YOLO11图像识别模型初次上手
如题。周末闲来无事,尝试配置了opencv-python和yolo11的环境,运行起来了一个比较基础的图像识别程序。
一、介绍
YOLO(you-only-look-once)是一个轻量级、高效率的图像识别模型。其基于卷积神经网络但做了许多优化(形象来说就是把一张图片切成许许多多小方块,然后并行对每个小方块做图像识别任务,最后合并相同对象的方块),流线型设计使其适用于各种应用,并可轻松适应从边缘设备到云 API 等不同硬件平台。
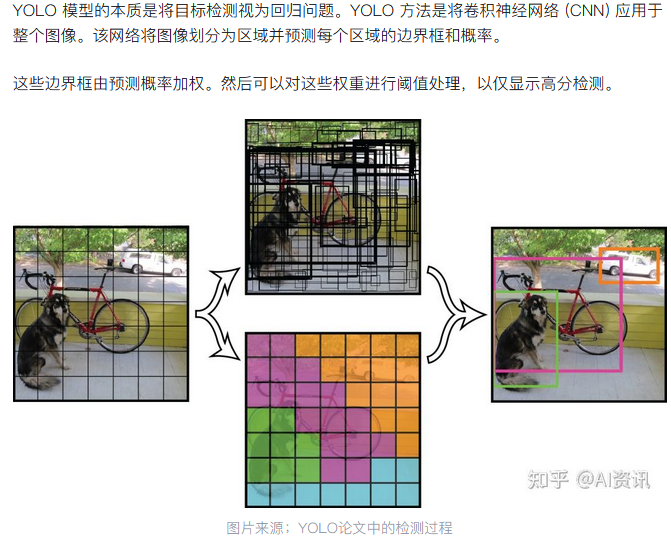
想要了解更多,可以参考下面这些内容:
二、搭建yolo11环境
YOLO官网上给出了详细的安装步骤,并提供了模型权重的下载链接。主要分两步:安装python依赖,以及准备模型权重文件。
(一)安装依赖
参考: https://docs.ultralytics.com/quickstart/#use-ultralytics-with-cli
安装环境的步骤很简单。首先,电脑上要有python和pip,接下来我们使用pip运行下面的指令即可:
1 | # Install the ultralytics package from PyPI |
这一步一并会安装依赖项,包括 torch, torchvision, numpy, matplotlib, pandas, pyyaml, pillow, psutil, requests, tqdm, scipy, seaborn, ultralytics-thop 等。如果电脑上已经有相关python库,则可以使用 pip install ultralytics --no-deps 单独安装yolo本身。
(二)下载YOLO11模型权重文件
我们访问YOLO11的介绍页面 ,在这个页面中有一个performance小节,比较了YOLO11的5个不同参数规模版本的性能。此处的Model列是带有链接的,点击会被链接到GitHub存储库release页面,从而进行权重文件(pt文件)的下载。
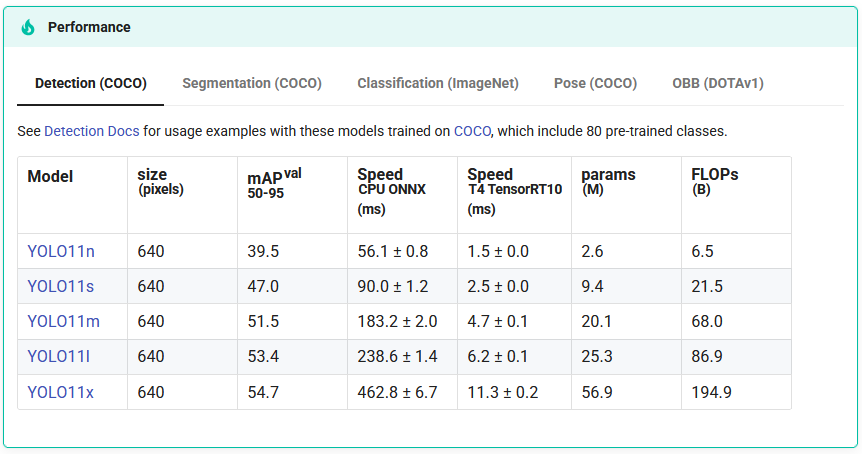
简单讲一下这几个模型的区别:模型后缀n,s,m,l,x对应着从小到大的5个模型(nano,small,median,large,extreme),它们各自的参数规模在params列有显示。具体到文件大小,nano版本的模型大概有5.4MB(因此可以部署在一些边缘计算设备上),而median版本的模型大约是38.8MB,在普通家用笔记本电脑上足够运行起来。
我们以median版为例,下载下来的文件名为 yolo11m.pt ,我们可以把它放在待会儿要用的工作目录当中。这样,准备工作就完成了。
三、YOLO的正式运行
(一)检测静态图片
如下是我的工作区目录结构。我创建了一个目录 models 用于存放模型文件,一个 dataset 用来存放待检测的静态图片。yolo11-demo.ipynb 是我的工作文件。
1 | (torch) H:\temp\temp-2025-07-06-yolo11-demo>tree /f |
YOLO识别静态图片的任务很简单:读取图片,然后识别,这样就可以了。代码如下:
1 | from ultralytics import YOLO |
输出大约是下面这个样子:
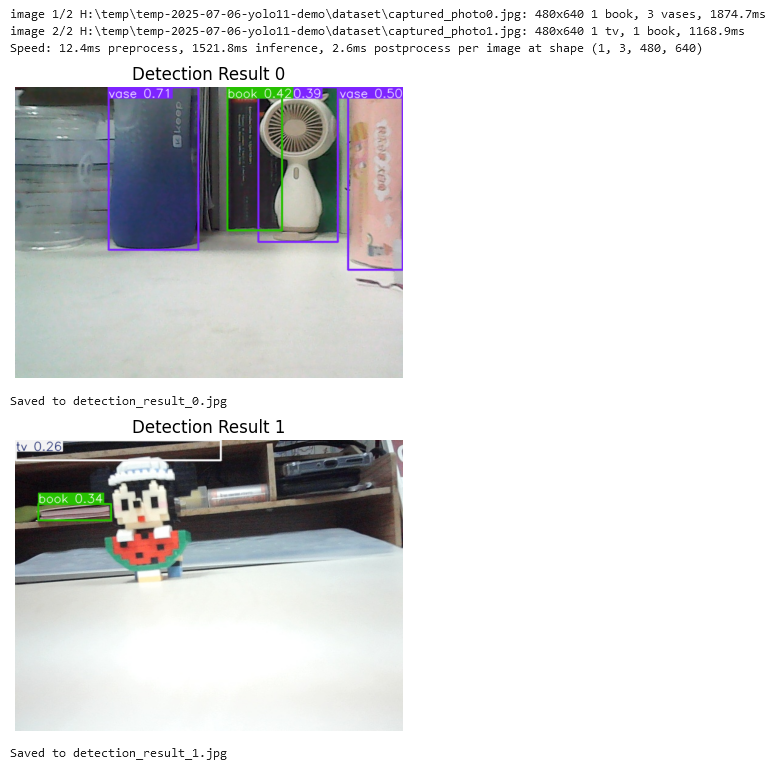
也可以打印出各个识别框的具体位置以及类别信息:
1 | for r in results: |
输出:

(二)配合摄像头的实时场景检测
首先,确保电脑有摄像头(如果是台式机,则可以外接一个USB摄像头)。
下面的代码可以用来测试摄像头能否正常调用。运行代码,如果没有异常,则在代码同级目录下应该会生成一张文件名为 captured_photo0.jpg 的图片,具体分辨率以及图像尺寸取决于摄像头。
1 | # To install the package, try: pip install opencv-python |
要使用YOLO实时检测,我们可以对上面的代码进行一些修改(仍然基于前面那个ipynb文档)。
1 | import cv2 |
运行效果如下:
四、一些遗留问题
1、实时检测代码在运行时,发现随着运行时间的变长,图像识别速度有显著下降,推测可能和摄像头缓冲区数据交换瓶颈有关。对此,AI提出可以使用异步的图像捕获与YOLO检测,但代码比较复杂,此处没有进一步探索。
2、YOLO提供了对模型进行微调、训练的方法,在官方文档中有详细介绍,此处不做展开。这一模型在众多领域都有应用,例如交通监测、医学图像处理等等,感兴趣的读者可以后续慢慢了解。