基于阿里云的LLM微调(他山AI agent实训营作业1)
最近参加国科大他山协会AI agent实训营,学习到了不少东西。第一次作业是LLM微调,下面浅浅记录一下作业过程。
一、训练集
我们选择了下面这几篇群体遗传学领域的研究论文,作为训练材料:
1 | Edge 和 Coop - Reconstructing the History of Polygenic Scores Usi.pdf |
二、语料切分与训练集生成
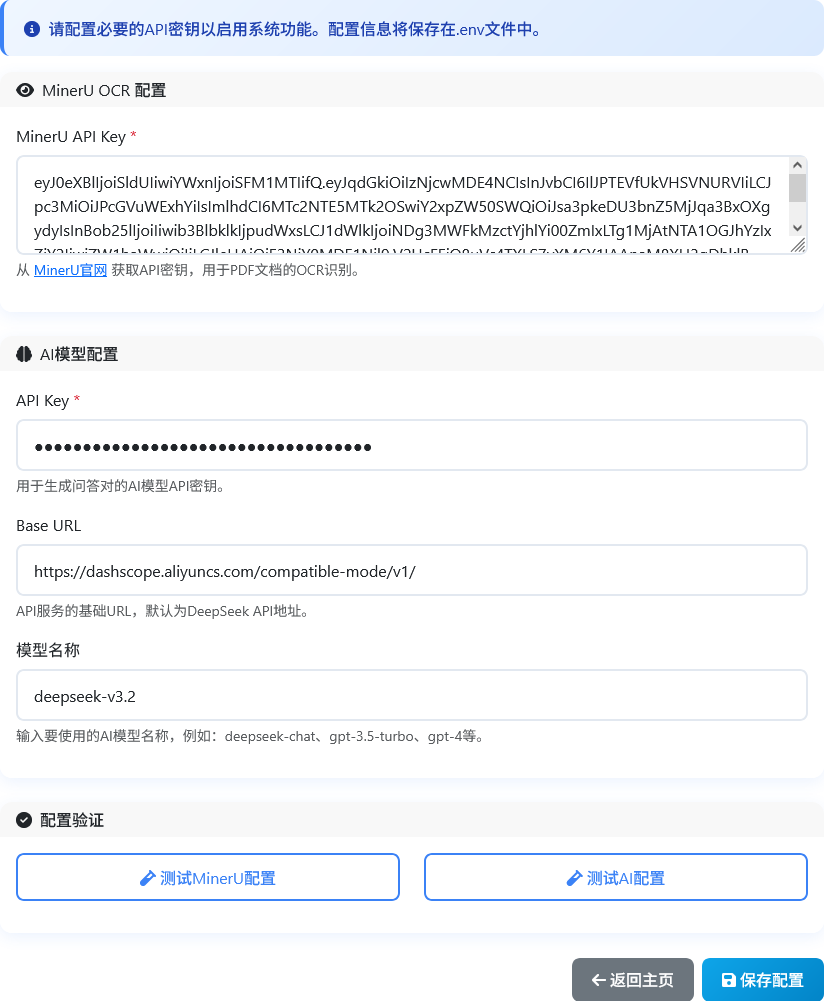
利用 LLMjuice项目 进行了自动化处理。模型参数设置如下图所示,其中问答对使用deepseek-v3.2模型生成:
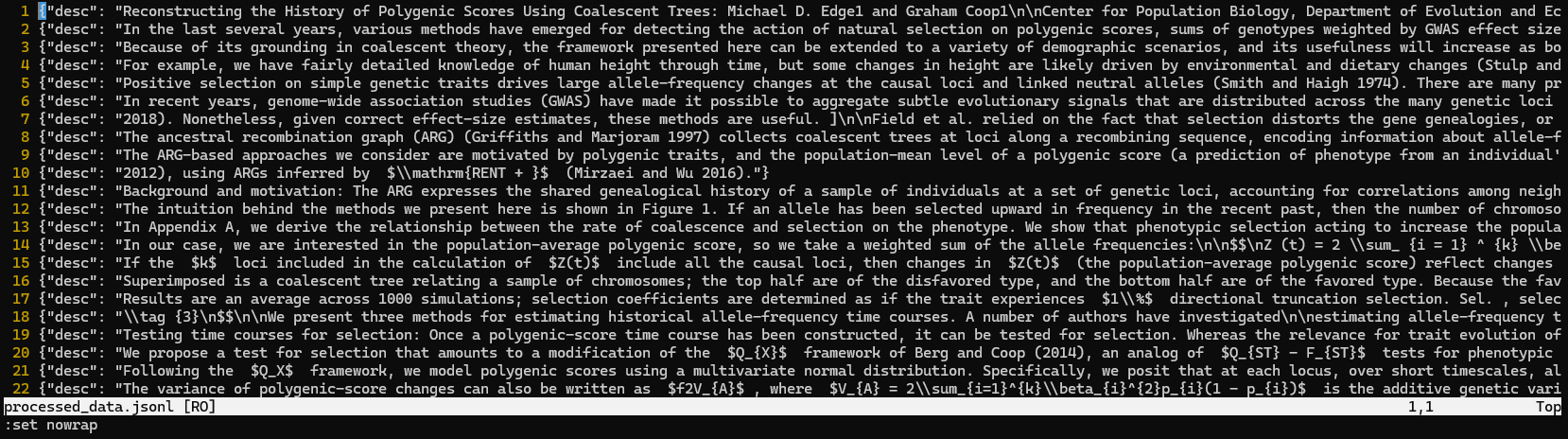
语料切分的步骤,产生了324条数据,部分数据的内容如下图所示:
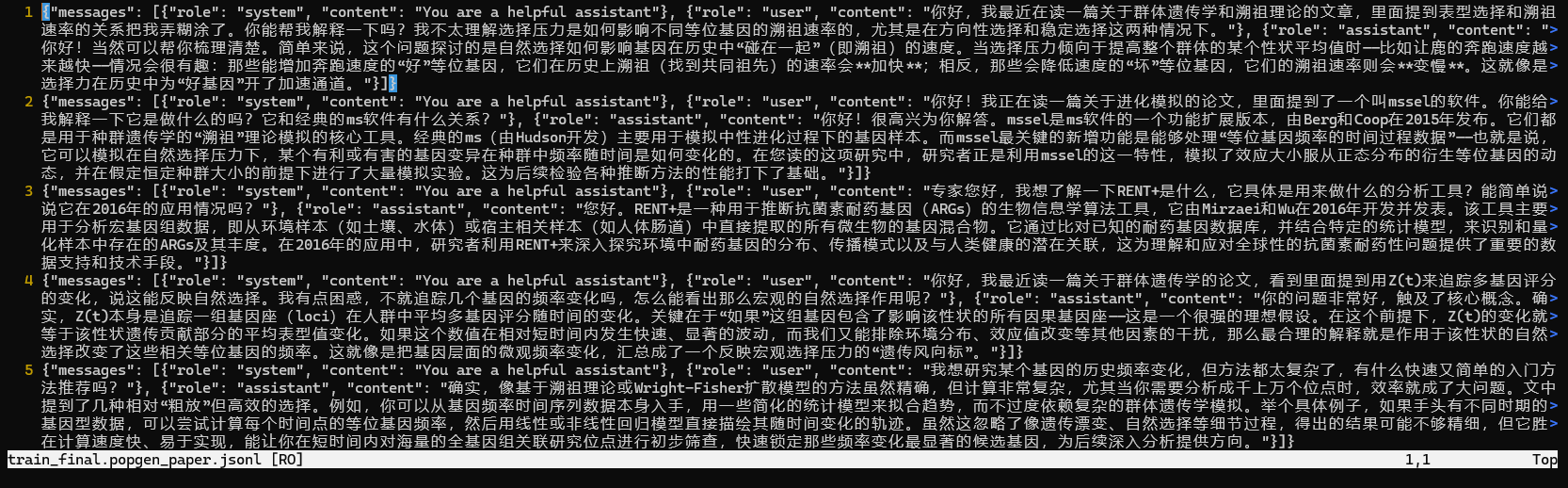
在训练语料生成阶段,LLMjuice通过调用deepseek-v3.2生成了400条问答对,部分内容如下图所示。文件名称为 train_final.popgen_paper.jsonl ,这个文件将用于下一步中大模型的微调。
三、大模型微调(基于阿里云百炼大模型)
(一)语料上传
在阿里云百炼的页面中,依次通过 模型服务→工作台→数据管理→新增数据集 找到数据集添加的页面,数据集命名为 popgen_paper ,然后上传刚刚得到的那个 jsonl 文件,如下图所示。
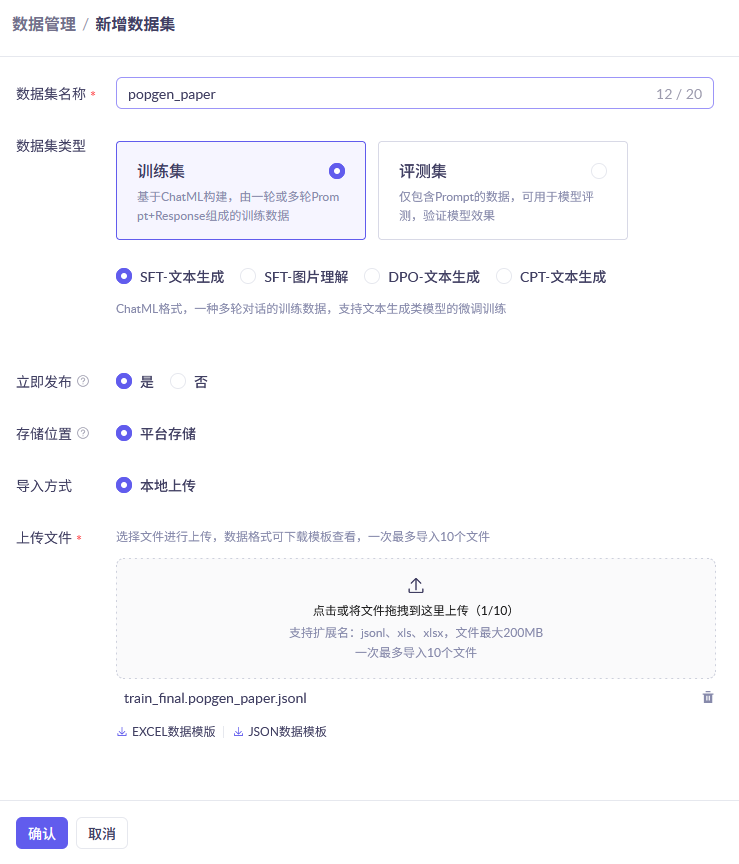
处理完成后,在 数据管理→数据集 页面中,可以看见刚刚上传得到的数据集。

(二)微调
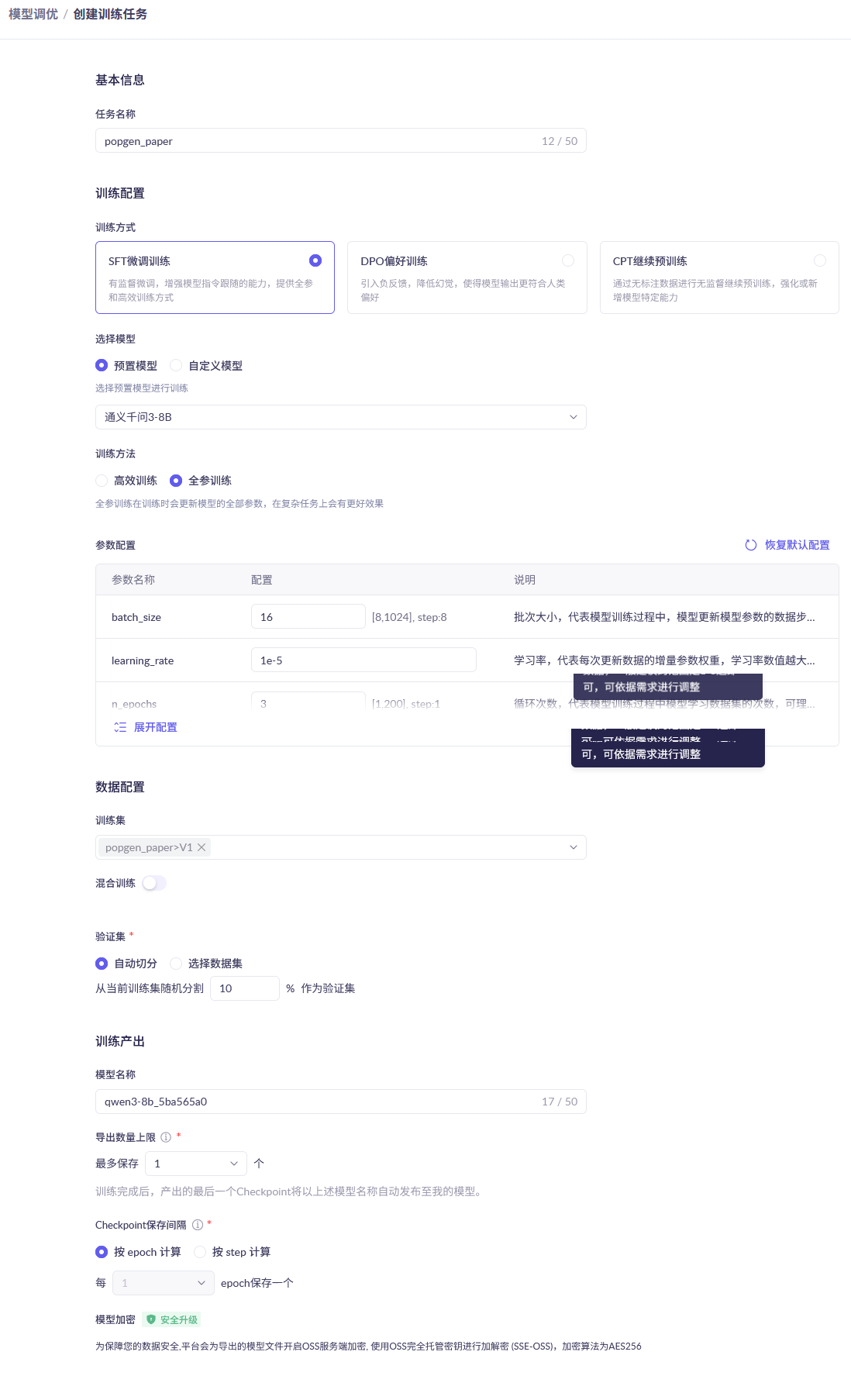
在阿里云百炼的页面中,依次通过 模型服务→模型训练→模型调优→创建训练任务 找到训练微调任务的页面,任务命名为 popgen_paper ,基座模型可以任选一个参数规模较小的模型(例如这里选择qwen3-8b,这是今年阿里巴巴通义千问团队发布的一个小模型),使用全参训练模式,数据集使用刚刚上传的popgen_paper数据集,其他参数均用默认值,如下图所示。点击“开始训练”,即可开始微调过程,微调过程的训练费用预估为2元左右,用时大约半小时。
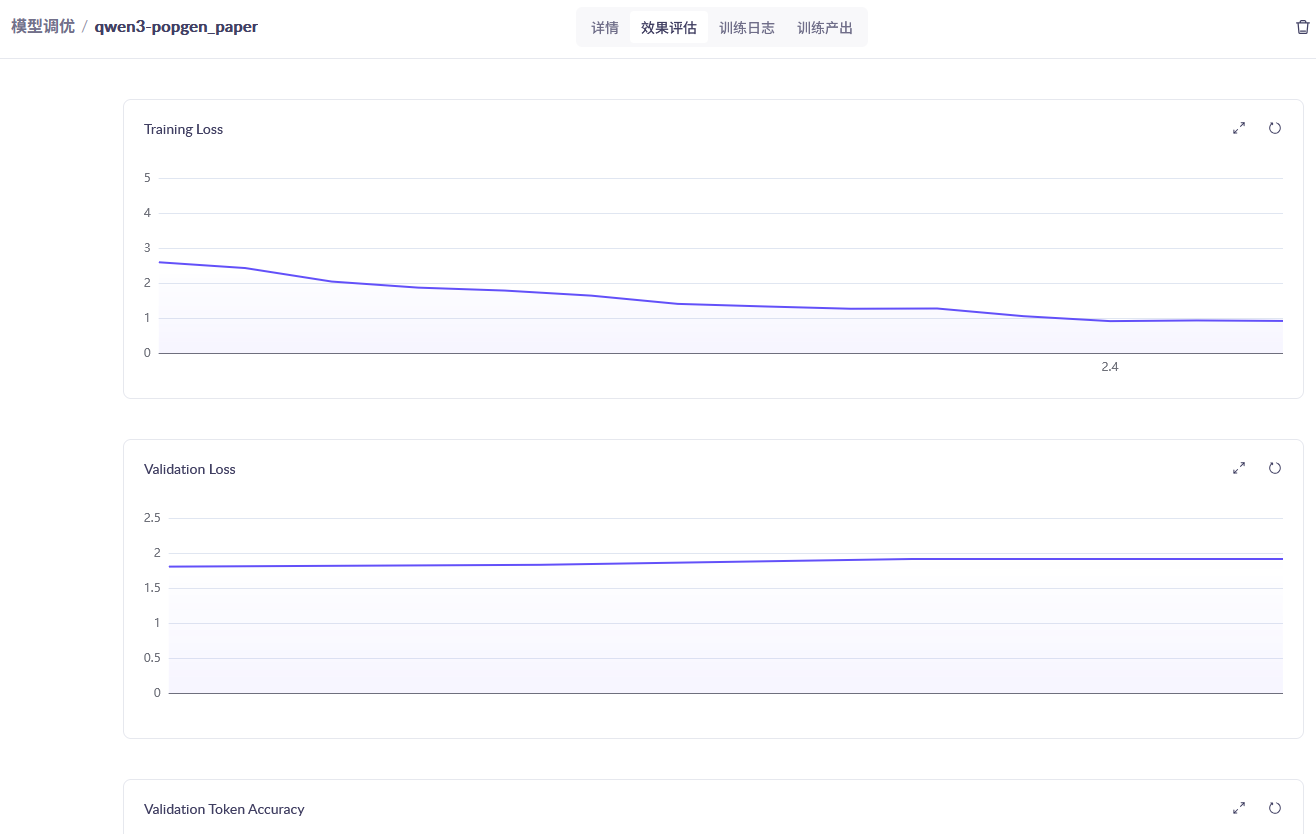
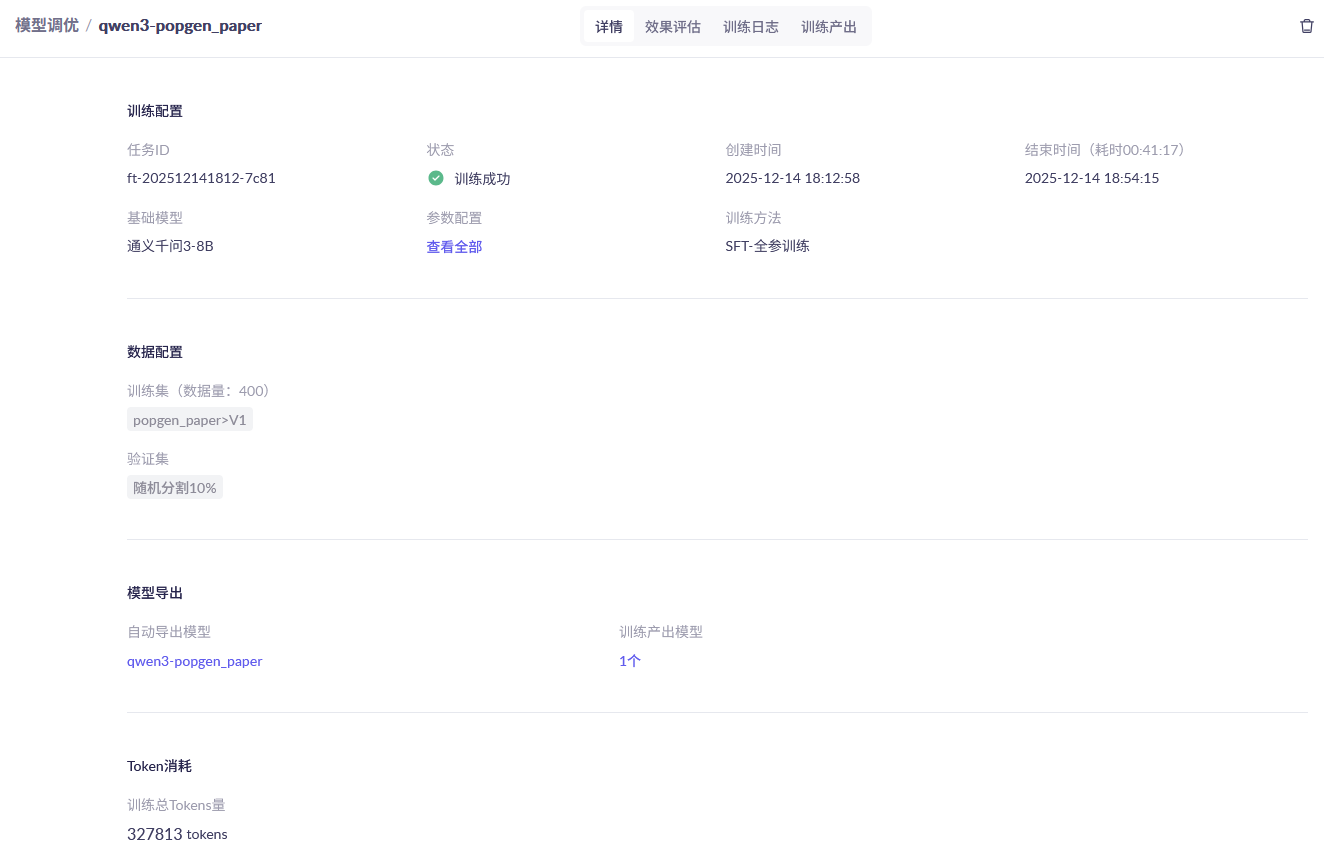
在 模型调优 页面里也可以查看模型训练的状况,如下图所示:
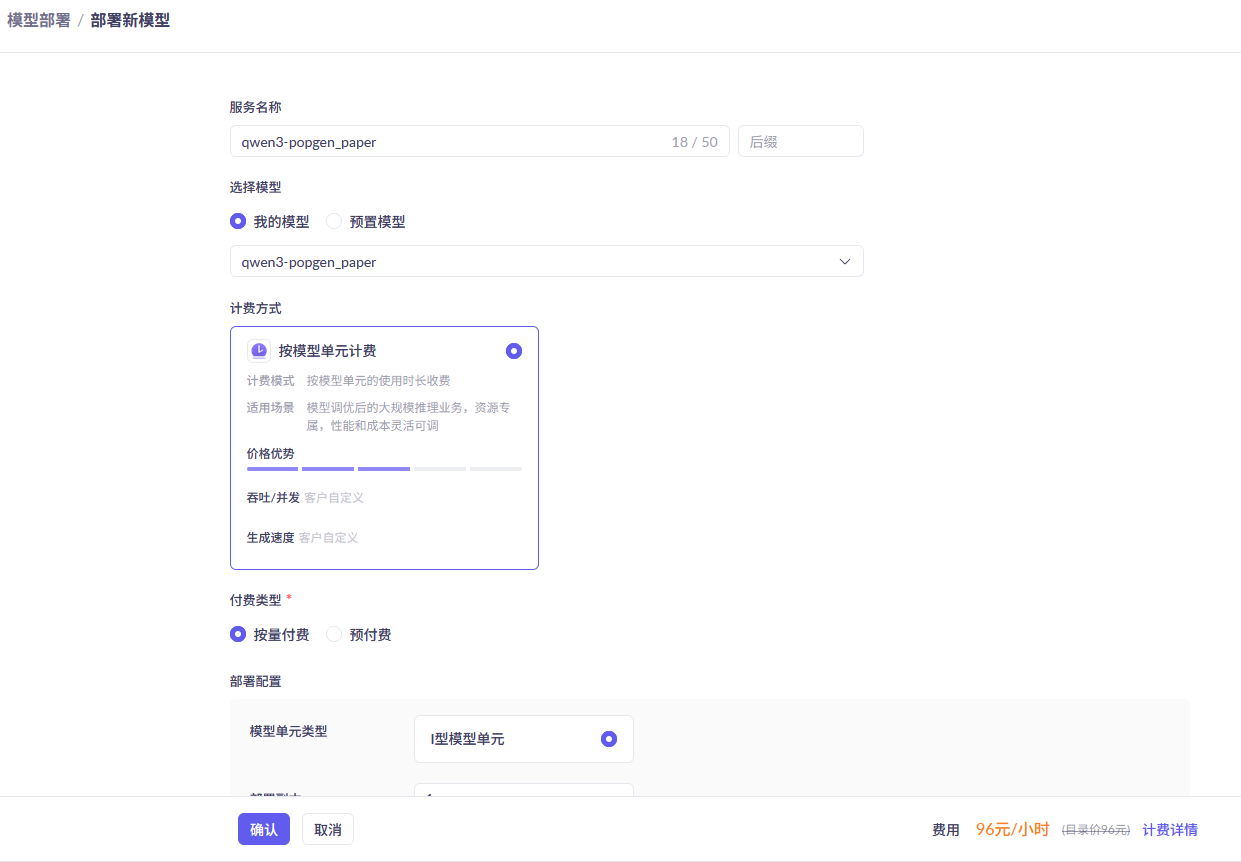
训练完成后记得部署,如下图所示。但是需要注意,部署费用较贵,在不使用时记得下线模型,以避免费用超支。
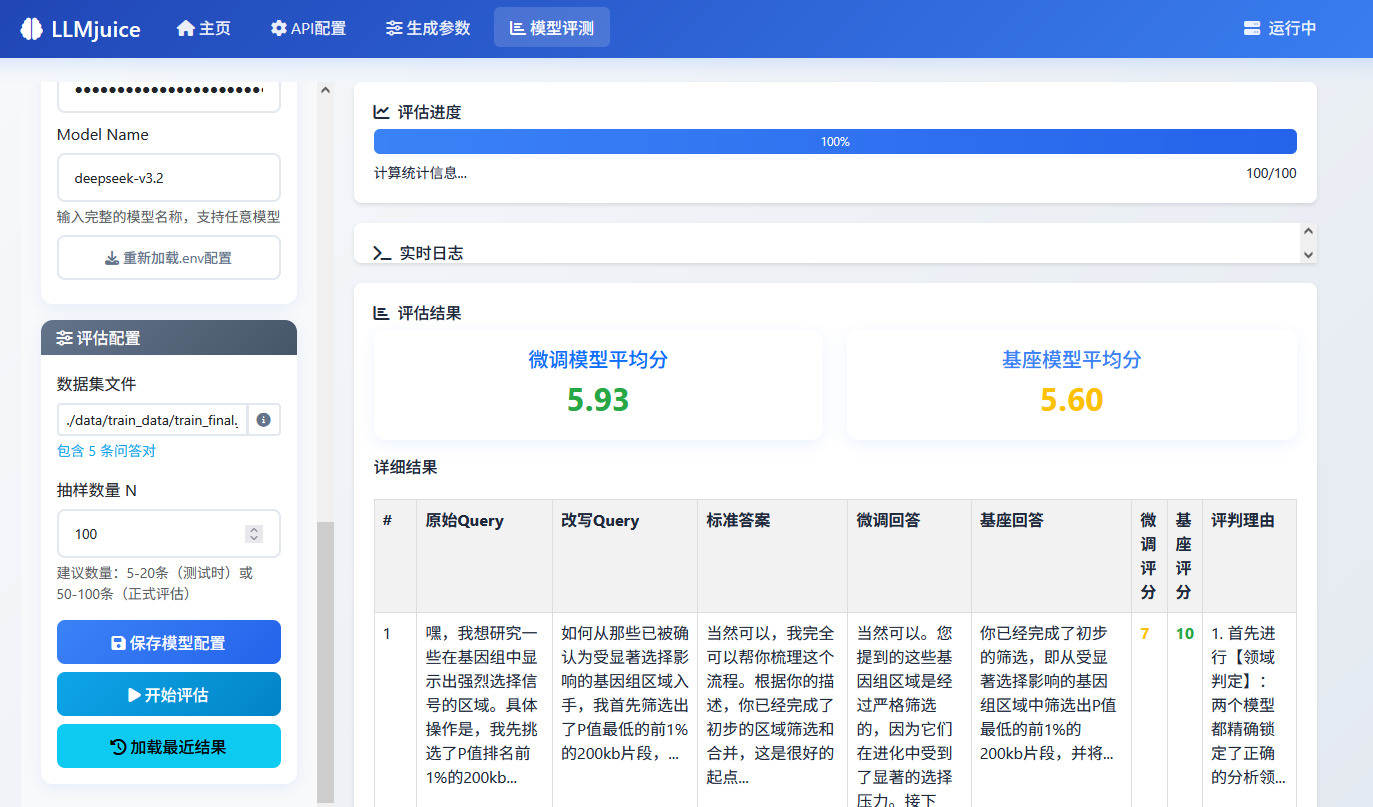
四、模型评测
这一步我们继续使用LLMjuice。如下图,使用微调后的模型(模型code为 qwen3-8b-ft-202512141812-7c81 ,可以在百炼控制台里找到)和基座模型(qwen3-8b)进行评估,从训练集中随机抽取100条对话让两个模型分别回答,然后使用deepseek-v3.2打分。最终的评分结果为,微调模型总分5.93,高于基座模型的5.60,说明微调改善了模型在特定领域问题(群体遗传学)上的知识能力。