如题。
因为工作需要,要从GEO数据库上批量下载一些数据集文件。鉴于手动下载文件太麻烦,于是折腾出这样一个用来批量下载文件的python脚本。
一、背景知识 (一)HTML 超文本标记语言(HTML, HyperText Markup Language)是用于创建网页的标准标记语言。HTML 文档由一系列的元素组成,每个元素都以标签的形式存在,这些标签定义了文档的结构和内容展示方式。例如,<p> 标签用于表示一个段落,<img> 标签用于嵌入图像,而 <a> 标签则用来创建超链接。
当浏览器加载一个网页时,它解析HTML代码并根据其中的标签将内容呈现给用户。了解HTML对于理解网页的构造至关重要,这不仅有助于开发者构建网站,也是进行网络数据抓取时不可或缺的知识。
(二)Python Requests库:简化HTTP请求 Python 是一种广泛使用的高级编程语言,以其简洁清晰的语法和强大的功能库而闻名。在进行网络数据抓取时,requests 库是Python社区中非常流行的一个第三方库,它提供了简单易用的API来发送HTTP/1.1 请求。
使用 requests 库,开发者可以通过几行代码轻松发起GET或POST请求,获取远程服务器的数据。该库内部实现了对HTTP协议的支持,包括处理连接、发送请求头、接收响应等操作,并且能够自动处理一些常见的HTTP特性,如重定向、身份验证和会话管理。
在本文中,我们将介绍如何结合HTML知识与Python requests 库开发一款用于GEO数据集下载的小工具,演示如何高效地抓取网络资源。
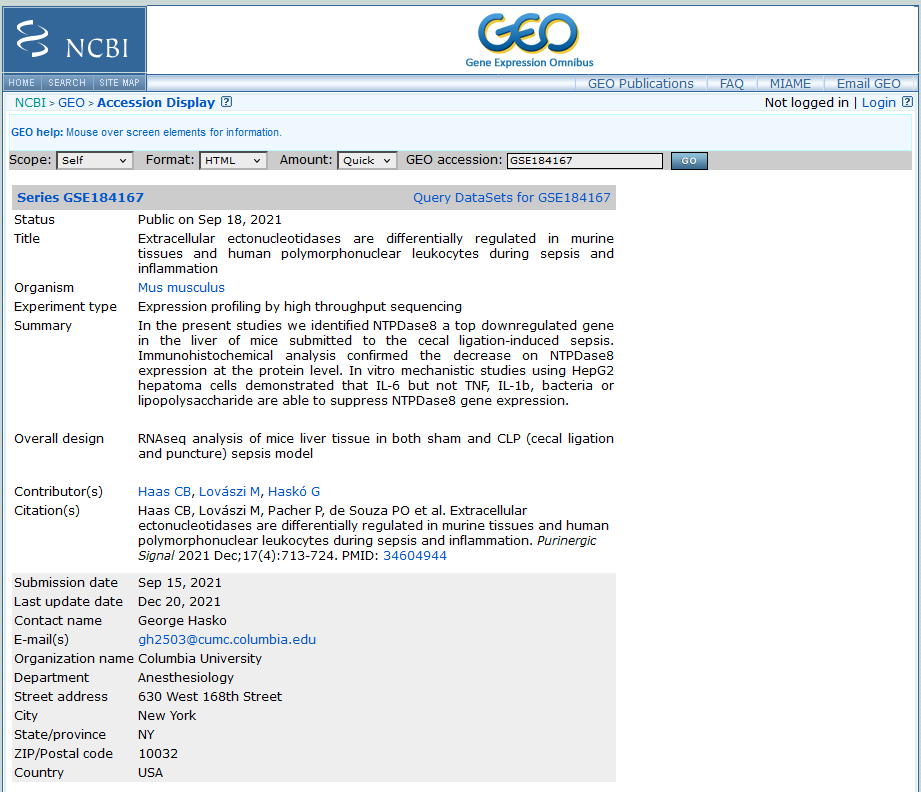
二、GEO数据库的页面解析 对于GEO数据库来说,其页面大致如下图所示(随便举一个GEO数据集的例子):
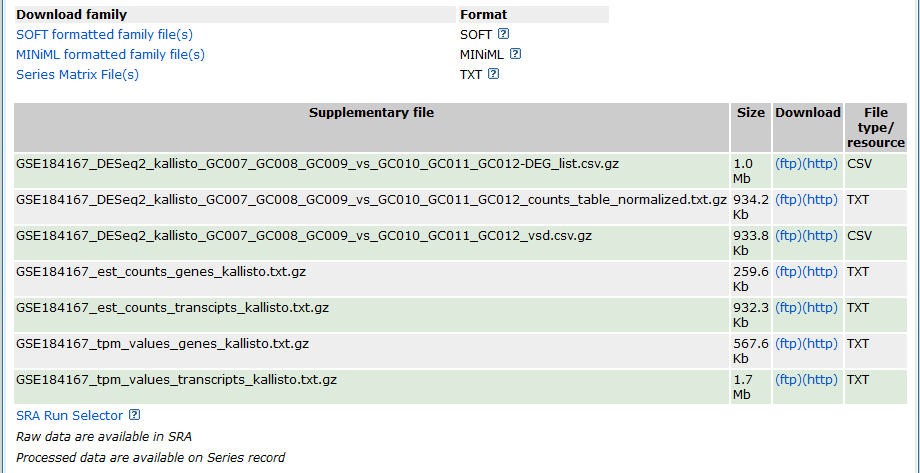
其中的附件会以下面这样的超链接形式列出:
对我们来说,最重要的其实不是这个页面本身,而是这个页面提供的文件下载超链接。
仍然以上述GEO数据集为例,其supplementary file列出的几个文件的FTP下载链接依次如下:
1 2 3 4 5 https://ftp.ncbi.nlm.nih.gov/geo/series/GSE184nnn/GSE184167/suppl/GSE184167%5FDESeq2%5Fkallisto%5FGC007%5FGC008%5FGC009%5Fvs%5FGC010%5FGC011%5FGC012%2DDEG%5Flist%2Ecsv%2Egz https://ftp.ncbi.nlm.nih.gov/geo/series/GSE184nnn/GSE184167/suppl/GSE184167%5FDESeq2%5Fkallisto%5FGC007%5FGC008%5FGC009%5Fvs%5FGC010%5FGC011%5FGC012%5Fcounts%5Ftable%5Fnormalized%2Etxt%2Egz https://ftp.ncbi.nlm.nih.gov/geo/series/GSE184nnn/GSE184167/suppl/GSE184167%5FDESeq2%5Fkallisto%5FGC007%5FGC008%5FGC009%5Fvs%5FGC010%5FGC011%5FGC012%5Fvsd%2Ecsv%2Egz https://ftp.ncbi.nlm.nih.gov/geo/series/GSE184nnn/GSE184167/suppl/GSE184167%5Fest%5Fcounts%5Ftranscipts%5Fkallisto%2Etxt%2Egz ......
这几个文件的超链接都指向了一个共同的URL,既 https://ftp.ncbi.nlm.nih.gov/geo/series/GSE184nnn/GSE184167/suppl/ ,在此URL之后则跟上的是几个文件各自的文件名。因此这给我们提供了一个思路,或许我们可以解析这个URL,获取各个文件的下载链接。
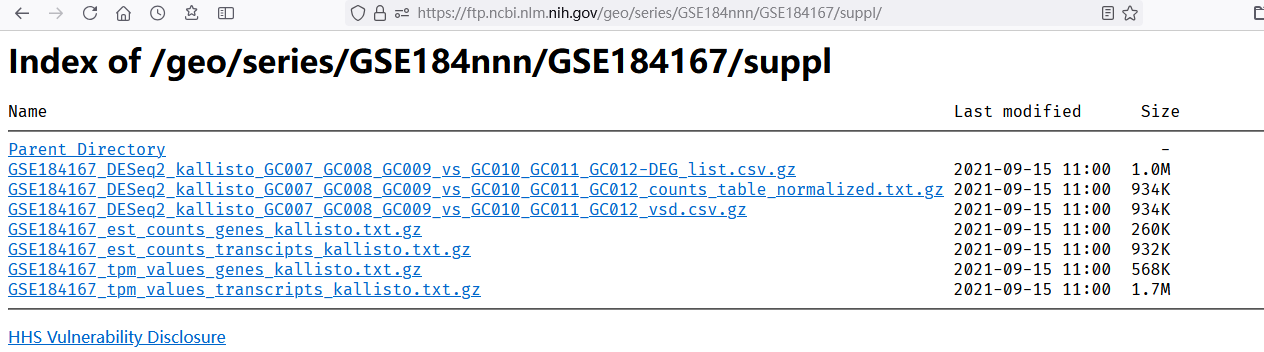
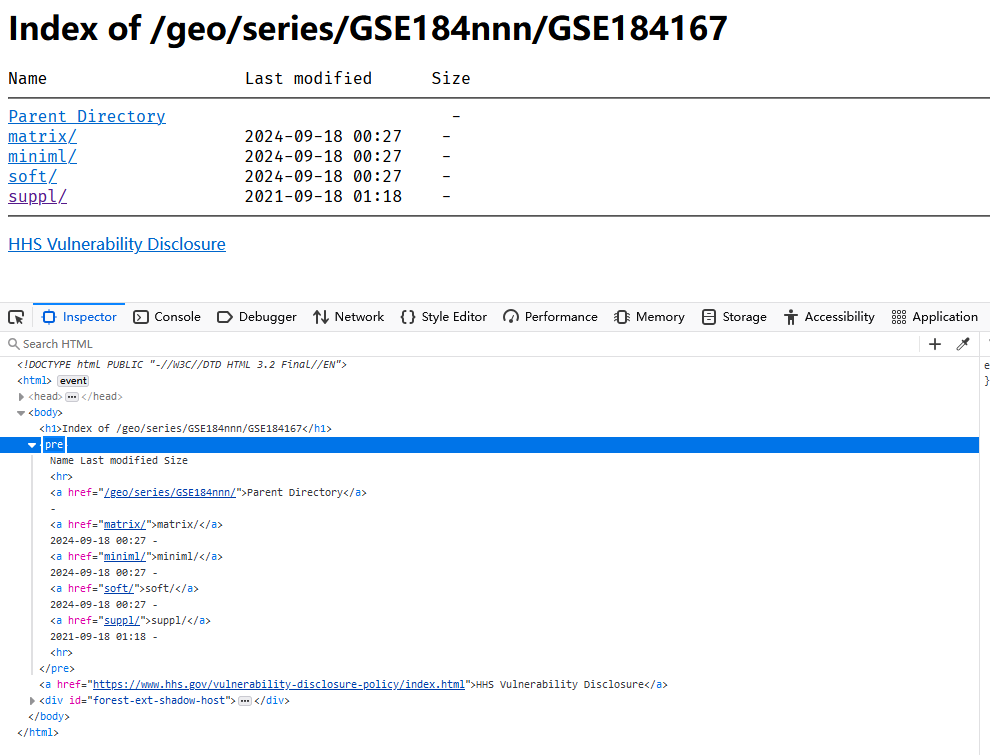
上述URL对应的页面如下:
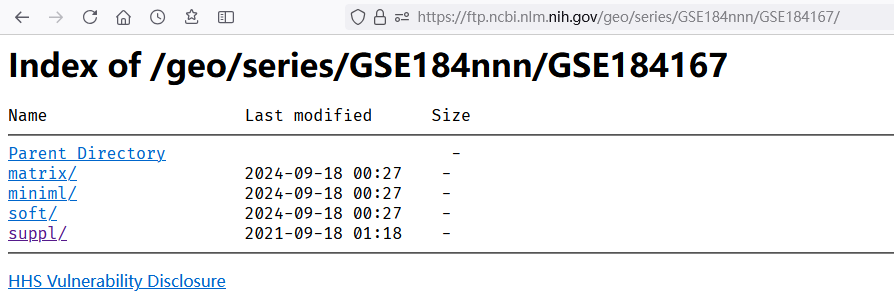
继续点开上一级目录(“Parent Directory”按钮):
通过这样的操作,我们大致就能够知道GEO的这个FTP站点是如何存储数据集文件的:
根目录是 https://ftp.ncbi.nlm.nih.gov/geo/series/<GEO part number>nnn/<GEO number>/
(其中 <GEO part number> 是GEO识别号的前6个字符,例如如果GEO号是 GSE184167 ,那么 <GEO part number> 就是 GSE184)
其下面有 matrix, miniml, soft, suppl 四个目录,分别存储不同的文件。
各个目录下面是文件下载的链接。
我们可以在浏览器界面中按下键盘上的F12按钮查看网页源代码,其大约长这个样子:
整个网页的结构是一个<body>标签内嵌一个 <pre> 标签,<pre> 标签又内嵌了多个 <a> 标签,<a> 标签内即为下一级目录的链接,或文件下载链接。
三、GEOdown工具的编写 (一)思路 给定一个GEO识别号,我们就可以获得根目录的URL。接下来,我们从根目录识别各个子目录的链接,并解析子目录的内容,获得各个文件的链接,并调用系统的 curl 指令进行下载。
curl 指令在下载文件时的使用方法: curl -OJX GET <url> 。
(二)识别根目录内容 代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import osimport sysfrom urllib import requestdef exec (cmd ): os.system(cmd) def geo_root_page_process (GEO ): if (sys.platform=="win32" ): exec ("mkdir {}" .format (GEO)) else : exec ("mkdir -p {}" .format (GEO)) os.chdir(GEO) url_prefix = "https://ftp.ncbi.nlm.nih.gov/geo/series/{}nnn/{}/" .format (GEO[0 :-3 ],GEO) sub_dir_ls = geo_common_page_process(url_prefix) for d in sub_dir_ls: file_ls = geo_common_page_process(url_prefix+"/" +d) download(url_prefix,file_ls,d) os.chdir(".." )
(三)识别子目录内容,并下载文件 代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 def download (url_prefix,file_ls,dir_name ): if (sys.platform=="win32" ): exec ("mkdir " +dir_name.replace("/" ,"\\" )) else : exec ("mkdir -p " +dir_name) os.chdir(dir_name) for f in file_ls: url = url_prefix+"/" +dir_name+"/" +f print (url) exec ("curl --insecure -OJX GET \"" +url+"\"" ) os.chdir(".." ) def geo_common_page_process (url ): res = request.urlopen(url) txt = res.read().decode() start_pos = txt.index("<pre>Name" ) end_pos = txt.index("<hr></pre>" ) txt1 = txt[start_pos:end_pos].strip().split("\n" ) href_ls = [] for href_txt in txt1[1 :]: href = href_txt.split()[1 ].replace("</a>" ,'' ).split(">" )[1 ] if (href=='Parent Directory' ):continue href_ls.append(href) return href_ls
(四)主函数 1 2 3 4 5 6 7 8 9 10 if (__name__=='__main__' ): usage="""Usage: python GEOdown.py <GEO> """ if (len (sys.argv)<2 ): print (usage) sys.exit(1 ) GEO = sys.argv[1 ] geo_root_page_process(GEO)
(五)完整代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 import osimport sysfrom urllib import requestdef exec (cmd ): os.system(cmd) def download (url_prefix,file_ls,dir_name ): if (sys.platform=="win32" ): exec ("mkdir " +dir_name.replace("/" ,"\\" )) else : exec ("mkdir -p " +dir_name) os.chdir(dir_name) for f in file_ls: url = url_prefix+"/" +dir_name+"/" +f print (url) exec ("curl --insecure -OJX GET \"" +url+"\"" ) os.chdir(".." ) def geo_common_page_process (url ): res = request.urlopen(url) txt = res.read().decode() start_pos = txt.index("<pre>Name" ) end_pos = txt.index("<hr></pre>" ) txt1 = txt[start_pos:end_pos].strip().split("\n" ) href_ls = [] for href_txt in txt1[1 :]: href = href_txt.split()[1 ].replace("</a>" ,'' ).split(">" )[1 ] if (href=='Parent Directory' ):continue href_ls.append(href) return href_ls def geo_root_page_process (GEO ): if (sys.platform=="win32" ): exec ("mkdir {}" .format (GEO)) else : exec ("mkdir -p {}" .format (GEO)) os.chdir(GEO) url_prefix = "https://ftp.ncbi.nlm.nih.gov/geo/series/{}nnn/{}/" .format (GEO[0 :-3 ],GEO) sub_dir_ls = geo_common_page_process(url_prefix) for d in sub_dir_ls: file_ls = geo_common_page_process(url_prefix+"/" +d) download(url_prefix,file_ls,d) os.chdir(".." ) if (__name__=='__main__' ): usage="""Usage: python GEOdown.py <GEO> """ if (len (sys.argv)<2 ): print (usage) sys.exit(1 ) GEO = sys.argv[1 ] geo_root_page_process(GEO)
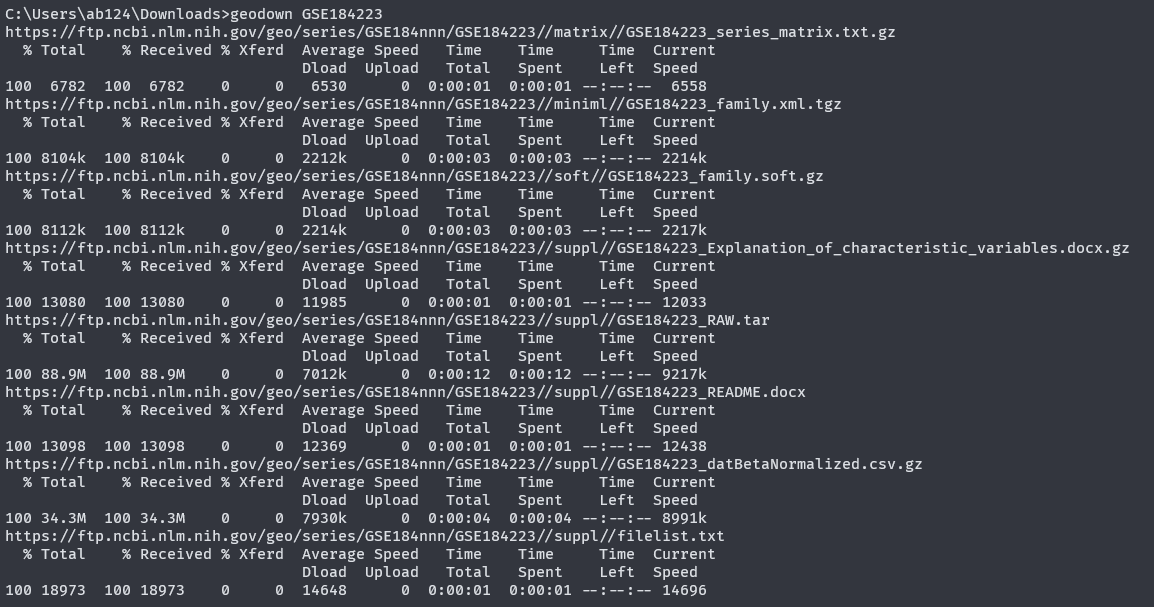
(六)使用方法 这样就可以批量下载一个GSE数据集的文件了。
效果如下:
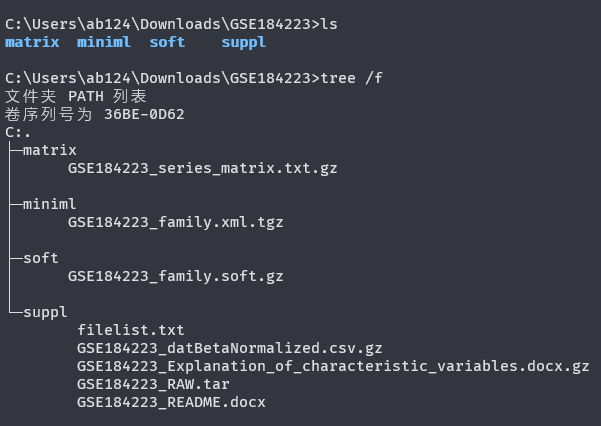
文件列表如下:
以上。