编程语言的类加载机制:以python为例
这篇文章的起源是这样的。前段时间,eGPS 项目组的ydl师兄在修bug的时候遇到了Java类加载机制的问题,于是进行了一番探索,并在群里分享了他的学习心得 。随后,师兄提出让我写一写python类加载机制方面的内容。遂,利用空余时间查了点资料,形成了这样一篇文章。

先来回答师兄的问题:python的namespace是什么。
命名空间 (Namespace) 是 Python 中用于存储符号名称到对象的映射的一种系统。在 Python 中,每个模块、函数调用以及类定义都会创建一个新的命名空间。命名空间确保了不同作用域内的变量名不会冲突。(另外参考下面通义千问的解释)

接下来,我们再依次介绍python的模块和软件包、python的类加载机制,最后我们还会把python与其他软件的类加载机制做一下比较。
一、Python的模块和软件包
我们需要区分两个概念:模块(module)、软件包(package)
- 模块(Module) :模块是一个包含 Python 定义和语句的文件,其扩展名为
.py。每个 Python 文件可以被认为是一个模块,它可以定义函数、类和变量等。 - 软件包(Package) :包是模块的集合,它提供了层次结构来组织模块。包通常存在于一个目录中,并且该目录中有一个名为
__init__.py的文件。通过这种结构,我们可以创建子包和子模块,形成树状结构。
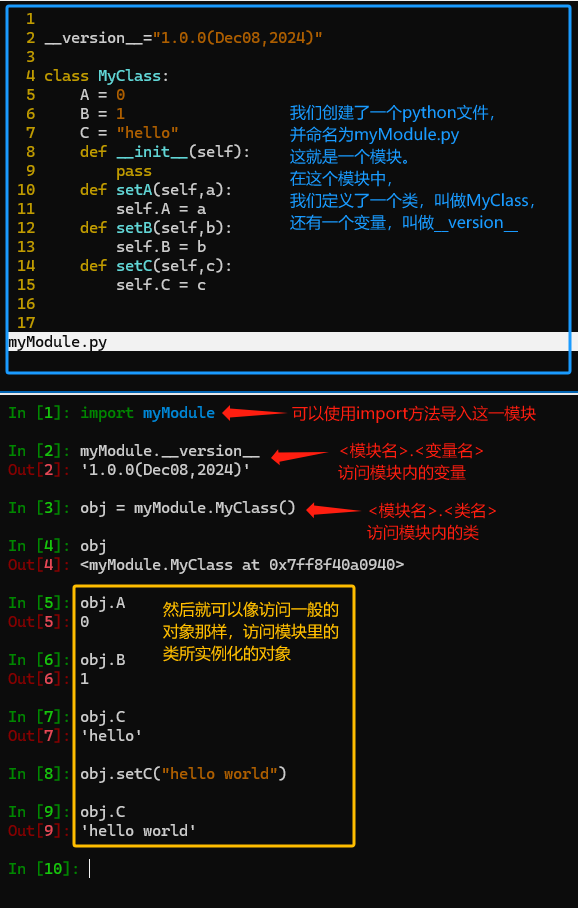
下图中我们展示了一个模块的定义方法,它本质上就是一个python文件。某种意义上,任何python文件都可以看作一个模块。
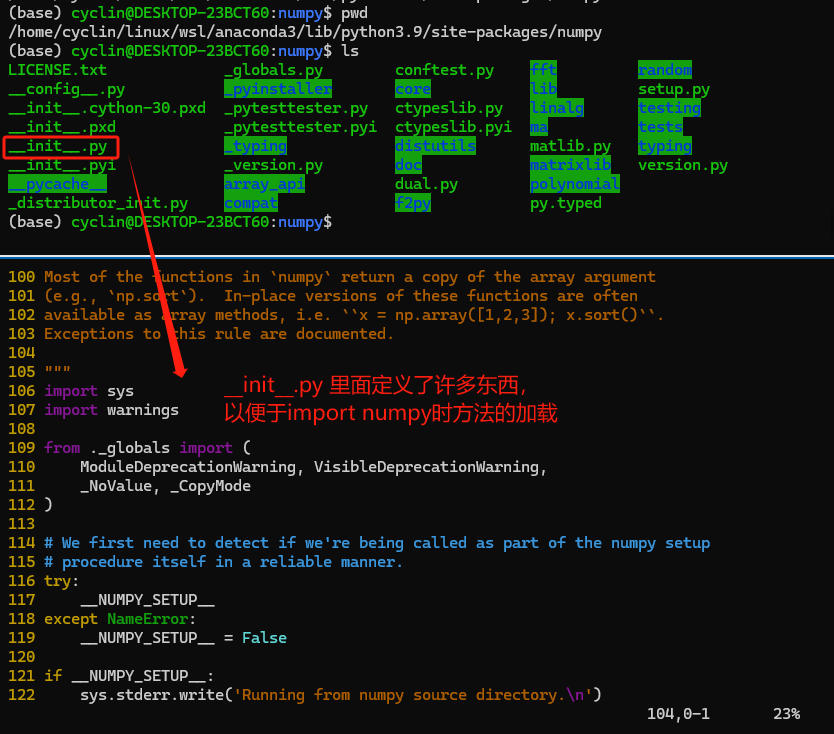
下图则展示了一个python软件包的结构(以numpy库为例)。可以看到,numpy软件包本质上是一个目录,其内部还有许多python文件和子目录。其中的 __init__.py 文件通常用于包的初始化操作,比如设置包级别的变量、注册包内的模块或类、执行必要的检查等,它会在包被首次导入时自动执行。
二、当我们import一个软件包时发生了什么
当我们在 Python 中使用 import 语句导入一个模块或包时,Python 内部会经历一系列步骤来解析和加载该模块或包。
首先是软件包的存储路径搜索。 正如前面我们所说,(除了内部模块以外)所有的模块和软件包本质上都是python文件或存放python文件的目录,因此要加载这些包,就需要找到它们的存储位置。首先,Python 会检查是否请求的是一个内置模块(例如 sys 或 math),这些模块是用 C 编写的,并且直接编译进了 Python 解释器中。如果请求的不是内置模块,Python 将根据 sys.path 列表中的路径顺序来查找模块文件。
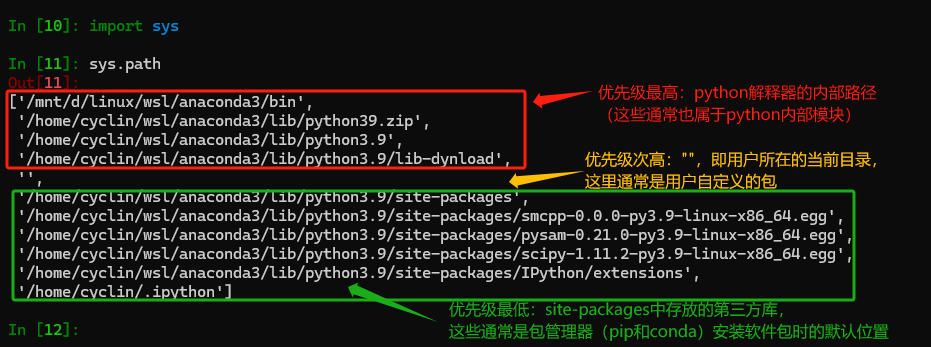
在python中定义了一个 sys.path 的内部变量(如下图),其指定了python将按照何种路径搜索文件系统以寻找模块和包(因为是按顺序搜索的,所以当正在import的包在多个位置都存在时,python只会import最先找到的那一个)。如果import的是一个软件包,Python 还会递归地在子目录中查找,特别是那些包含 __init__.py 文件的目录(对于 Python 3.3 及以上版本,这个文件不是必须的)。每个这样的目录被视为一个包,允许进一步嵌套。
此外,Python 支持虚拟环境(virtual environments),它可以帮助隔离项目依赖关系,减少不同项目之间模块版本冲突的可能性。通过创建独立的虚拟环境,可以为每个项目维护一套独立的库和工具链。
一旦找到了模块或包,Python 会进行模块或包的加载过程。 具体来说,会执行以下操作:
- 缓存检查:Python 首先会在内部的模块缓存(
sys.modules字典)中查找模块名。如果已经加载过,则直接返回缓存的模块对象,而不会再次加载。 - 读取源代码:如果没有找到缓存,Python 会读取模块或包对应的
.py文件的内容。 - 编译字节码:然后将读取到的源代码编译成字节码。对于模块,这通常会产生一个
.pyc文件存储在__pycache__目录下,以便下次更快加载。 - 执行模块代码:接下来,Python 执行编译后的字节码,初始化模块级别的变量、函数和其他定义,并创建模块对象。
- 注册模块:最后,新创建的模块对象被添加到
sys.modules字典中,以供后续引用。
区分几种import语句
另外,在日常实践中,我们通常会用到下面几种语句: import xxx , import xxx as zzz , from xxx import yyy , from xxx import * 。 这里也顺便讲一下它们的区别:
- 使用
import xxx时,我们实际上是将整个模块作为一个对象导入到了当前的命名空间。这意味着需要使用xxx.yyy来访问模块xxx中的成员yyy,因为xxx是模块对象,而yyy是该模块内的一个属性或函数。 -
import xxx as zzz和import xxx本质上是一样的,只不过这里对模块做了一下重命名操作,将其从xxx重命名为zzz以便我们访问。这种情况很多见,例如import numpy as np,import pandas as pd等等,以至于np和pd几乎已经成为了numpy和pandas的固定缩写词。 - 使用
from xxx import yyy则是只将yyy这个特定的成员从模块xxx中导入到当前的命名空间。因此,我们可以直接使用yyy而不需要前缀xxx.,因为我们已经把yyy引入到了局部或全局命名空间。 -
from xxx import *和from xxx import yyy本质上一样,只不过*通配符会匹配所有的公共成员,因此这句话会将模块xxx中所有公共成员(即,不以下划线开头的成员)都导入到当前命名空间。
类加载过程的定制
此外,python还提供了一个内部模块 importlib 允许用户对模块的加载过程进行一些定制和干预,例如在运行时动态加载类(根据用户输入动态加载不同的模块),或者开发过程中热更新类(不重启程序的情况下更新代码)。这些功能可以通过 importlib.import_module(module_name) 和 importlib.reload(module) 来实现,更详细的介绍可以参考 《Python类加载机制详解:深入理解ClassLoader的工作原理与应用场景》 。
三、对比:R/java/js等语言的类加载机制,以及C/C++的include语句
R语言
师兄说,「R的类加载机制是一个 enviroment 变量」,这其实指的是R语言的 s4 面向对象系统。在 R 中,主要的面向对象系统包括 S3 和 S4 。对于 S4 类,有一个特殊的环境(environment),它用来存储关于该类的信息,包括方法和属性。这个环境实际上就是一种哈希表结构,可以快速查找和访问类相关的数据。当使用 setClass() 函数创建新的 S4 类时,会生成一个新的环境来保存这些信息。此外,S4 支持通过 setMethod() 来绑定方法到泛型函数,这种绑定是在类环境中完成的,确保了方法与类之间的紧密联系。
相比之下,S3 是一个非常简单的 OOP 系统,它并不提供正式的类定义或方法绑定机制。相反,它依赖于约定和命名惯例来实现多态性。具体来说:
- 类标记:在 S3 中,一个对象可以通过设置其
class属性来被赋予“类”。例如,attr(x, "class") <- "myClass"会将对象x标记为myClass类型。 - 泛型函数:S3 使用泛型函数(generic functions)来实现多态行为。这些函数通常有一个默认的方法,以及针对特定类的特殊方法。比如,
print()函数可以有不同的实现方式,具体取决于传递给它的对象所属的类。 - 方法查找:当调用一个泛型函数时,R 会检查参数对象的
class属性,并尝试找到与该类相匹配的方法。如果找不到,则回退到更通用的方法。这个过程是动态的,在运行时进行。 - 没有明确的类环境:与 S4 不同,S3 并不维护专门的环境来存储类信息。所有方法都是全局定义的,并且通过命名惯例(如
myGeneric.myClass)关联到特定的类上。
然后就是R语言的类加载过程(参考通义千问的回答):

Java
在 Java 中,类加载是一个动态的过程,它由 JVM(Java 虚拟机)执行。JVM 使用类加载器(ClassLoader)来加载类文件到内存中。类加载器分为三种主要类型:引导类加载器(Bootstrap ClassLoader)、扩展类加载器(Extension ClassLoader),以及应用程序类加载器(Application ClassLoader)。类加载遵循父委托模型,即首先尝试通过父类加载器加载类,如果找不到,则使用子类加载器。
JavaScript
对于 JavaScript,在浏览器环境中,没有传统意义上的“类加载”概念,因为代码通常直接嵌入网页中或以 <script> 标签的形式引入。然而,随着 ES6 引入了模块系统,现在可以通过 import 和 export 语句来导入和导出模块。Node.js 环境下,也支持类似的模块化编程,并且有 CommonJS 模块格式,它使用 require() 函数来加载模块。此外,还有动态 import() 表达式,允许按需加载模块。
.NET (如 C# ,VB.NET , F#)
.NET 平台上的类加载是通过 CLR(公共语言运行时)完成的。CLR 负责管理应用程序的执行,包括 JIT 编译、内存分配、垃圾回收等。当程序启动时,CLR 加载程序集(Assembly),其中包含元数据和中间语言(IL)代码。程序集可以包含多个类。CLR 在需要时即时编译 IL 代码为本机代码,并确保类型安全性和安全性。
C/C++ 的 #include
C 和 C++ 使用预处理器指令 #include 来包含头文件中的定义和声明。这实际上是 在编译阶段发生的文本替换操作 ,即将指定文件的内容插入到当前源文件的位置。这个过程不是动态的,所有必要的代码都必须在编译前准备好,并且会被直接编译进最终的可执行文件或库中。因此,C/C++ 中并没有像 Java 或 .NET 那样的运行时类加载机制。