博客图床迁移
最近发生了一件事:聚合图床(superbed) 好像挂了,导致博客上的部分图片无法加载。
这个周末尝试解决了一下这个问题。
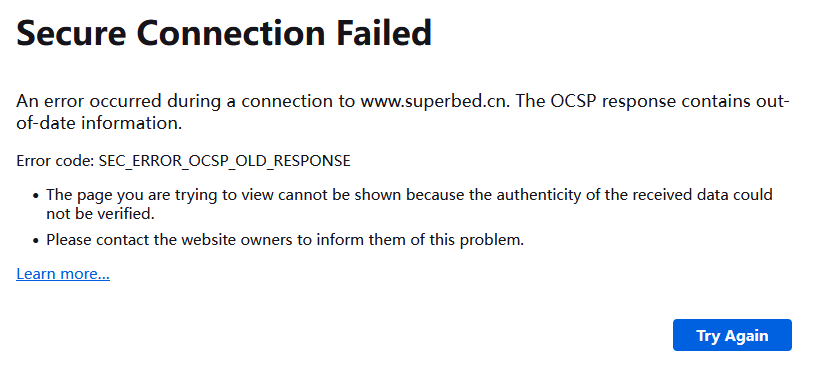
如上图,原先的图床无法访问,图片也一并无法加载。
一、背景:什么是图床
一句话总结: 图床(Image Hosting) 是一个用来存储图片的网络服务。图床的出现,与网页富文本格式HTML以及后来的笔记格式markdown紧密相关。
通常来说,一个文本文件(如txt文件)是不含图片等资源的。一些本地储存的富文本文件,如word文档(.doc, .docx)、keynote演示文稿(.ppt, .pptx, .key)等,本质上是一个压缩文档,其中既包含了文本文件,也包含了格式排版样式表和图片、形状、声音等资源文件。
在互联网领域,一个网站所显示的页面,本质上也是一个富文本文件(HTML,Ajax,PHP等),其中文本格式的源代码是其主要框架,而网站上要显示的各种资源如图片、视频等需要单独存放。由于网页开发的灵活性,开发者不必将图片与网页源代码完全打包在一起,也可以另行存储,并使用 <img src="..."/> 之类的标签进行引用——而用户在浏览器端访问这个页面时,浏览器就会自动从 src="..." 处下载图片并嵌入到网页当中。而批量储存这些图片的服务提供商,就可以称之为图床。
具体来说,用户上传图片后 ,图床会返回一个图片的外链地址(URL),我们可以把这个链接嵌入到网页 、博客、论坛、Markdown 文档中,从而展示这张图片。
关于图床服务的选择,网络上有许多教程,本文不再赘述,下面列举几篇之前参考过的博客文章,感兴趣的读者可以自行阅读:
最初,我的博客系统使用的是WordPress框架,其自带图片存储功能,不需要图床。后来因为服务器到期,文章迁移到了Github上,从那时起聚合图床(superbed) 成为了我存储图片的地方。
再往后,由于担心安全问题,我开通了腾讯云COS对象存储服务(参考往期文章 《obsidian探索小记(二)——配置obsidian的自动上传图床》 ,这是一个按量计费的服务,但胜在安全可靠),并以此作为主要的图床;但一些过去的图片并没有来得及迁移。也许现在是迁移的时候了。
二、聚合图床(superbed)的访问错误问题分析
我在AI工具的帮助下,对 SEC_ERROR_OCSP_OLD_RESPONSE 这个错误进行了分析。一些解释如下图所示,简单来说,网站的 SSL 证书可能已经过期,因此所有指向superbed的访问都被浏览器拦截。但这并不意味着图片丢失——也就是说,还有希望把图片找回来!

有一种方法是使用curl -k工具去访问网站,其中 -k 参数代表忽略SSL/TLS证书验证错误。于是我进行了尝试:
1 | curl -v -k https://pic.imgdb.cn/item/657ef7dfc458853aefe61be8.jpg -o temp.jpg |
输出如下,服务器给出了302重定向的返回值,提示网站域名可能变了。
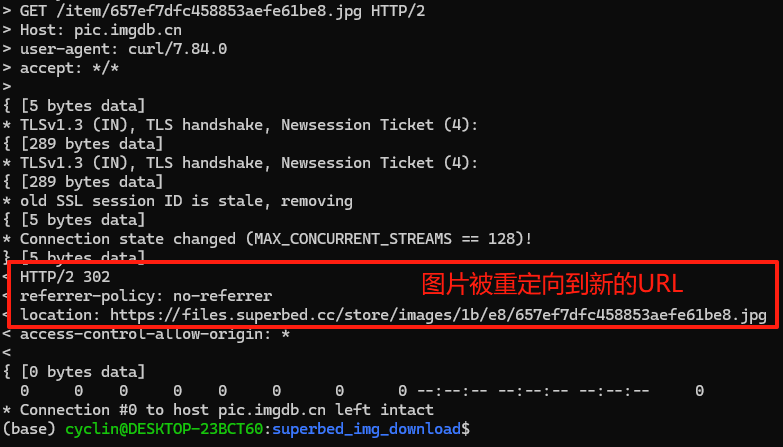
curl 工具还有 -L 参数可以追踪网页的重定向,让我们现在试一试:
1 | curl -v -k -L https://pic.imgdb.cn/item/657ef7dfc458853aefe61be8.jpg -o temp.jpg |
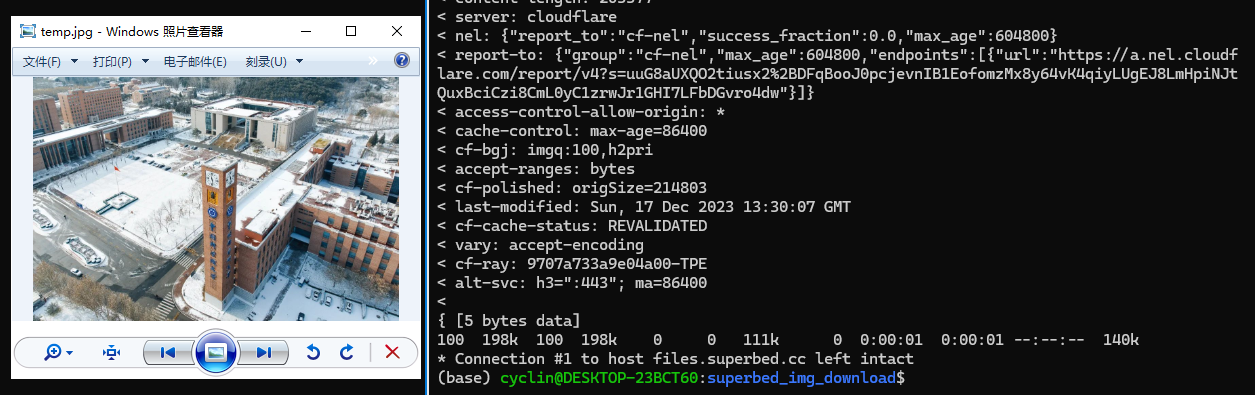
于是我们成功下载到了图片。这说明,聚合图床还没完全挂,图片还有挽救的希望。
三、图片的批量下载、转存、替换
由于聚合图床还没完全挂(只不过浏览器无法访问),我们或许可以使用下面的方法解决博客中的图片问题:
利用curl工具下载图片→使用picgo上传到腾讯云COS→批量替换博客文章中的图片链接
下面是具体步骤。
(一)批量下载图片
先获取需要替换的图片链接
1 | # 首先cd到博客文章源代码目录 |
img_to_download.txt 文件内容长这个样子:
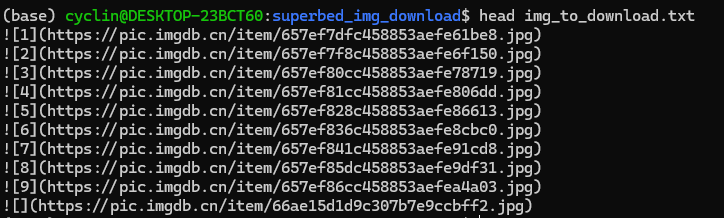
接下来,使用python的os库批量调用外部命令 curl ,将图片下载到 files/ 目录下。
1 | #!/usr/bin/env python |
下载完以后的文件夹长这个样子。如果有一些图片显示不出来,可能是下载失败,这个时候可以继续使用curl指令手动重新下载。
(二)使用picgo批量上传到腾讯云COS对象存储服务
配置picgo和腾讯云对象存储服务的方法,可以参考博客往期文章:
首先,我们需要注册和开通腾讯云COS对象存储服务(此处使用其他云服务商的对象存储服务也可以,常用的有亚马逊S3、阿里云OSS等),并安装picgo-core。使用 picgo set uploader 进行账号设置,随后随意选取一张照片 picgo upload 一下,只要没有报错,就意味着配置成功。
接下来,我们依然使用python实现一个批量上传的脚本。其原理是使用 os.listdir() 获取文件夹下的所有文件,之后调用 picgo upload 实现上传。
1 | #!/usr/bin/env python |
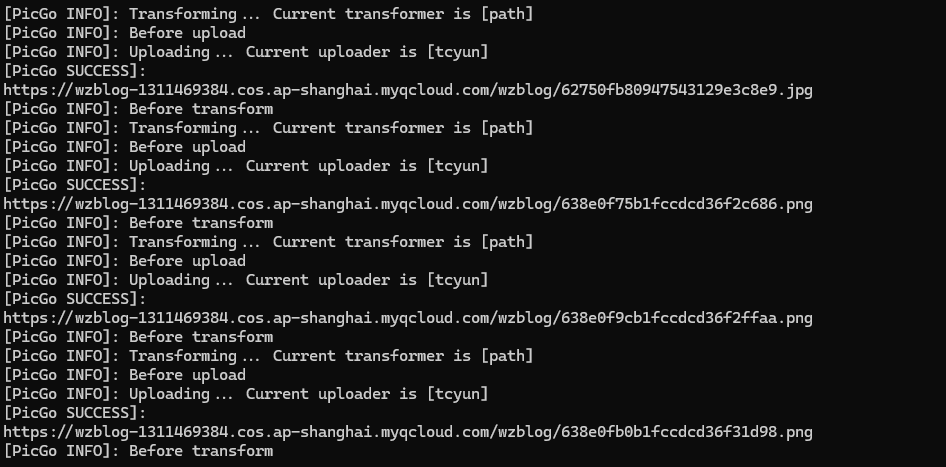
运行截图如下。这里有一个有意思的点,上传的图片其URL后缀和我们的初始文件名是一致的,因此后续在文章中替换URL时,可以只匹配聚合图床的域名部分并替换,而不需要考虑完整的URL路径。
(三)批量替换博客文章中的URL
这一步依然使用python实现,使用 os.listdir() 批量读取当前文件夹下的markdown文件,并对图片URL进行替换。
聚合图床原先的URL链接到的域名有两个,一个是 https://pic.imgdb.cn/item/ ,另一个是 https://pic1.imgdb.cn/item/ 。因此我们只需要匹配这个域名,然后替换为腾讯云COS的域名 https://wzblog-1311469384.cos.ap-shanghai.myqcloud.com/wzblog/ 即可。
代码如下:
1 | #!/usr/bin/env python |
到此,我们的问题就解决了。完结撒花!