中科院学术优化(`gpt_acadmic`)服务端部署
是这样的,ANOMS现已接入中科院学术优化(gpt_academic)服务!
访问链接:ANOMS 学术优化
周五的时候听了个线上的讲座:


这个网站是中科院内部部署的一个平台,访问链接为 中国科技云 AI 科研助手 。此处宣传了两个功能,分别是学术优化和Latex公式自动识别,不过我看了下,它们分别对应着两个不同的网页,其中前面那个是“中科院学术优化”大模型平台,后者似乎只是一个OCR工具。
官方的这两个网页确实挺好,不过也有缺点:其背后的服务器似乎不够强大(他们接入的都是本地模型),且应对不了特别大的带宽(即,访问的人一多就会卡)。所以,当我看到“中科院学术优化”大模型平台是开源的服务端时(Github: binary-husky/gpt_academic ),就萌生了自己部署的想法。
0. 租用云服务器、配置域名解析
略。(这个工作算是某种运维基础操作了,网上许多教程)
1. 克隆源代码
如题。
1 | git clone https://github.com/binary-husky/gpt_academic.git |
2. 安装必要的python库
按照这个服务端的说明文档,要跑起来的话还需要安装一些python依赖库:
1 | cd gpt_academic |
大概会下载几百MB左右的内容,主要涉及网站后台服务、文本向量化、PDF切分以及大模型调用等模块。
3. 配置后台接入的大模型
3.1 获取API-key
笔者没有很好的服务器,不具备配置高性能本地大模型(如full-scale的deepseek)的条件。因此退而求其次,使用大模型API进行配置。
获取API-key的过程可以参考:
3.2 配置config文件
接下来,将服务端根目录下的 config.py 复制一份为 config_private.py ,之后的修改主要在config_private.py 中进行:
1 | cp config.py config_private.py |
主要需要修改的地方有下面这些:
(1) 一些大模型平台的API-key
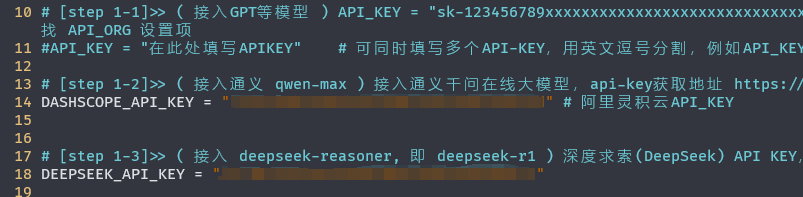

(2)可访问的模型名称。这些模型名称在配置前,需要仔细检查大模型平台文档,确定可调用的模型名称。

(3)网页服务运行的端口号。这里默认是-1,即每次随机一个端口。考虑到在云服务器上部署时,随机端口很不方便,因此这里我们人为的分配一个端口。此处我给分配的是8070端口,其他端口当然也是可以的。
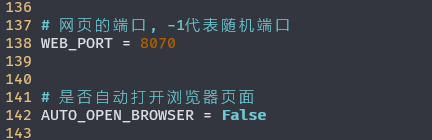
其他的地方可以按需修改。
3.3 配置 request_llms/bridge_all.py
这里其实算是比较geek的修改内容了。前面在配置 AVAIL_LLM_MODELS 时,我们填写进去了一些比较新的模型,这些模型在原版的gpt academic服务端中并不支持(如qwen-plus,qwen-turbo,以及基于阿里百炼平台的deepseek-v3等等),因此在这里需要添加一个转发路由,保证当前端用户选择了这些模型时后台能够正确处理。
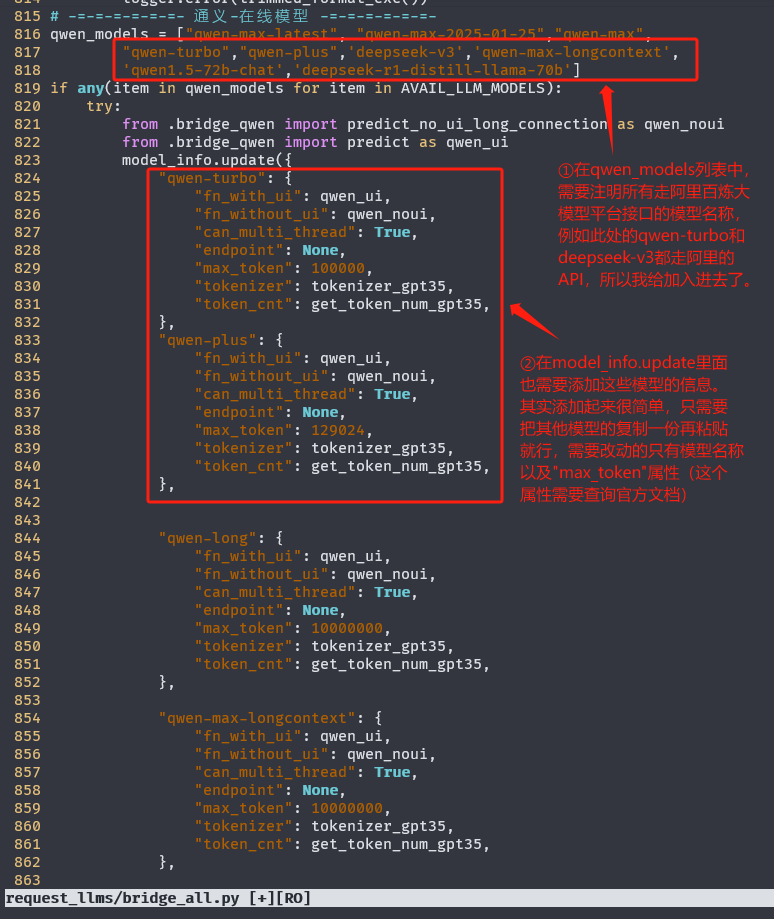
如上图,这是走阿里百炼平台API的模型转发路由的修改方法。
其他大模型平台的转发路由同理。
4. 启动
1 | python main.py |

如果有上面这样的输出,表明服务正常启动。
让我们打开浏览器看看效果:
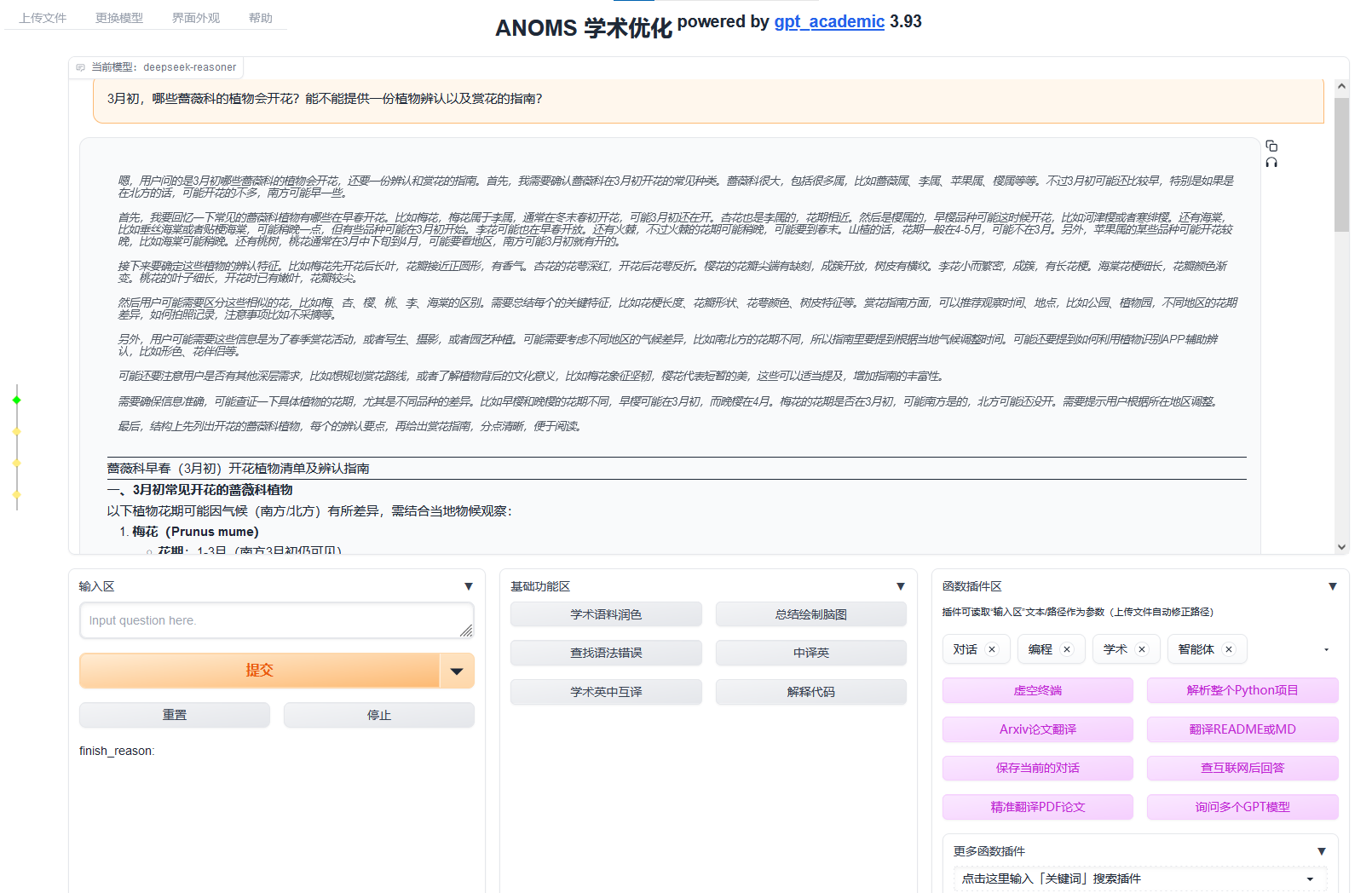
以上。