PDF文字注释的底层机制与数据结构:从一条bug说起
PDF(portable document format)自从上世纪末由adobe提出以来,已经渐渐成为了广泛流行的文档格式之一。这是一个排版格式,其内部由二进制信息流(版面上的对象模型)组成,相比于word文档这种流式文档格式,PDF原则上不可修改(除了可以进行标注和标记),但其格式规范使其有着极高的兼容性,可以在任何设备上以相同的排版浏览文档内容。
最初,能够浏览PDF文件的软件是adobe官方推出的查看器(Adobe Acrobat),随后市面上陆陆续续有许多公司也推出了自己的PDF查看器或渲染引擎。其中,有一个很著名的软件叫福昕PDF(Foxit PDF),这是一个中国人开发的软件,其底层渲染引擎使用C++编写,性能很强——于是后来谷歌与福昕达成合作,共同推出了PDFium这一开源库,供其他PDF浏览器的开发者使用——包括谷歌chrome,微软edge浏览器,甚至WPS PDF在内的许多软件,都使用了这一开源库。因此某种意义上,福昕PDF的技术支撑了PDF阅读器的半壁江山。
但开源的PDF阅读器不止这些。PDFjs是另一个流派的渲染引擎,纯JavaScript编写,最初是一个实验性项目,随后被Firefox浏览器收编并开源,目前由Mozilla基金会管理。PDFjs作为纯JavaScript实现的引擎,在网页端开发领域天然具有极大的优势,因此不止Firefox浏览器自身,还有许多提供PDF文件在线浏览功能的网站也使用了这一技术。
PDFium vs PDFjs,C++ vs JavaScript,孰好孰坏?这个问题恐怕见仁见智。毕竟PDFium有着更好的性能和排版效果,但也更加笨重,启动比较慢;PDFjs在面对大文件时力不从心,但小小的体积也使它身轻如燕,十分灵活。特别是最近几年,Mozilla的开发者们为PDFjs新增了PDF标注的功能(包括文本高亮、文字标注、随笔画等等),更使其具备了一个成熟PDF阅读器的素养。
然而今天要讲的bug,就与PDFjs的标记功能有关。
问题描述
在阅读并标注PDF文件时,我发现了一些奇怪的现象。
我有两个PDF阅读器,其中一个是金山WPS PDF,底层使用了PDFium的库进行解析(由foxitPDF出品)。另一个是Firefox自带的PDF浏览器,底层是PDFjs库。这两个阅读器都有文本标注和标记功能。
在阅读时,我有时候会使用文本标注功能添加文字笔记。但是使用了一段时间以后,我发现金山WPS PDF(PDFium)的文字标注功能的兼容性更好,其添加的文本标注在Firefox(PDFjs)中依然能够正常显示;但是Firefox(PDFjs)的文本标注,大部分情况下无法被金山WPS (PDFium)解析和显示,只有少数情况下可以正常显示。
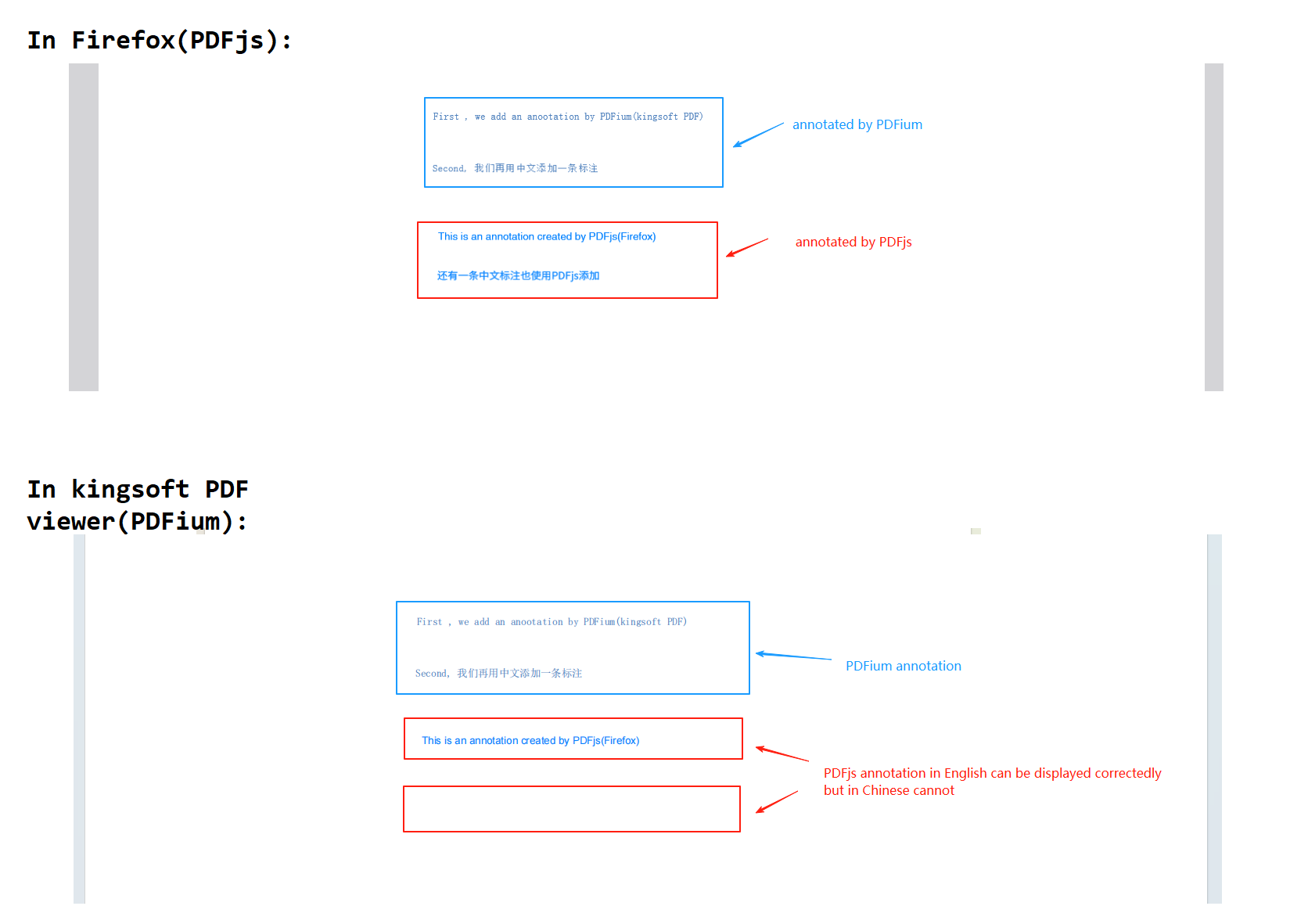
感觉有点奇怪。于是我去查看了PDF文件的源码,希望找到问题的关键所在。
PDF源码反编译
为了理解问题的产生原因,我去翻阅了PDF文件的源代码,并找到了几段疑似这些软件添加的文本标注功能的信息流的内容,如下:
1. 疑似kingsoft PDF(PDFium)标注的信息流。这几段信息流都可以在Firefox(PDFjs)中正确渲染。
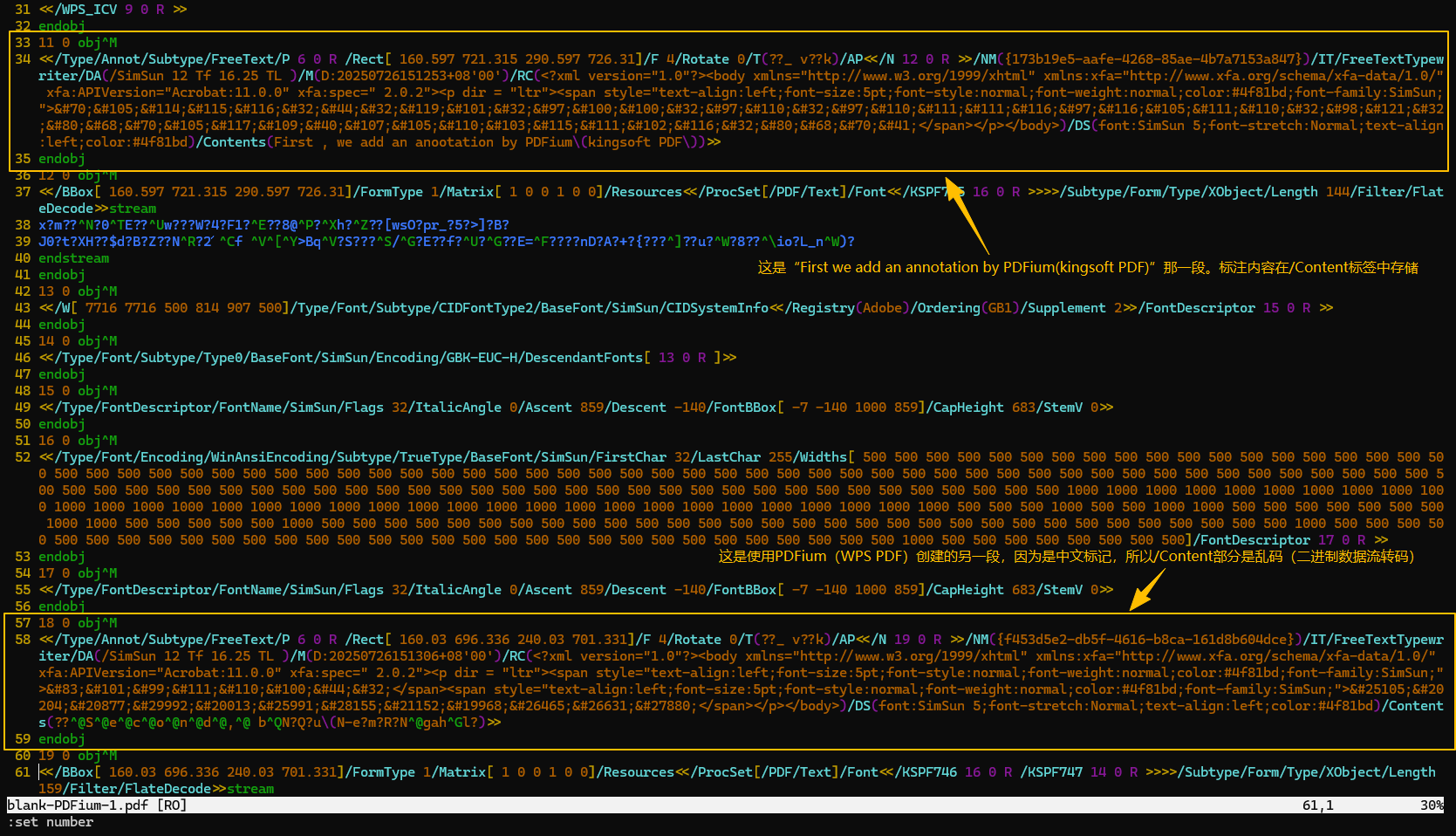
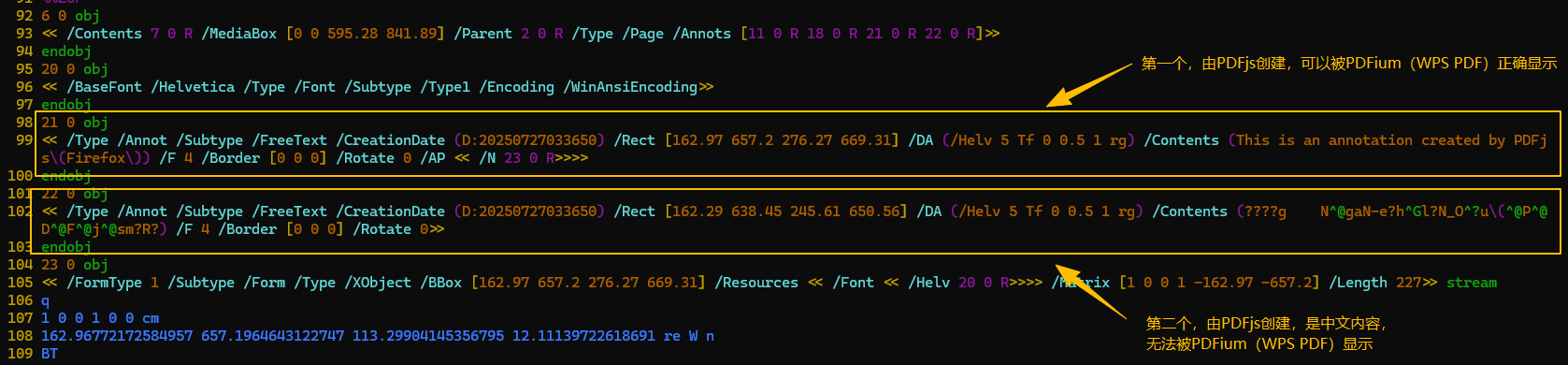
2. 疑似Firefox(PDFjs)标注的标注信息流,其中第一段是可以被正确显示的内容,第二段是无法被显示的内容
进一步的探索与问题排查
虽然定位到了出问题的源码,但是作为一个什么都不懂的小白,想要理解问题出现的原因依然很困难。所以我求助了AI(DeepSeek+Gemini)。下面是AI的一些介绍和回答:
首先,关于PDF注释的文件格式规范:如下图,有一系列的标签用来存储这些注释,但是在不同PDF阅读器商的具体实现中会有区别(例如PDFium会生成符合标准的详细注释信息,但是PDFjs会偷懒只生成一两个标签)。

具体来说,PDFium实现了更为完整的注释信息流,尤其是包括外观流(Appearance Stream, /AP),这是PDFium的注释有着更好兼容性的关键(如下图)。

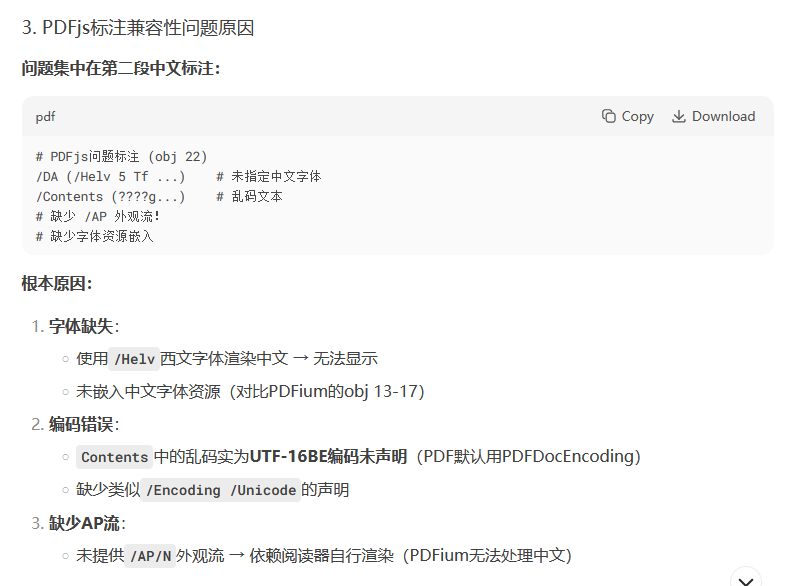
反观PDFjs,其注释内容只有 /DA 和 /Contents 字段,未能实现 /AP 流,且缺乏中文字体的嵌入,所以当注释内容是英文时还好(可以使用默认字体渲染),但是遇到中文注释时就力不从心了,生成的注释只有PDFjs自己认识,其他的PDF阅读器都看不懂,自然无法显示(如下图)
尾声
这个bug对我来说影响其实并不算大:PDF中文标注并非刚需,且有WPS PDF兜底,不用担心这个功能用不了。但是bug依然很烦人——已经和Mozilla官方提交了这个bug的issue ,期待他们后面可以重视并修复吧。
以上。