本地部署DeepSeek-R1(1.5b)模型
春节假期忙于各种家庭事务,没太多精力打理博客。前段时间被安利了DeepSeek-R1模型,被模型表现惊艳到了,于是也在空闲时间稍稍探索了一下本地部署的方法。
一、背景介绍
(一)DeepSeek-R1
DeepSeek,今年年初引爆舆论的大模型,来自杭州的量化基金公司幻方量化(这家低调的量化交易公司曾经“无意间”囤积了大量的GPU,颇有种高筑墙广积粮的风范)。
DeepSeek到目前为止已经发布了3个大版本(v1,v2,v3),其中2024年12月25日发布的V3版本一经发布就引起了国际范围的轰动,因为它在多个参数上,击败了 OpenAI 公司最新的 o1 模型。而且,它的运行效率很高,训练成本估计只有 Meta 公司的 Llama 3.1 405B 模型的11分之一。
DeepSeek-R1是基于V3的、带思维链(Chain-of-Thought, CoT)的模型,通过强化学习(RL)和蒸馏技术提升推理能力。在思维链的加持下,其有更强大的表现。
DeepSeek模型已在Github开源,可以在下面这些存储库中查看:
(二)ollama
Ollama是一个强大的本地大语言模型运行框架,它让用户能够在本地设备上轻松运行和管理各种大语言模型。其支持Windows,Linux和macOS。

(三)模型蒸馏
大模型蒸馏技术是一种将大型模型(教师模型)的知识迁移到小型模型(学生模型)的高效方法,旨在保留大模型性能的同时降低计算和存储成本。
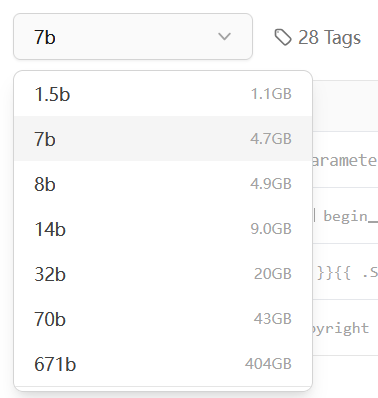
对于DeepSeek-R1的本地模型来说,其提供了从1.5b到671b不等的多个规模的模型,其中671b模型是原始模型,而其余小模型是从原始模型蒸馏而来。DeepSeek-R1 的蒸馏过程通过 软标签引导、中间层特征对齐 和 动态训练策略,在保留 Qwen/LLaMA 基础架构的同时,将全量版模型的复杂知识压缩至小模型中。其核心是通过多粒度知识迁移(从 token 级到序列级)和模型结构适配,在参数量减少的情况下最大化性能保留。这一技术路线与 TinyBERT、DistilBERT 等经典工作一脉相承,但针对生成式 LLM 的特点进行了扩展优化。
由于笔者的电脑内存限制,下文中将以最小的1.5b模型为例展示如何进行本地部署。
二、本地部署DeepSeek-R1(1.5b)模型步骤
(一)安装ollama
在ollama下载页面上下载安装包。
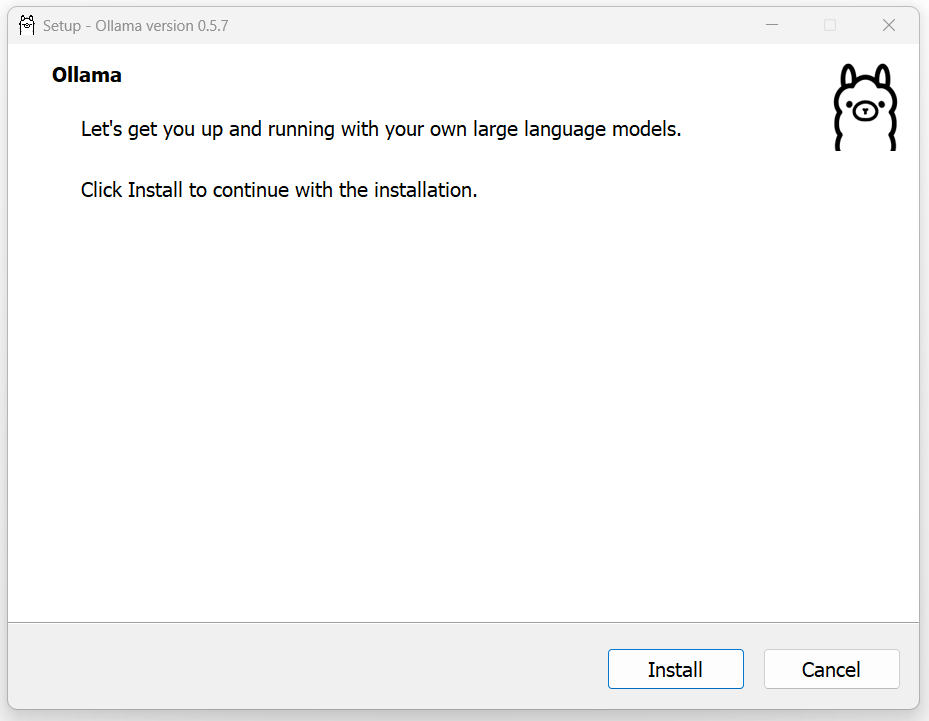
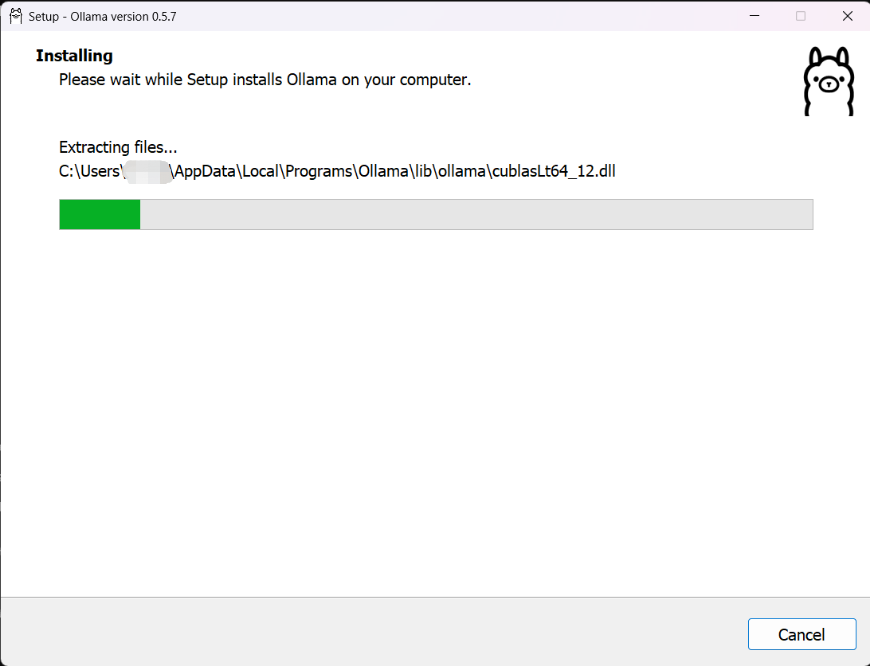
打开安装包,直接点击install进行安装。以Windows为例,ollama不支持修改安装路径,其默认会将可执行文件解压缩到 C:\Users\<username>\AppData\Local\Programs\Ollama 下,安装结束后其会将可执行文件添加到环境变量当中,从而允许我们在命令行中使用 ollama 指令调用这一应用。
(二)使用ollama部署DeepSeek-R1本地版模型
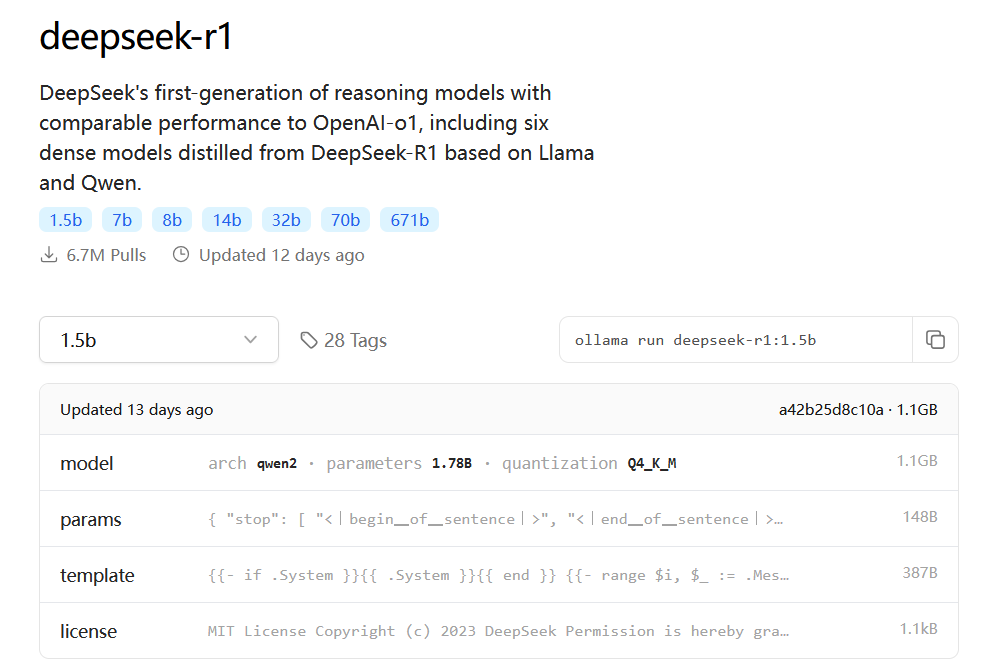
我们回到ollama的官网。在这里,我们搜索DeepSeek-R1,可以进入这一模型的模型介绍界面,如下图。在这里我们选择1.5b的模型,在页面右上角就会显示出部署这一模型需要用到的指令(此处为 ollama run deepseek-r1:1.5b )。
我们打开命令行(cmd,或者powershell,或者windows terminal),执行上述指令,就会开始模型文件的下载(如下图)。当模型下载完成,屏幕上显示出 >>> 提示符时,说明模型部署完成,可以开始聊天了。

(三)使用
直接运行 ollama run deepseek-r1:1.5b 即可启动模型对话框。在这里输入问题,回车以后就可以得到回答。
1.5b的小模型,响应速度还是很快的,大约能够做到每秒5-10字左右。从下图中可以看到,deepseek-r1在生成内容时,首先会在 <think></think> 标签之间开展思考过程,在思考结束以后会给出更为正式的回答。
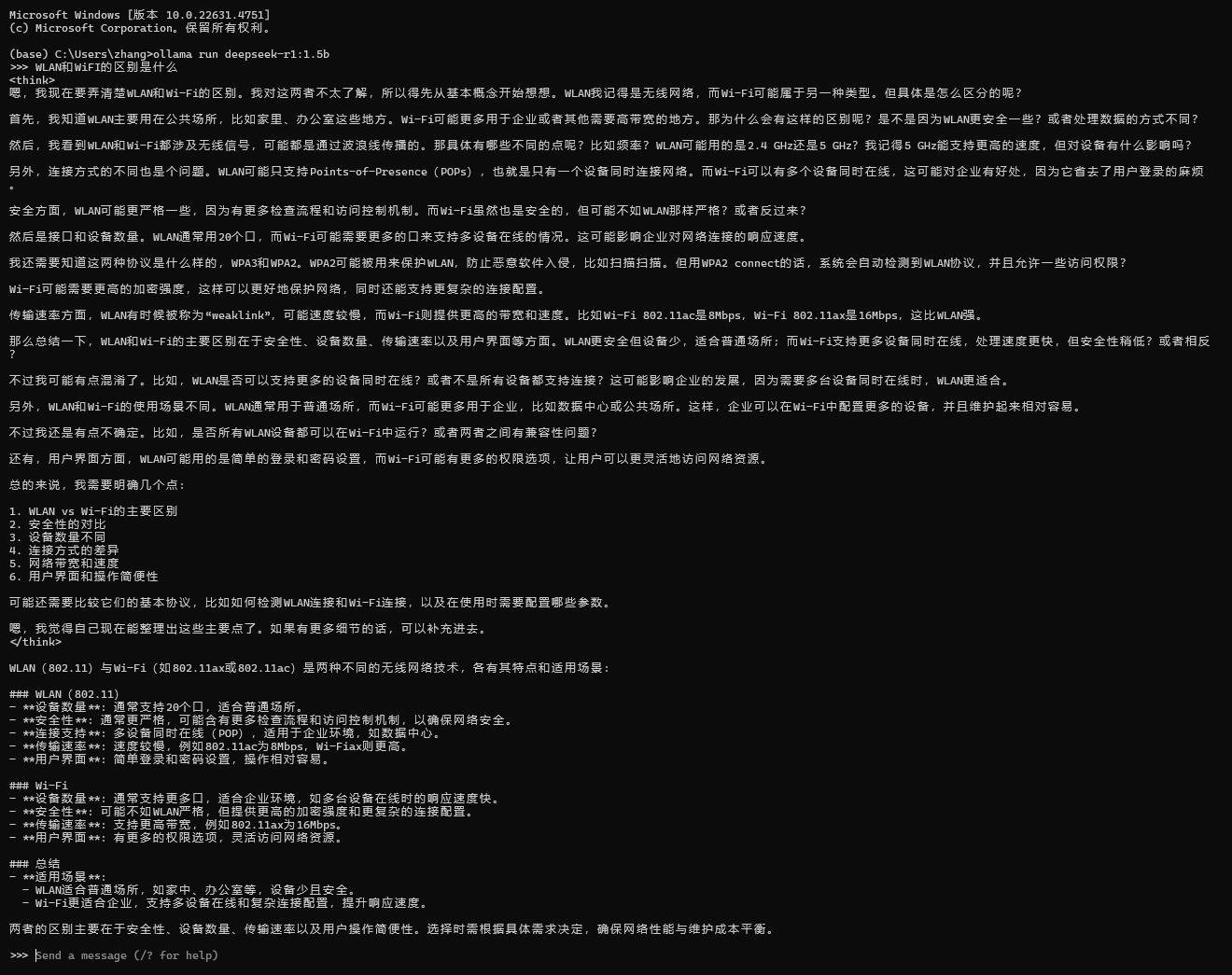
也可以使用 /? 查看ollama的命令行程序帮助,ollama支持通过指令清空历史聊天记录、设置模型参数等。
1 | >>> /? |
以上。