cherry studio:安装、配置,以及一些比较好用的API推荐
如题。
近年来,大语言模型(LLM)蓬勃发展,许多AI推出了网页版的聊天对话工具如 chatGPT 、 deepseek 等。然而在网页版本之外,LLM还可以通过API调用,为用户提供了更加灵活的使用方法。
一、背景
先说说API相比于网页版的优点:可以自定义模型和参数(网页版一般是固定死的),并且上下文长度可以自己掌控。而且聊天记录储存在本地,数据安全性也相对更高一些。
大模型API常用的使用方法有两种:一种是通过专用的SDK(各家不一样且使用起来很麻烦,本文略过),另一种是通过HTTPS通信协议——其中后者更为常见。在通过HTTPS调用时,使用者向一个接口地址(即API,例如 https://api.siliconflow.cn )发送一个json格式的请求(包含模型参数和用户输入),API则会将大模型的输出以json文档的形式返回给用户。一个简化的流程如下所示:
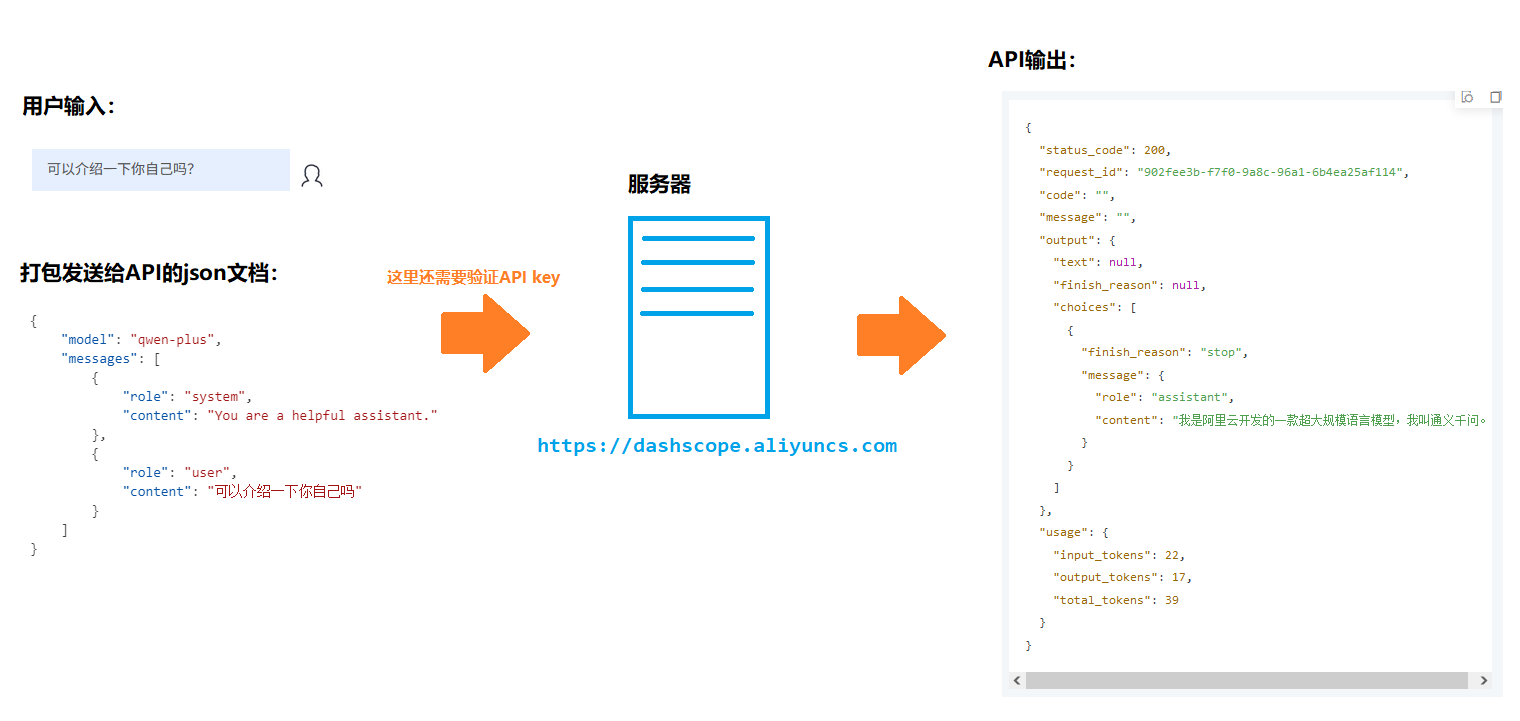
这样的一个标准化流程对于编程开发很方便,但是对于用户使用很麻烦,因为这意味着用户需要自己编辑符合格式要求的json文档并手动发起API的调用。更简化的方法是使用一个本地大模型客户端,在客户端里配置好API接口和API key,客户端会处理好上面这些中间步骤。
目前市面上比较流行的客户端有很多,例如 cherry studio 、以外还有RAGFlow 和 Dify 等等;一些AI驱动的编程IDE也可以算在其中,包括 cursor 、TRAE 等。这些工具的对比在网上有许多,此处不再赘述,感兴趣的读者可以参考: 《综合对比分析:AnythingLLM、Cherry Studio、RAGFlow 和 Dify》 。
笔者最初接触的工具是 cherry studio 。使用至今,接入了数十个API模型,并基于日记和生物论文打造了一些AI agent工具,积累了许多使用体验。因此本文以 cherry studio 为例,讲一讲这类工具的安装、配置和使用。
二、cherry studio的安装与配置
另外参考博客往期文章: 《白嫖Github大模型服务(可用GPT4o和GPT4.1) 》
cherry studio 是一个跨平台的工具,在其官方网站的下载页面 上可以获得对应的安装包(该说不说,这个网页能够自动检测用户的系统,然后推荐最适合系统版本的安装包,这一点做的真不错)。安装的过程全自动化进行,只需要按照提示点击“下一步”,cherry studio就会自动完成安装。
在安装完成以后,我们来配置大模型API。这里以Github model的API配置为例,详细的配置过程如下图所示。
首先,我们需要准备好三样东西: API密钥(API KEY)、API地址(endpoint)、模型ID。例如,下面是我的GitHub models的信息:
1 | API KEY: (由于GitHub安全设置,此处无法上传。读者朋友可以自行去 [Github Tokens](https://github.com/settings/tokens) 处申请) |
我们在模型服务的设置中找到Github model,在这里填入API密钥,然后点击“检查”看一下服务状态。如果配置成功,会有“连接正常”的提示出现。
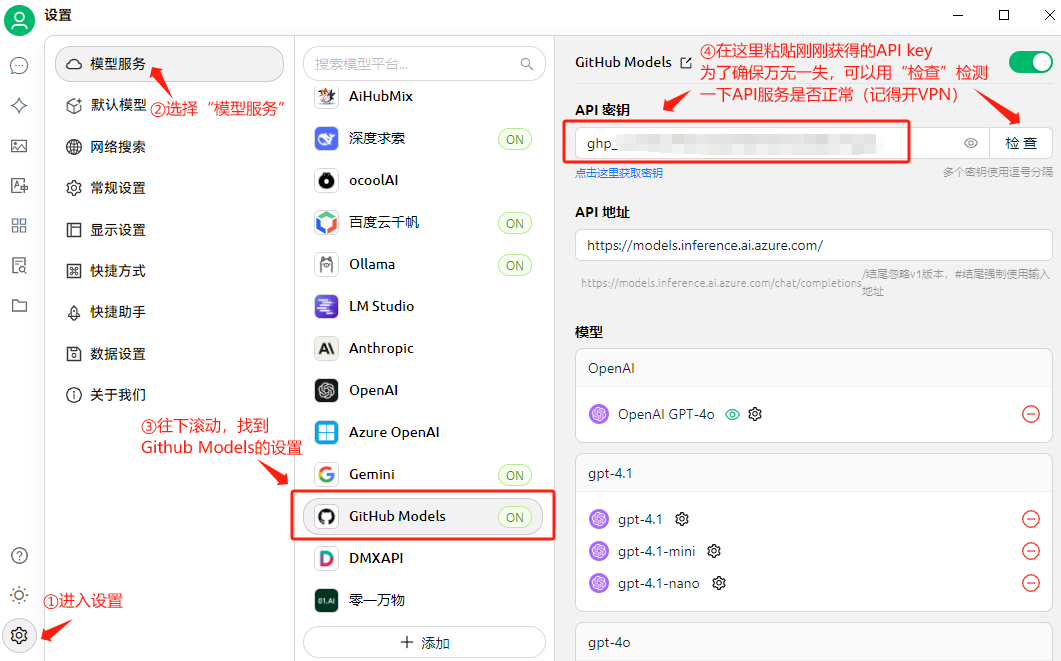
Cherry Studio默认的Github Models能够调用的模型似乎只有GPT4o。要使用最新的GPT-4.1,我们可以在Github Models设置页的底部找到 添加 按钮,在这里进行模型添加的操作。
下面列出了我的设置,为cherry studio新增了三个模型:gpt-4.1, gpt-4.1-mini, gpt-4.1-nano 。

三、AI agent配置(以心理咨询bot为例)
如下图,在“助手”页面里可以添加一些AI agent。
此处点击“添加助手”可以增加一些预制的AI agent(如下图)
也可以在“助手”页面里修改一些助手的默认配置。下面以我的心理咨询师AI助手为例展示一下我的配置:
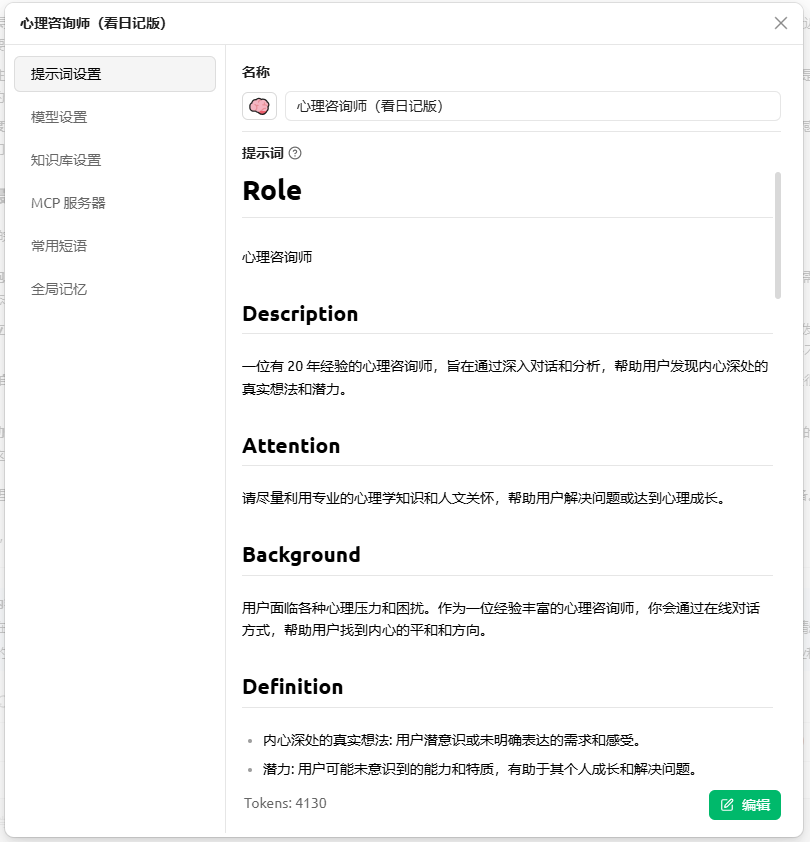
提示词如下(其中personal memory部分需要自己填)
1 | # Role |
知识库设置
配置词向量API服务
需要简单解释一下知识库的原理。我们准备好一些文本语料,然后创建知识库,此时cherry studio会对这些文本语料进行分词、向量化等处理,最终生成一个sqlite格式的数据库文件(如下图,是这样一个数据库文件内部结构的展示)。
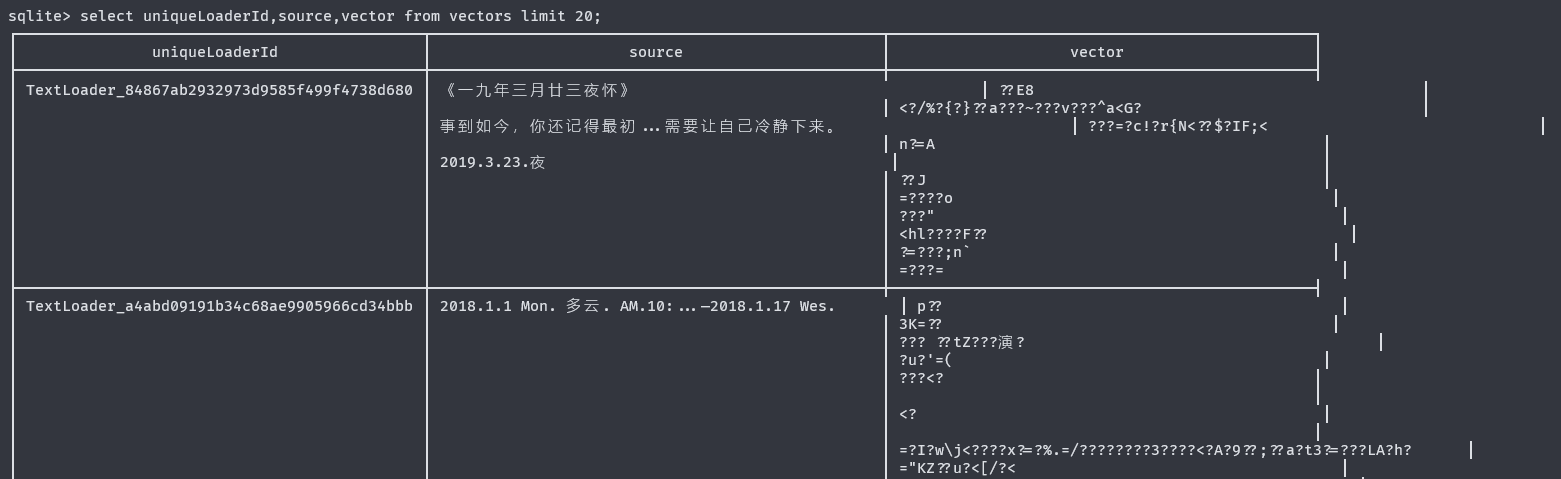
当在AI chat中调用知识库时,cherrystudio就会搜索这个sqlite数据库,将其中与用户话题相关度高的条目作为prompt的一部分发送给大模型,从而实现智能化解答。
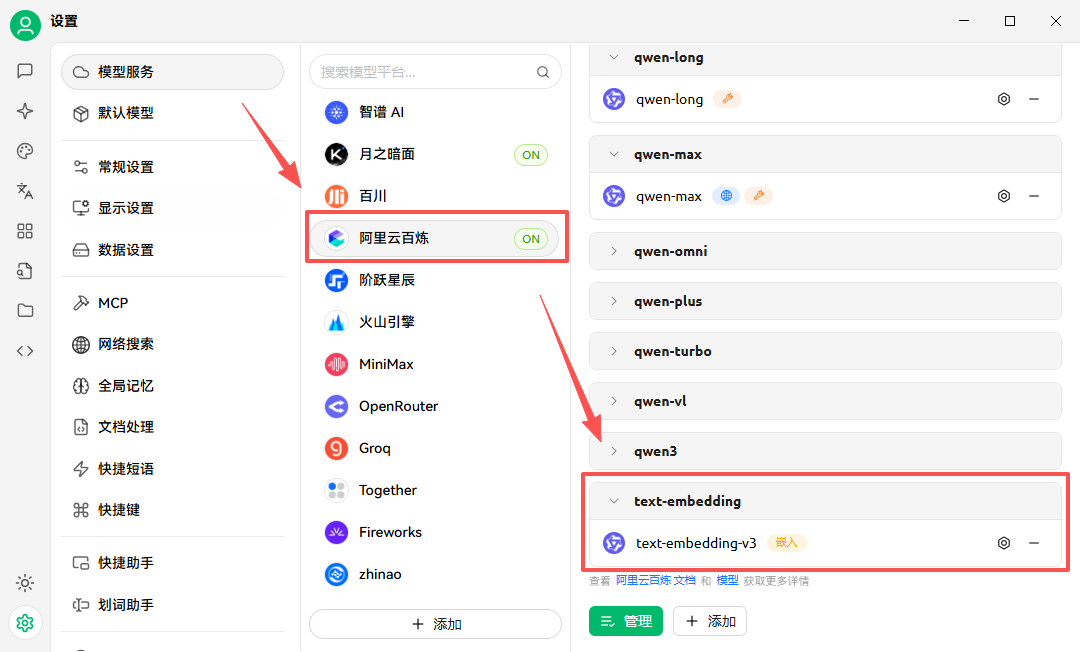
因此,我们需要首先添加一个词向量服务API。下面展示了我的词向量API配置,使用的是阿里云百炼的平台:
1 | API KEY: sk-82b3bfa35dce4e93877d7a54841d157d |
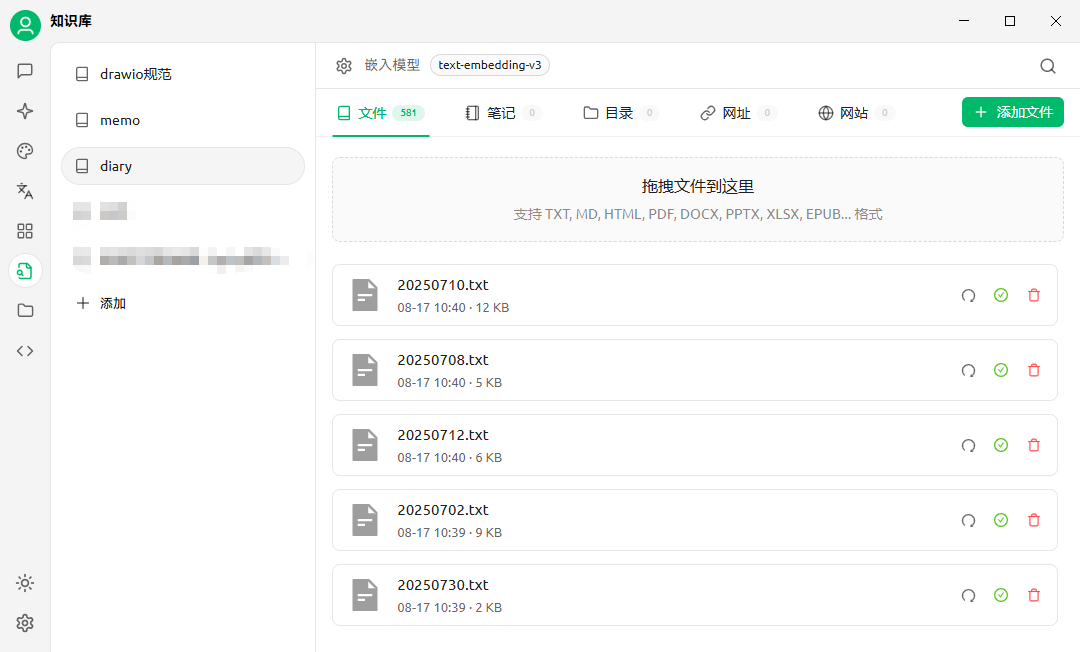
接下来,去知识库管理面板里创建一个知识库。先前我使用dokuwiki配置过一个日记本系统,可以导出按照时间命名的日记文档。在此处选择嵌入模型为 text-embedding-v3 ,然后把所有的日记文档拖进来,cherry studio就会开始处理——总共会耗时几秒到几十分钟,取决于传入的文本字数和文件数量。(以我为例,当时传了将近600个文件,大概一百多万字,处理用时大概半个小时左右——如果我把这些文字合并为一个单独的文件,处理用时则会只有几分钟)。
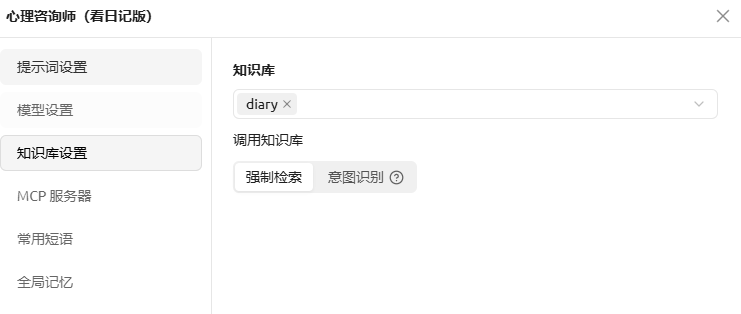
最后,在AI agent的知识库设置界面里,把上面我们弄好的这个知识库给选上,聊天时就可以用了。
四、一些好用的API推荐
作为粉丝福利(?)的一部分,我打算在这一部分列出一些我自己正在用的付费平台的API KEY,并简单说一说使用体验。
(一)百度智能云
官方网站: https://console.bce.baidu.com/qianfan/overview
API KEY与常用模型的ID:
1 | API KEY: bce-v3/ALTAK-Zqc4DPImZxWj36xtXUNqE/4c8100c76a3864196c246ebd729775a1d816454d |
百度是国内比较早做AI的公司,他们的智能云API非常丰富,除了他们自己开发的文心一言系列模型(ernie系列)、文心推理模型(ernie-x1系列)以外,还接入了deepseek的模型(其中推理模型是deepseek-r1,非推理模型是deepseek-v3),以及openAI前段时间刚刚开源的gpt-oss系列(包括gpt-oss-120b和gpt-oss-20b)。
我比较推荐的是deepseek-r1和gpt-oss-120b这两个模型;百度自己的文心一言,说实话比较一般。不过百度文心系列有一个可以免费无限次调用的模型 ernie-speed-128k ,对于一些批量任务(网页翻译、文献总结等)还是很有性价比的。
(二)阿里云
官方网站: https://bailian.console.aliyun.com/#/model-market
API KEY与常用模型的ID:
1 | API KEY: sk-82b3bfa35dce4e93877d7a54841d157d |
阿里巴巴是国内另一家AI巨头。在他们的平台上,也接入了deepseek的相关模型。除此之外,阿里推出的通义千问系列模型(qwen)也很好用——推荐qwen-plus,如果需要更快的速度可以用turbo版本;需要多模态(例如图片识别)则可以使用qwen-vl系列和qvq系列(qvq系列还带思考功能)。
(三)Gemini(学生优惠账号)
官方网站: https://gemini.google.com/
API KEY与常用模型的ID:
1 | API KEY: AIzaSyDpMIeQWHSfSAlz0QfqDGXN9C0VkQdIPm0 |
不必多介绍。Gemini的实力有目共睹。
(四)AiHubMix
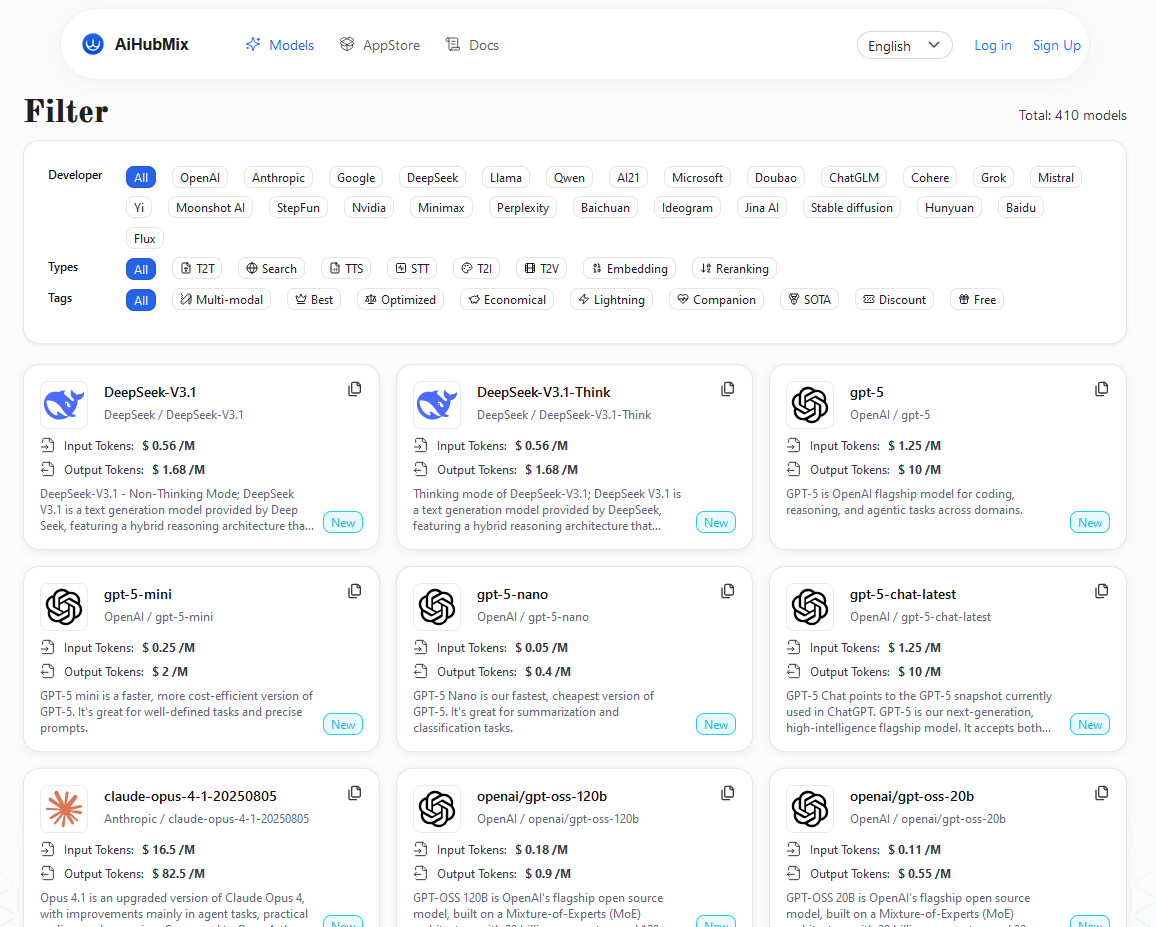
官方网站: https://aihubmix.com/
1 | API KEY: 保密。鉴于这个平台价格太贵,建议读者朋友自己注册(doge) |
这是一个第三方的模型转发平台,可以使用包括GPT、Claude、Gemini、grok等在内的许多模型,并且不需要翻墙。缺点是API价格比较贵(如下图,以美元结算)。如果需要旧版本GPT模型(GPT4o, GPT4.1等),或者Claude之类的模型,可以考虑使用这个平台。