大模型Model Context Protocol(MCP)简介
最近需要用到这方面的知识,于是抽空学习了一下。
一、背景
自从2022年底chatGPT爆火以来,大语言模型(LLM)又经历了多年的发展。虽然LLM本质上是一个文本生成模型(用户输入一段文本,模型返回另一段文本),但其在scaling law下涌现出的智能能力,使其有潜力做许多事情——于是人们在LLM的基础上进行了许多拓展,例如AI agent这一类的应用。
LLM自身是文本模型,不具有调用外部工具的能力,但AI agent通常需要模型能够调用外部工具,以实现信息检索、运行脚本、修改用户文档、不同格式文件的读取和写入等能力。最初的解决方案是function call,即在API内部实现一个函数功能触发器,当对话触发了某个函数功能以后,函数会执行,并将运行结果放入对话上下文中。这种方法方便快捷,但也有其局限性:function call 平台依赖性强,不同 LLM 平台的 function call API 实现差异较大(如下图)。
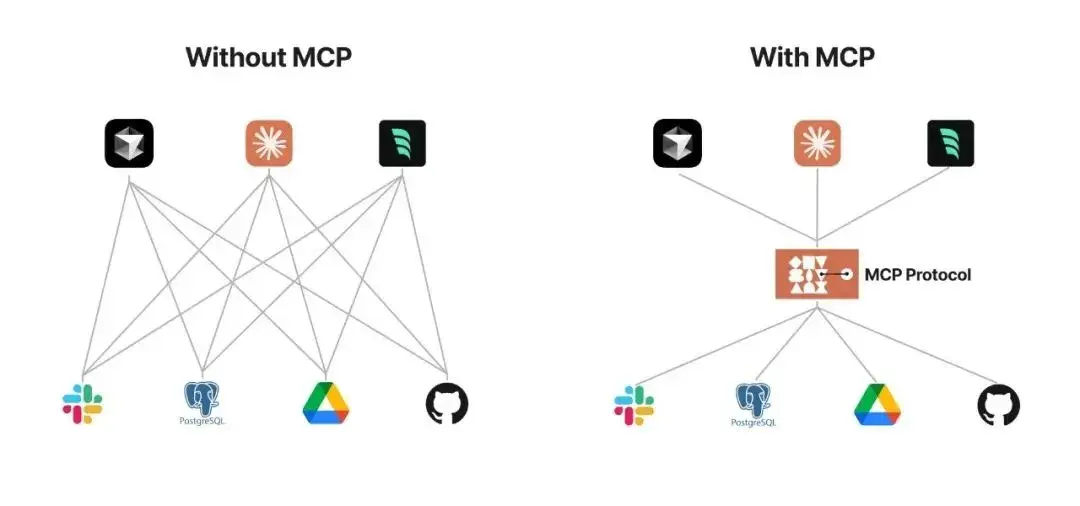
需要注意的是,数据与工具本身是客观存在的,只不过我们希望将数据连接到模型的这个环节可以更智能更统一。因此, Anthropic (Claude的母公司)在2024年提出了模型上下文协议(Model Context Protocol, MCP),旨在通过一个标准化的protocol中间层,将LLM对话和工具调用给统一起来,以便让AI模型能够主动调用外部工具和服务,从而 大大 扩展AI的 能力边界。
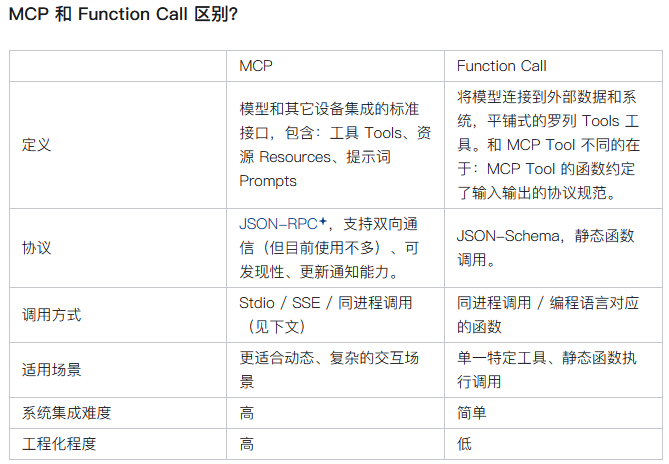
下面是一张表格,比较了MCP和function call 的区别。
二、MCP是如何工作的?DeepSeek的解释
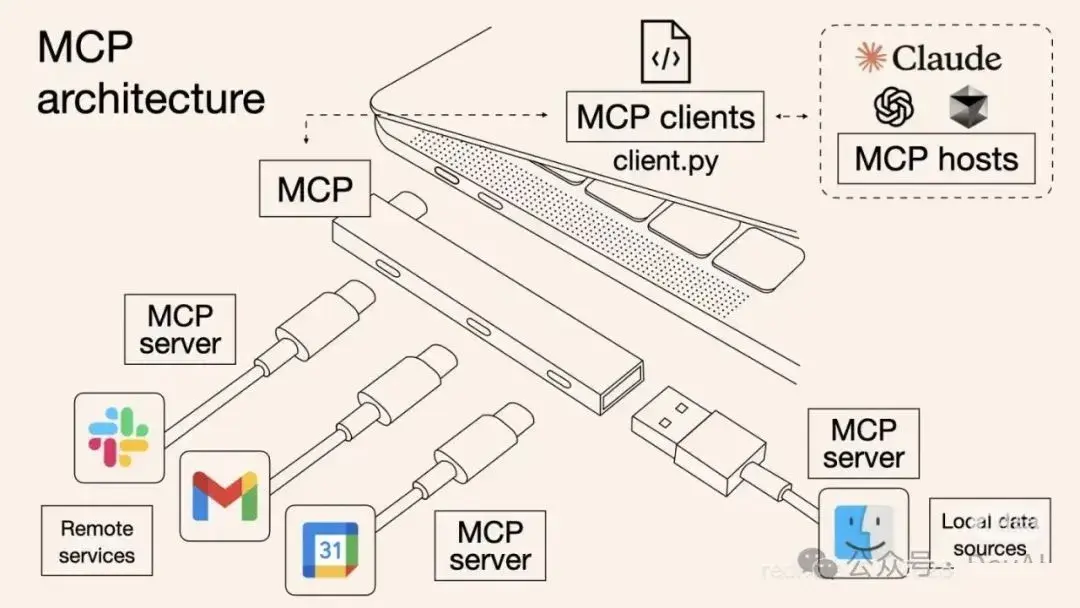
下图来自Claude,形象展示了MCP在AI agent领域的定位(就像一个usb拓展坞)。
简单来说,当用户询问AI agent一个问题时,如果条件合适,AI agent会触发MCP调用,而MCP侧会运行对应的工具,返回数据,这些数据会被插入对话上下文中,以便对话继续进行。
(一)大模型(LLM)这一侧发生的事情
核心原理:提示词工程与结构化输出
让LLM能够调用工具的关键,不是修改模型本身,而是通过系统提示词 和要求结构化输出 来实现的。我们可以把LLM想象成一个极其聪明但严格按指令行事的文书,而Agent平台就是它的上司,为它制定了一套完整的工作流程。
第一步:初始化——“赋予LLM角色与能力认知”
当会话开始时,系统会首先给LLM发送一段系统提示词。这段提示词是LLM看到的第一段文本,它定义了LLM的“身份”和“能力”。
LLM看到的内容示例(高度简化):
1 | 你是一个强大的AI助手,除了回答问题,你还可以通过调用工具来获取信息或执行操作。 |
LLM的理解: 它现在知道自己是“可以调用工具的助手”,记住了三个工具的名字、用途和必须遵守的、严格的JSON输出格式。这个JSON格式就是MCP标准化的核心部分之一。
第二步:决策与调用——“在规则下输出特殊指令”
用户提问:“北京今天天气怎么样?”
- LLM的思考(内部推理,我们不可见,但可推测): “用户问天气,我需要实时数据。我的工具列表里有
get_weather,这正合适。我需要调用它。” - LLM的输出(它实际返回的文本): 此时,LLM会严格按照系统提示词中的规则,输出一个纯文本的JSON块。
1 | {"name": "get_weather", "arguments": {"city": "北京"}} |
这就是LLM视角下的“工具调用”。对它而言,这仅仅是按照格式要求生成了一段特定的文本而已,它并不理解这段文本会触发后台程序。
(二)AI agent工具平台这一侧发生的事情
第三步:平台接管与执行——“看不见的后台魔法”
AI Agent平台(如Claude Desktop、Cursor等)在接收到LLM的回复后,会进行解析:
- 检测输出是否为有效的JSON。
- 解析出
name字段是get_weather。 - 根据MCP协议,找到在本地或远程注册的、名为
get_weather的MCP服务器(可能是一个Python脚本、一个本地程序等)。 - 将
arguments{"city": "北京"}传递给这个服务器。 - MCP服务器执行真正的逻辑(如调用天气API),然后将结果格式化成标准格式返回给平台。
第四步:结果返回与整合——“看到工具执行结果的LLM”
平台将工具执行的结果,再次以纯文本形式注入到对话上下文中,送给LLM。
LLM接下来看到的新消息(由平台拼接):
1 | 用户:北京今天天气怎么样? |
LLM的理解: “哦,我之前‘说’的那个特殊格式的句子,系统已经给了回复。结果显示北京22度,晴朗。现在我需要消化这个结果,组织成对用户的友好回答。”
于是LLM继续生成:“北京今天天气晴朗,气温22摄氏度,湿度65%,非常舒适。”
(三)总结与关键点
- LLM的视角是纯文本的连续剧: 它看到的是“系统指令 -> 用户问题 -> 自己生成的JSON -> 系统返回的工具结果文本”。它所有的“决策”都基于对这段文本历史的理解。
- 触发机制是“提示词规则”而非“模型能力”: 是否调用工具,取决于系统提示词中的规则(“当你需要…时,你应该调用”)和LLM对用户问题的理解。选择哪个工具,取决于LLM将问题与工具描述进行匹配的能力。没有任何魔法,全是上下文(提示词)的功劳。
- MCP的核心价值:
- 标准化: 为“工具描述”(LLM看到的部分)和“工具调用/结果格式”(LLM与平台交互的部分)提供了统一标准。这样,一个LLM可以轻松接入任何符合MCP协议的工具。
- 解耦: 将LLM(大脑)与工具实现(手脚)完全分离。工具可以用任何语言编写,部署在任何地方,只要通过MCP服务器暴露标准的接口即可。
- 安全性: 工具在沙箱环境中运行,LLM只能通过定义好的参数进行调用,不能随意执行代码。
- 与OpenAI的Function Calling的区别: OpenAI的API在系统层面原生支持了“函数调用”功能,LLM的输出中会包含特殊的结构化标记(如
tool_calls)。这是一种更“原生”的支持。而MCP是一种协议级的实现,它不依赖任何特定LLM的原生功能,主要依靠提示词工程,因此理论上可以兼容任何仅具备文本输入输出能力的LLM(包括开源模型),使其具备工具调用能力。
三、MCP的三种工作模式:stdio,SSE,HTTP
三种服务模式分别如下:
- stdio(标准输入输出) - 通常通过uv(Python包管理器)或其他运行时启动
- SSE(Server-Sent Events) - Web流式推送模式
- HTTP(请求-响应) - 经典的HTTP模式
这三种模式存在的根本原因是适应不同的部署场景和网络环境。
| 模式 | 适用场景 | 特点 |
|---|---|---|
| stdio | 本地工具、命令行程序,例如获取当前时间 | 最简单直接,但限于本地 |
| SSE | 需要服务器主动推送更新的远程工具 | 单向流,适合实时数据 |
| HTTP | 传统的Web API、REST服务 | 双向请求-响应,最通用 |
(一)stdio模式(通过uv或其他包管理器)
调用过程:
1 | 用户提问 → LLM生成工具调用请求 → Agent平台解析请求 |
关键技术细节:
- Agent平台创建一个子进程,通过管道连接stdin/stdout
- 使用JSON-RPC over NDJSON协议(每行一个JSON对象)
- 工具代码作为Python包安装,通过uv管理依赖
- 优势:无网络延迟,完全本地,安全性通过进程隔离
- 劣势:只能运行在用户本地机器上
(二)SSE(Server-Sent Events)模式
调用过程:
1 | 用户提问 → LLM生成工具调用请求 → Agent平台解析请求 |
关键技术细节:
- 基于单向HTTP长连接,服务器可以主动推送
- 非常适合流式输出的工具(如生成图像时的进度更新)
- 需要处理连接重试和心跳机制
- 优势:支持服务器主动通知,适合长时间运行任务
- 劣势:需要网络连接,架构稍复杂
(三)HTTP模式
调用过程:
1 | 用户提问 → LLM生成工具调用请求 → Agent平台解析请求 |
关键技术细节:
- 最经典的请求-响应模式
- 可以复用现有的Web基础设施(负载均衡、认证等)
- 支持任何能运行HTTP服务器的语言
- 优势:部署最灵活,支持远程和本地,技术最成熟
- 劣势:不适合流式场景,需要轮询查看进度
(四)为什么需要多种模式?实际用例对比:
假设我们要实现一个代码执行工具:
stdio模式(本地Python):
1 | # MCP服务器代码 |
- 用户隐私数据完全留在本地
- 执行速度快,无网络延迟
- 但仅限于用户环境可运行的代码
HTTP模式(远程沙箱):
1 | # 调用远程API |
- 可以在安全的沙箱环境中运行
- 不受用户本地环境限制
- 但有网络延迟,需要信任服务提供商
SSE模式(流式输出):
1 | // 服务器可以分块发送结果 |
- 长时间运行的代码可以看到实时进度
- 用户可以中途取消执行
- 实现复杂度最高
四、一些比较常用的MCP服务平台
如下图,这是cherry studio中列出的MCP平台的链接。
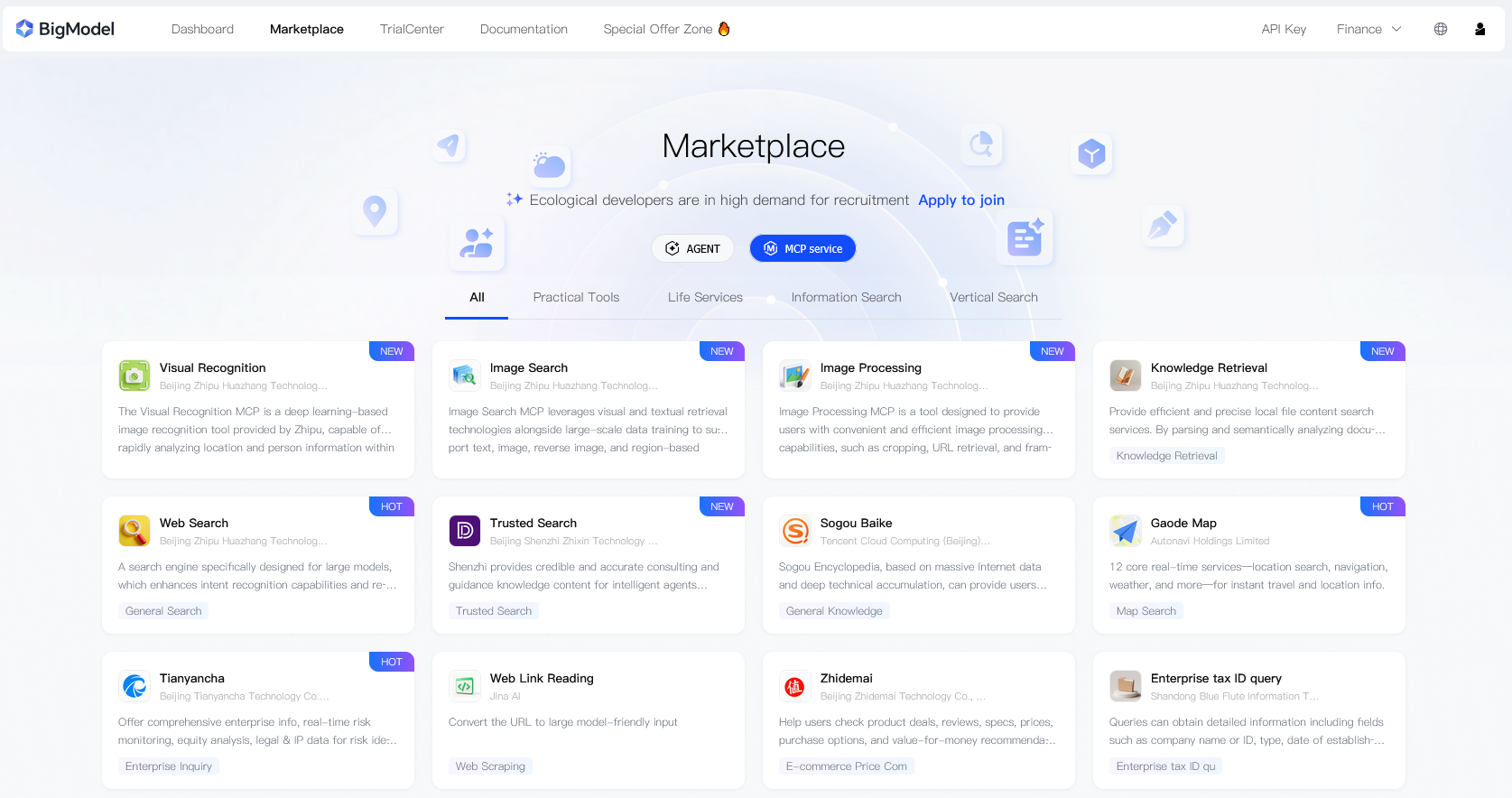
以智谱MCP平台(BigModel MCP Market)为例,其提供了大量开箱可用的MCP,如下图,这里面不仅包括web search之类的基础服务,还包括 搜狗百科、高德地图、天眼查、什么值得买 等app或论坛的数据接口,可以方便AI agent获取这些app或论坛的内部数据。
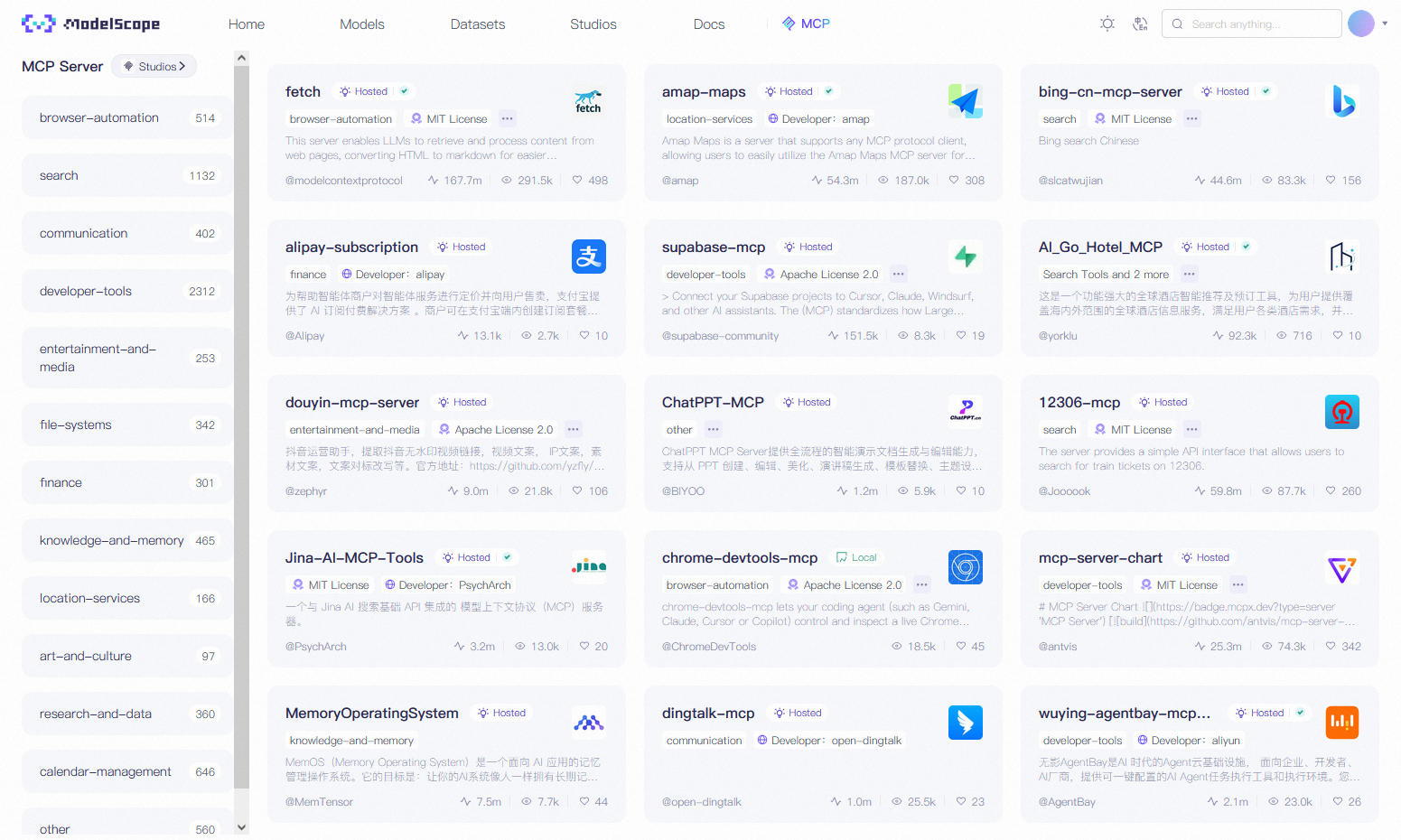
另一个常用的MCP平台是阿里云推出的魔搭社区(ModelScope),如下图所示。与智谱MCP平台不同的是,这里集成了很多阿里巴巴生态里的app接口,例如高德地图、支付宝、钉钉 等app;除此之外,此处也有flomo之类的笔记app的接口——这极大方便了AI agent接入笔记app的操作。
关于如何配置MCP,不同的MCP工具有不同的配置方法,此处限于篇幅不做展开,需要配置MCP的读者朋友可以先从查看文档开始(比方说,Sogou Baike MCP 这个工具的页面中就详细介绍了接入cherry studio的方法,可以点击链接自行学习)。
以上。
参考: