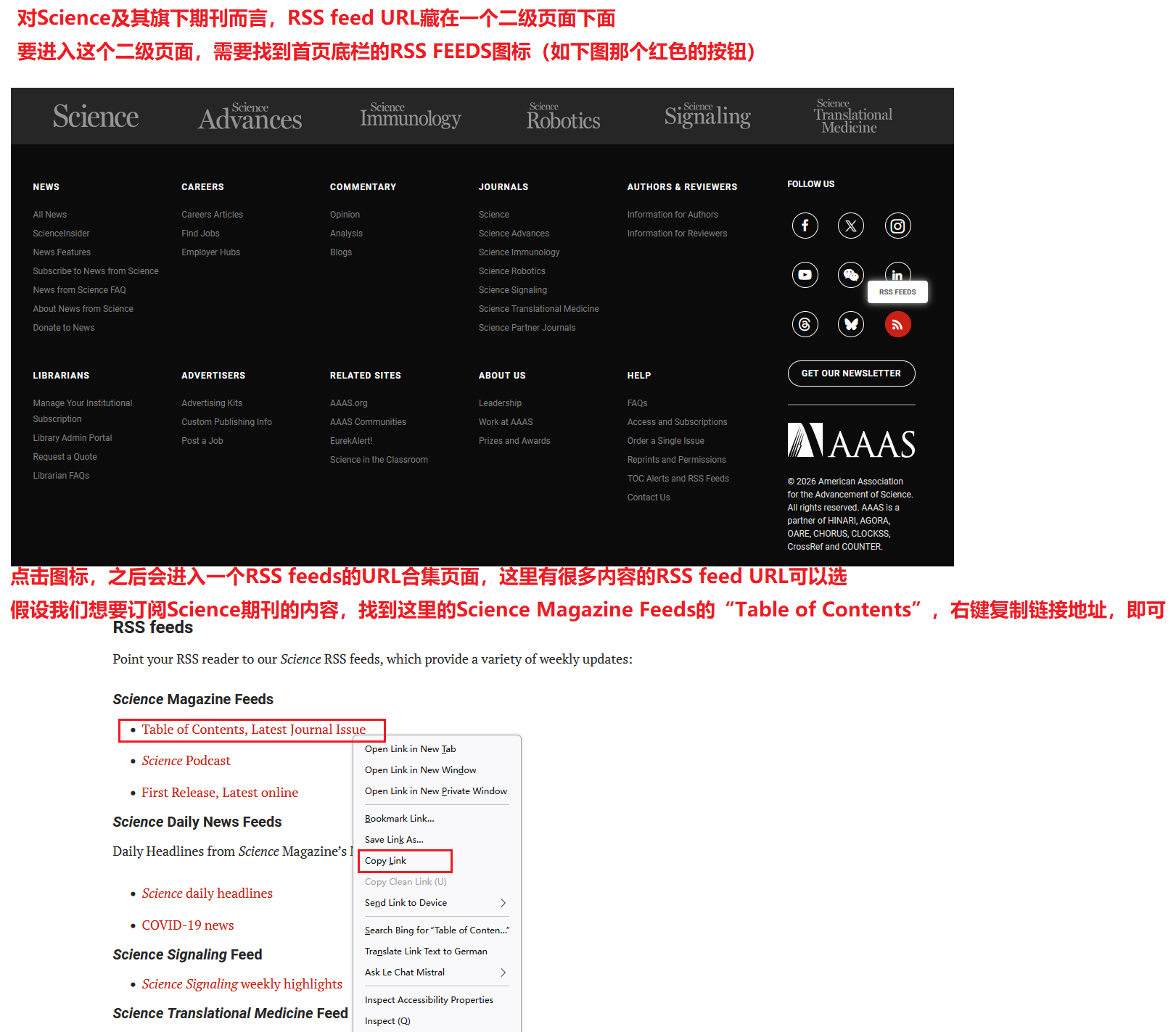
那么,如何获取一个期刊的RSS订阅链接呢?实话说这个问题很难回答,因为不同出版社对于RSS Feed的态度是不一样的。对于Nature旗下的期刊来说,RSS URL在首页右上角即可获取(如下图);Science的要稍微难找一点(同样如下图);但是另外的一些期刊,如Cell、EMBO journal等,则不太好找,需要利用搜索引擎费一番功夫才能找到(具体方法此处略)。
总之,在研一的时候,我就使用这样的方法,追踪了大概20多个期刊的RSS订阅。
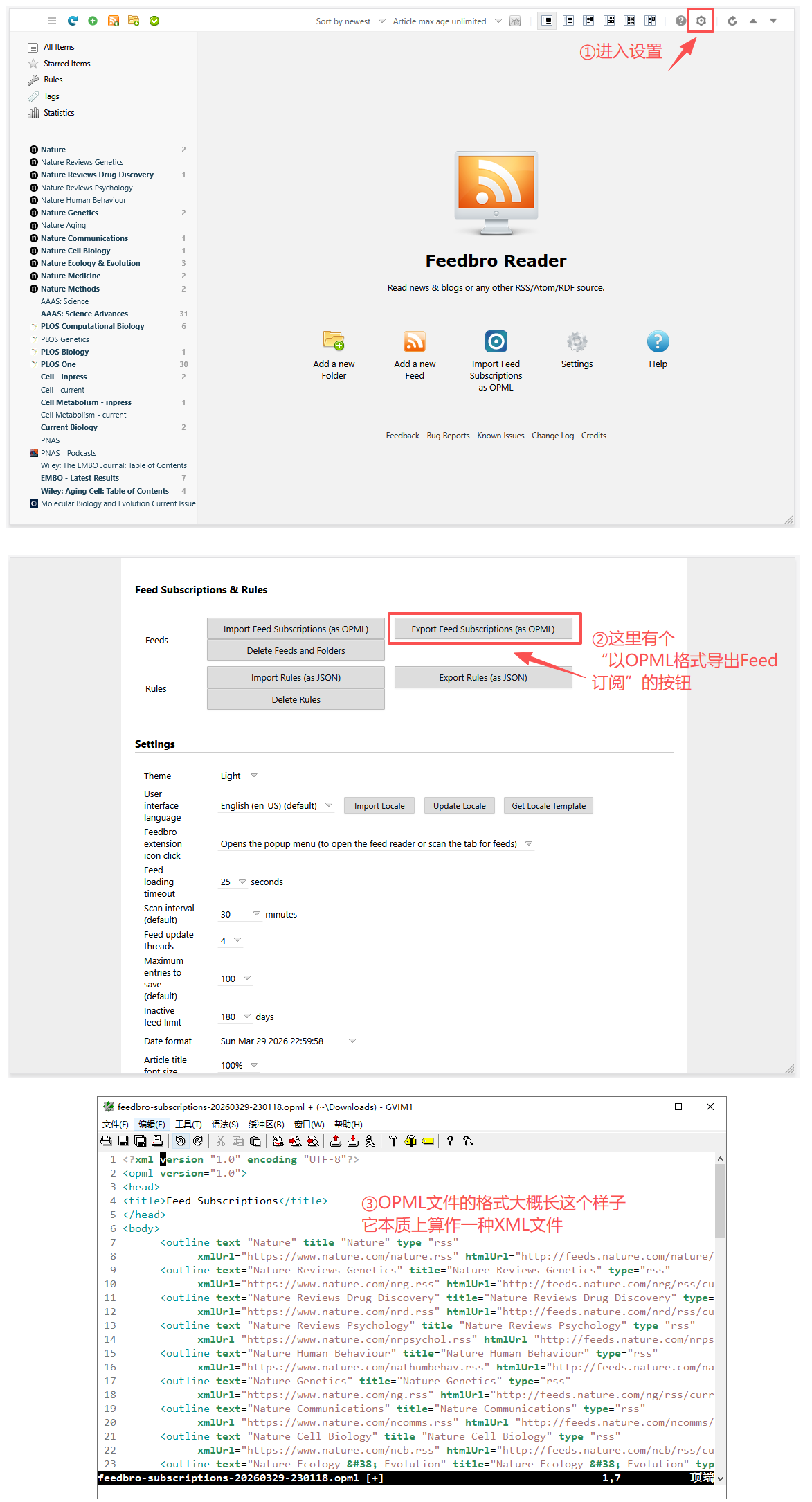
什么是 OPML
OPML(Outline Processor Markup Language,大纲处理标记语言)同样是一种基于 XML 的格式,但它主要用于描述结构化的列表或大纲,特别是在 RSS 订阅领域。
- 核心用途:RSS 订阅列表的导入和导出。几乎所有的 RSS 阅读器都支持 OPML 格式。当您在一个阅读器中管理了数十甚至上百个 RSS 订阅后,可以使用“导出为 OPML 文件”功能,将这些订阅源的地址、分类等信息完整保存为一个
.opml文件。 - 带来的便利:
- 备份与迁移:当您更换阅读器时,无需重新手动添加每一个订阅,只需导入这个 OPML 文件,所有订阅关系即可瞬间恢复。
- 共享订阅列表:您可以轻松地将自己精心整理的某一领域(如“肿瘤学顶刊”)的期刊订阅列表,通过 OPML 文件分享给同行。
- 在本项目中的意义:OPML 文件是本项目实现 “一键配置” 的关键。您可以将目前在 FeedBro 或其他阅读器中管理好的所有期刊 RSS 订阅导出为一个 OPML 文件。本项目的解析模块可以直接读取这个文件,自动加载其中包含的所有 RSS Feed 地址,从而免去了在代码中逐个手动填写订阅源的繁琐过程,极大地提升了工具的可用性和可维护性。
简单总结两者的关系:RSS Feed 是信息的“内容源”,而 OPML 文件是管理这些“内容源地址”的清单。本项目利用 OPML 文件快速载入清单,然后通过程序自动抓取清单中每个 RSS Feed 的内容,从而启动整个自动化流程。
二、项目架构
本项目基于python3编写,需要用到下面的第三方库
| 依赖项 | 解释 |
|---|---|
| pandas | 用于生成Excel版报告 |
| numpy | pandas的上一层依赖 |
| requests | 网络爬虫库,用于获取论文全文 |
| bs4 | 网页解析库,用于获取论文全文 |
| feedparser | RSS订阅源解析 |
按照前面的描述,整个项目大致可以分为四个部分。
(一)RSS订阅源解析
正如前面所介绍的那样,RSS feed URL本质是一个网址,而OPML本质是一个XML文件。因此,我们可以采取这样的两步法去处理:
- ①解析OPML文件,获取RSS feed URL列表(
parse_opml()) - ②通过requests接口解析每一个RSS feed URL,获取对应期刊的论文列表(
fetch_feed())。
1 | import xml.etree.ElementTree as ET |
(二)论文全文获取(基于网页爬虫工具)
正如前面所说,这里有两种思路:
- 获取论文的PDF版+使用MinerU之类的OCR工具转换为文本
- 通过网页爬虫直接获取论文的文本。
考虑到工程实现的难度,我选择了思路2这种相对更为简单的思路。
但是前面没有说的是,其实仅思路2,依然有两种实现思路:
- 2.1 直接爬取RSS feed中提供的论文全文网址(通常指向期刊官网,或者通过doi识别号指向 doi.org 的网址)
- 2.2 一些论文会被NCBI旗下的PMC数据库收录,因此可以通过PubMed-PMC的接口,获取论文全文。
对于2.1和2.2这两种思路,我当然也提前准备好了相应的函数库(分别封装在 libweb.py , libpubmed.py 两个文件当中),前者只需要提供一个网址URL,即可通过爬虫的方法获取网页全文;后者则需要提供论文标题,随后libpubmed.py 会向PubMed发起一次查询,并在查询结果中寻找PMC ID,如果PMC ID存在则爬取对应PMC页面的全文内容,否则返回空字符串。
当然,这两个方法都各有不足之处:
- libweb是直接解析文章链接,有时候可能会出现网页访问失败的问题,返回空字符串;或者遇到无访问权限的论文,返回的只有论文摘要。
- 而在libpubmed这边,问题也有很多。例如,PubMed会在检索时进行模糊匹配,因此当检索一些较新的、暂未收录的文章时,其检索结果可能会指向标题文本相似的其他文章;或者,某一篇文章并未被收入pmc数据库,因此pmcid解析失败、返回空字符串。
为了利用好这两个方法的优点,我在AI的帮助下实现了一个函数 calculate_credibility_score() ,这个函数可以对接口返回的论文全文进行可靠性打分,并选择可靠性最高的结果作为最终的全文。打分基于三个指标:是否为空字符串、文本总长是否够长(长文本更有可能为全文,短文本更有可能是摘要)、是否包含标题字符串(用于排除PubMed模糊匹配找错文章的问题)。
这一块的代码实现见 libweb.py , libpubmed.py,以及主程序的 process_articles() 。限于篇幅,此处不粘贴源码,读者朋友可以去本项目的GitHub仓库 cyclinbox/RSS-report-with-AI-process一探究竟。
(三)AI大模型接口调用与报告模板生成
这一部分内容相对比较简单。在代码中,我通过curl的方式,调用了阿里巴巴通义千问大模型平台的接口(后端模型是qwen3.5-flash非思考版),相关代码封装在 libqwen.py 文件当中。
当然,在调用接口时,不仅需要提供论文全文,还需要提供一份输出模板,以便AI能够按照所需格式生成报告。我的prompt模板是这样写的,其中 (-abstract-) 和 (-content-) 分别是摘要占位符和全文占位符,实际调用时需要用replace函数修改。
1 | prompt = """ |
(四)存储与输出
存储部分的逻辑是这样:先逐条处理论文(包括获取全文,以及调用AI接口解析),随后在markdown报告里使用报告模板生成对应的报告内容,并使用pandas库保存一份parquet格式的中间文件。当所有论文处理完成以后,还会额外使用pandas库生成一份xlsx文件,这份xlsx文件可以用于二次编辑和筛选。
这一部分的内容封装在主程序的主函数 main() 当中。限于篇幅,此处不粘贴完整代码。
三、完整代码展示与项目演示
见GitHub仓库 cyclinbox/RSS-report-with-AI-process。
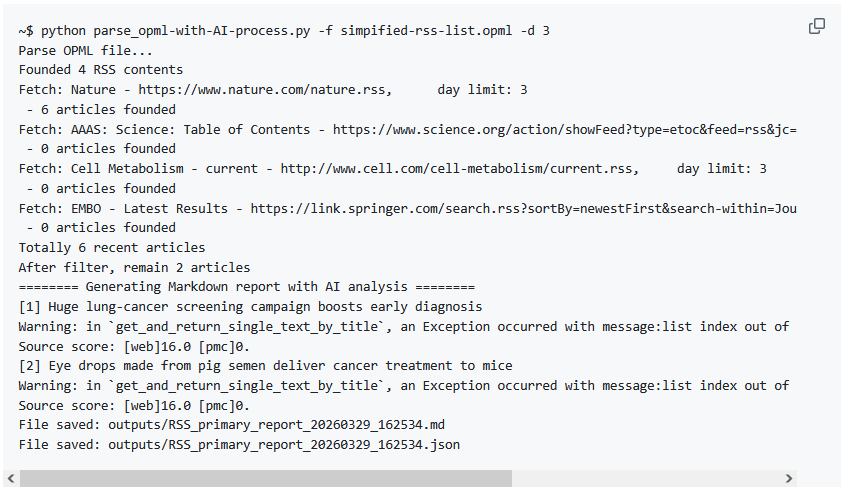
使用方法如下:
- 将本项目克隆到本地,或下载本项目根目录下的所有
.py文件并放在同一个文件夹下 - 准备一个保存有论文RSS订阅源的OPML文件。如果不确定如何生成OPML文件,可以使用本项目提供的
feed-rss-list.opml,其中包含了对CNS三大顶刊以及诸多子刊的订阅源URL。 - 命令行运行代码
python parse_opml-with-AI-process.py -f feed-rss-list.opml,这将会自动获取近8天内订阅期刊的论文列表,并根据特定主题关键词过滤文章,最终生成报告(位于outputs目录下
目前提供两个命令行参数:
1 | -d DAY_LIMIT, --day-limit DAY_LIMIT |
- 可以使用
-d参数调整论文追踪时间,默认是追踪近8天内上线的论文。 - 可以使用
-f参数调整OPML订阅源文件,默认订阅源文件是feed-rss-list.opml文件
示例输出
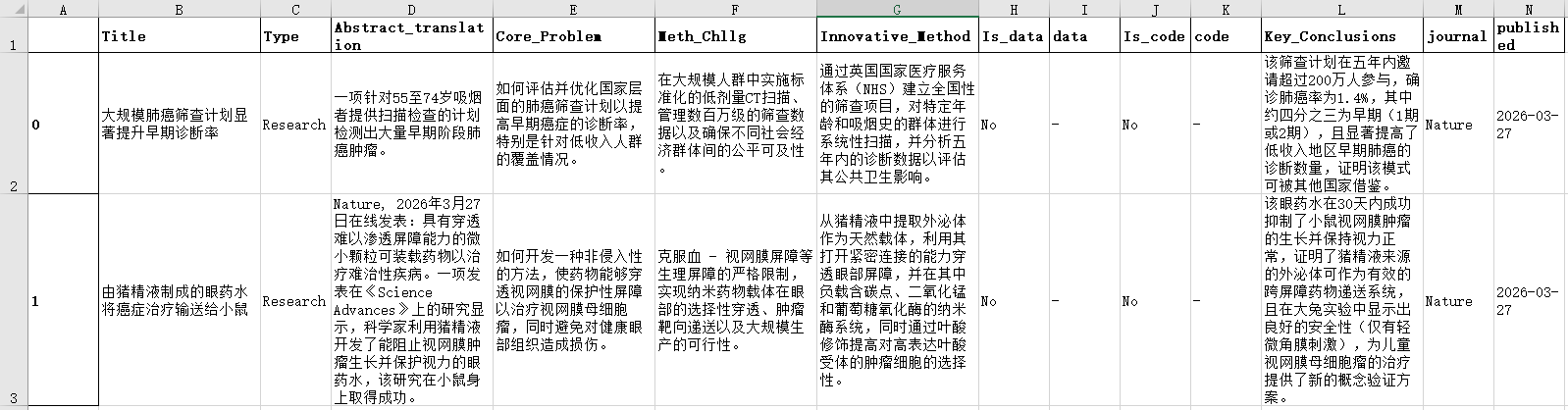
下图为XLSX报告的展示
下图为markdown报告的展示

四、局限性与未来可拓展方向
问题1:基于主题关键词的论文筛选功能:能用,但用户改起来很麻烦
目前主题关键词硬编码于代码 239-242 行(位于 main() 函数当中),相关代码如下:
1 | 220 def main(): |
目前定义了两个主题,分别是 Evolution 和 Tumor ,每个主题类别下设置有若干关键词,这些关键词用于论文主题匹配和过滤。
用户如果想要使用其他的主题,可以在此处调整 topics_keywords 的定义,编辑或添加更多的主题或主题关键词。
但是说实话,这样改起来非常麻烦。或许未来可以提供一个命令行接口,或者配置文件接口,允许用户以更方便的方式设置过滤关键词,或关闭这一功能。
问题2: 输出语言设置的问题
目前markdown格式的输出语言默认为简体中文(由system prompt硬编码,涉及的代码包括如下代码块提到的几行内容),如果用户希望使用其他语言(例如英语)输出markdown报告内容,可以修改这一部分的prompt内容,将json模板里的 “simplified Chinese” 改为其他目标语言
1 | 104 def process_single_article(title, journal, published,abstract_text, article_text): |
但是和问题1一样,就是这样改起来非常麻烦。或许未来同样可以提供一个命令行接口,或者配置文件接口,允许用户以更方便的方式设置输出语言。
问题3:易用性问题
目前要使用这个项目,需要在命令行中操作,包括克隆仓库、安装软件包、运行代码。这些操作专业性过高,会挡住许多有实际需求的用户。
未来的想法(以及反思):
- 接入openClaw(小龙虾)之类的AI agent自动化平台,比方说以一个skills的方式提供,这样用户可以通过小龙虾这个中间层调用底层代码,从而实现更智能、更自动化的操作
- 构建一个网页版应用平台,利用H5技术实现一个可视化界面,以便用户能够在浏览器中操作。(但是这样的应用平台似乎又和 玻尔、中科院磐石系统 等功能重叠了,可能吸引不到用户)
- 构建一个带有GUI界面的桌面版应用。(但是这么做的问题在于技术难度更高,同时想法2中面临的问题一样都少不了)
以上。