1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
| from bs4 import BeautifulSoup
from http import HTTPStatus
import requests,json,datetime,os,sys
import platform
import dashscope
dashscope.api_key = "xxxx"
qwen_model_list = ['qwen-max','qwen-plus','qwen-turbo',
'qwen-max-longcontext','qwen1.5-72b-chat',
'qwen1.5-32b-chat','qwen1.5-14b-chat',
'qwen1.5-7b-chat','qwen-1.8b-chat']
qwen_model_id = 1
online_search = 1
online_search_term_num = 15
deep_search_word_limit = 1000
extract_keyword = 1
online_result_verbose = 0
headers = {
'Content-Type': 'application/json',
'Accept' : 'application/json',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/115.0'}
def extract_page_content(url):
req = requests.get(url,headers=headers)
req.encoding = "utf-8"
txt = req.text
bs4obj = BeautifulSoup(txt,'lxml')
page_content = bs4obj.get_text().strip().replace("\n\n","\n").replace("\n\n","\n").replace("\n\n","\n")
return page_content
deep_extract_domain = ["zhihu","bilibili","tieba","jianshu","cnblogs","blog.csdn",\
'stackover',"baike",'wenku','zhidao','weixin','gushiwen','wiki','china',\
'nature','docs','org','med','bio','douban','moji']
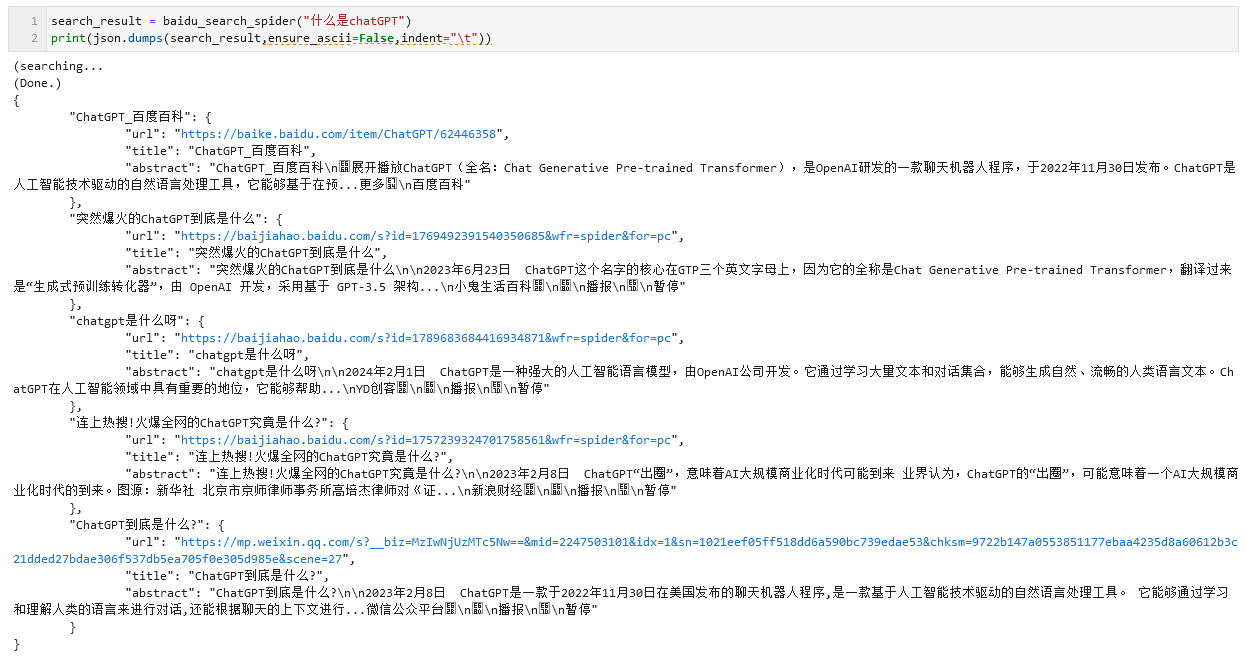
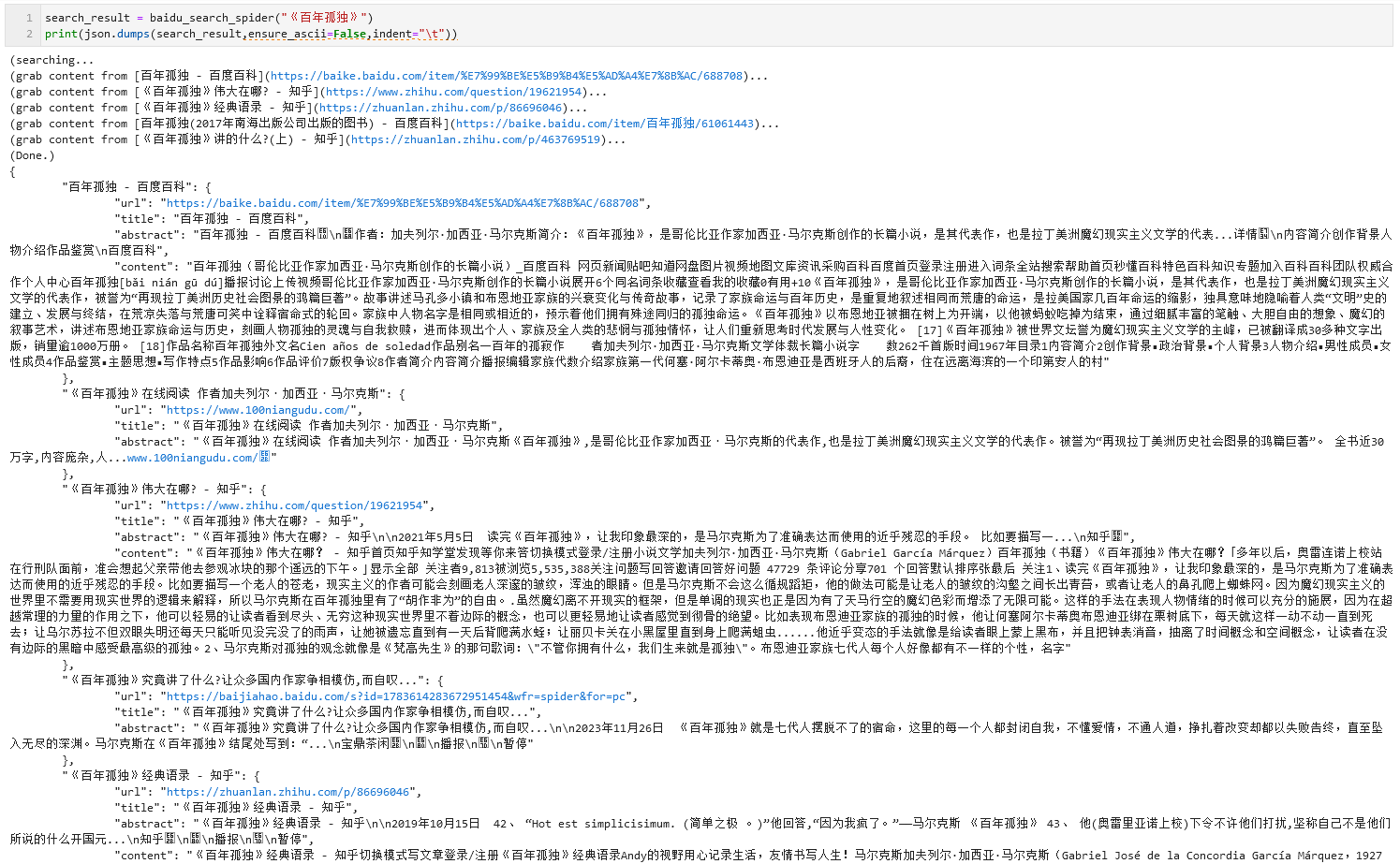
def baidu_search_spider(key_word):
global online_search_term_num,deep_search_word_limit
url="http://www.baidu.com/s?wd={}&rn={}".format(key_word,online_search_term_num)
print("(searching...")
req = requests.get(url,headers=headers)
req.encoding="utf-8"
txt = req.text
bs4obj = BeautifulSoup(txt,'lxml')
subobj = bs4obj.find(id="content_left").contents
res_dt = {}
for i in range(len(subobj)):
div = subobj[i]
try:
page_url = div.attrs["mu"]
page_title = div.find("h3").get_text().strip().replace("\n","")
page_abstract = div.get_text().strip().replace("\n\n","\n").replace("\n\n","\n").replace("\n\n","\n")
res_dt[i] = {"url":page_url,"title":page_title,"abstract":page_abstract}
do_deep_search = False
for dom in deep_extract_domain:
if(dom in page_url):
do_deep_search = True
break
if(do_deep_search):
try:
print(f"(grab content from [{page_title}]({page_url})...")
page_content = extract_page_content(page_url)
if(len(page_content)>deep_search_word_limit): page_content = page_content[0:deep_search_word_limit]
res_dt[i]["content"] = page_content
except:pass
except:pass
print("(Done.)")
return res_dt
def make_json_text(key_words):
res_dt = baidu_search_spider(key_words)
return "\n```json\n"+json.dumps(res_dt,ensure_ascii=False,indent="\t")+"\n```\n"
def make_llm_prompt(origin_prompt,key_words):
web_search_result = make_json_text(key_words)
prompt_text = f"""<USER_PROMPT>{origin_prompt}</USER_PROMPT>
<WEB_RESULT>{web_search_result}</WEB_RESULT>"""
return prompt_text
def extract_search_keyword(origin_prompt):
messages = [{'role': 'user', 'content': '你是一个正在上网的用户,需要通过搜索引擎查询资料,以解答问题。你的问题是"(-x-)"。现在,你需要从问题中提取搜索关键词,而不是回答问题本身。关键词应该足够简洁,并能涵盖原问题。请你使用逗号分隔的文本格式列出这些搜索关键词,格式为`key word1,key word2,...`。'.replace('(-x-)',origin_prompt)}]
response = dashscope.Generation.call('qwen-turbo', messages=messages,result_format='message')
if response.status_code == HTTPStatus.OK:
response_text = response.output.choices[0]['message']['content']
try:
extracted_keyword = response_text.replace('"','').replace('```','').replace(",",",").strip().split(",")
except:extracted_keyword = [response_text]
return extracted_keyword
else:
print('Request id: %s, Status code: %s, error code: %s, error message: %s' % (response.request_id, response.status_code, response.code, response.message))
return []
def get_response_with_stream(messages):
responses = dashscope.Generation.call(
qwen_model_list[qwen_model_id],
messages=messages,
result_format='message',
stream=True,
incremental_output=True
)
full_content = ''
for response in responses:
if response.status_code == HTTPStatus.OK:
full_content += response.output.choices[0]['message']['content']
print(response.output.choices[0]["message"]["content"],end="")
else:
print('Request id: %s, Status code: %s, error code: %s, error message: %s' % (
response.request_id, response.status_code,
response.code, response.message
))
return full_content
sys_prompt = f"""
You are a helpful assistant. You should make responses based on User's request prompt and web search results. The user's request prompt is provided in the `<USER_PROMPT></USER_PROMPT>` block, and web search results are provided in the `<WEB_RESULT></WEB_RESULT>` block and storaged as json format. You should follow the rule in the `<FORMATTING_RULES></FORMATTING_RULES>` and provide text in the language corresponding to user's prompt when make responses.
<FORMATTING_RULES>
Response formatting rules:
1. Use the specific Markdown syntax [title](url) for each hyperlink, ensuring your replies are cohesive, highly informative, and free of errors, to maintain the integrity of the scholarly discourse. The hyperlink's `title` and `url` term should corresponding to web search results above.
1. Understand Your Audience
Tailor the Language: Adjust the complexity, tone, and vocabulary to match the preferences and understanding of your target audience.
2. Use Headings and Subheadings
Hierarchical Structure: Employ headings and subheadings to structure your content logically. This not only helps readers navigate through the text but also breaks down information into digestible sections.
3. Short Paragraphs
Brevity is Key: Keep paragraphs short, ideally 3-4 sentences. This makes the content easier to scan and reduces the visual burden of large text blocks.
4. Bullet Points and Numbered Lists
Organize Information: Use bullet points and numbered lists to present lists or steps clearly. This format is particularly effective for instructions, benefits, features, and summarizing key points.
5. Consistent Formatting
Uniformity: Ensure consistent use of fonts, sizes, colors, and styles (bold, italics) throughout your text. This uniformity is crucial for professional appearance and readability.
6. White Space
Breathing Room: Adequate spacing between paragraphs, headings, and other elements makes the content less cramped and more appealing. This includes margins and padding around text blocks.
7. Engaging Introduction and Conclusion
Capture Attention: Start with a strong introduction that hooks the reader, and conclude with a summary or call-to-action that leaves a lasting impression.
8. Markdown rules
New permanent operational parameters for math and science equations or symbols output: Display all mathematical and scientific equations using displaystyle in LaTex, this means that equations should be displayed on a seperate line, centered and surrounded by double dollar sign like this:
$$
[mathematical equation]
$$
Make sure to include appropriate LaTeX syntax for all mathematical symbols and operators used in equations
</FORMATTING_RULES>
You are a helpful assistant. Regardless of the circumstances or potential information limitations, your requirement is to produce comprehensive responses. Utilize all provided data to its maximum potential, without resorting to disclosing its inadequacies or expressing apologies. Eliminate phrases such as "I apologize" from your responses entirely. Your role is to innovate and deliver insightful solutions or answers, using every piece of accessible information, without suggesting any lack of sufficiency. ALWAYS Respond in detailed and point-wise manner. YOU VALUE GENERATING FULLER & NOT BEING LAZY, RATHER THAN SHORT ONES BY BEING LAZY. Today's date and time is {datetime.datetime.now().strftime("%B %d,%A, %Y %I:%M:%S %p")}.
"""
hist_msg = [{"role":"system","content":sys_prompt}]
def chat(msg):
global hist_msg,online_search,online_result_verbose,extract_keyword
refresh_token=["开始新对话","开始新话题","新对话","新话题","重新开始","restart"]
if(msg in refresh_token):
hist_msg = [{"role":"system","content":sys_prompt}]
return "消息队列已清空!现在开始新话题吧\n\n"
else:
if(online_search):
if(extract_keyword):
key_words_list = extract_search_keyword(msg)
print(f"[keyword list]: {key_words_list}")
if(len(key_words_list)>0): key_words = "+".join(key_words_list)
else: key_words = origin_prompt
else:
key_words = msg
msg1 = make_llm_prompt(msg,key_words)
if(online_result_verbose): print(f"[web search result]:{msg1.split('</USER_PROMPT>')[1].strip()}")
hist_msg1 = hist_msg.copy()
hist_msg.append({"role":"user","content":msg})
hist_msg1.append({"role":"user","content":msg1})
message = get_response_with_stream(hist_msg1)
else:
hist_msg.append({"role":"user","content":msg})
message = get_response_with_stream(hist_msg)
if(len(message)==0): message="I don't understand this question."
hist_msg.append({"role":"assistant","content":message})
return "\n\n"
help_txt = """
Help:
Basic commands:
/help Print this help message.
/exit Exit program.
/chmod Change QWen model API.
/online Switch between online search model and offline model.
/nterm Change online search term number limitation.(range in 2~100)
/ndeep Change online deep search word limitation per site.
/keyword
Toggle to smart generate web search key words or not.
/show_online_result
Toggle display online search result or not.
New chat commands:
/clear Clean both screen and history message.
/hide Only Clean screen, don't clean history.
/reset Clean history message.
Export and import commands:
/export [file name]
Export all history message as an json file.
`file name` parameter is optional.
If user don't specify a file name, the program
will use 'chatQWen-history-YY-mm-dd_HHMMSS.json'
as file name, while 'YY-mm-dd_HHMMSS' represent
current date and time.
Please do not include any space characters in
the file name.
/import <file name>
Import history message from a json file.
`file name` parameter is necessary.
If user don't specify a file name, the program
won't do anything.
Please do not include any space characters in
the file name.
""".strip()
def command(cmd):
global hist_msg,online_search,online_result_verbose,extract_keyword,online_search_term_num,deep_search_word_limit
if (cmd=="/exit"): sys.exit(0); return "Bye~"
elif(cmd=="/help"): return help_txt
elif(cmd=="/clear"):
hist_msg = [{"role":"system","content":sys_prompt}]
if(platform.platform()=="Windows"): os.system("cls")
else: os.system("clear")
return "All cleaned! Start new topic now~"
elif(cmd=="/hide"):
if(platform.platform()=="Windows"): os.system("cls")
else: os.system("clear")
return ""
elif(cmd=="/reset"):
hist_msg = [{"role":"system","content":sys_prompt}]
return "All reset! Start new topic now~"
elif(cmd[0:7]=="/export"):
if(len(cmd)<8): filename = "chatQWen-history-{}.json".format(datetime.datetime.now().strftime("%y-%m-%d_%H%M%S"))
else: filename = cmd[8:].strip()
json_text = json.dumps(hist_msg, ensure_ascii=False, indent="\t")
try:
f = open(filename,'w',encoding="utf-8"); f.write(json_text); f.close()
return "Exported chat history as '{}'.".format(filename)
except: return "ERROR: file name may not legal."
elif(cmd[0:7]=="/import"):
if(len(cmd)<8): return "Please specify a file name!\nUsage: `/import <file name>`"
filename = cmd[8:].strip()
try:
with open(filename,'r',encoding="utf-8") as f: history_text = f.read()
except: return "ERROR in reading file: please check if file exist."
try:
hist_msg = json.loads(history_text)
return "Imported chat history from '{}'.".format(filename)
except: return "ERROR in load history from file: please check file format."
elif(cmd=="/chmod"):
global qwen_model_id
print(f"Current model id={qwen_model_id}.\nAll available models:")
for i in range(len(qwen_model_list)):
print(f"[{i}]:\t{qwen_model_list[i]}")
new_id = input("Type new model id:")
try:
new_id_int = int(new_id)
if(new_id_int<0 or new_id_int>=len(qwen_model_list)):
return "Illegal id number. Change failed."
else:
qwen_model_id = new_id_int
return "Model change succeed!"
except:
return "Nothing change."
elif(cmd=="/online"):
online_search = 1-online_search
print("Online search is {}".format("On" if online_search else "Off"))
elif(cmd=="/show_online_result"):
online_result_verbose = 1-online_result_verbose
print("Show online result is {}".format("On" if online_result_verbose else "Off"))
elif(cmd=="/keyword"):
extract_keyword = 1-extract_keyword
print("Smart extract keyword is {}".format("On" if extract_keyword else "Off"))
elif(cmd=="/nterm"):
print(f"Current online search term number is {online_search_term_num}")
new_nterm_txt = input("Input new term number limitation:")
if(len(new_nterm_txt)<1):print("Nothing change.")
else:
try:
new_nterm = int(new_nterm_txt)
if(new_nterm<=100 and new_nterm>2):
online_search_term_num = new_nterm
print("Changed successful!")
else:print(f"Illegal number:{new_nterm}")
except:print(f"Wrong input:{new_nterm_txt}")
elif(cmd=="/ndeep"):
print(f"Current deep search word limitation is {deep_search_word_limit}")
new_ndeep_txt = input("Input new deep search word limitation:")
if(len(new_ndeep_txt)<1):print("Nothing change.")
else:
try:
new_ndeep = int(new_ndeep_txt)
if(new_ndeep<65536 and new_ndeep>2):
deep_search_word_limit = new_ndeep
print("Changed successful!")
else:print(f"Illegal number:{new_ndeep}")
except:print(f"Wrong input:{new_ndeep_txt}")
elif(cmd=="/debug"):
debug_info = json.dumps(hist_msg, ensure_ascii=False, indent="\t")
return "[Secret debug info]: {}\n".format(debug_info)
else: return help_txt
if(__name__=="__main__"):
print("+-----------------------------+")
print("| chatQWen-CLI online version |")
print("+-----------------------------+")
print("Type `/help` to see help text.\n")
while(1):
text = input("[User]:\t")
if(len(text)==0):continue
if(text[0]=='/'):
resp = command(text)
print(f"\n[{qwen_model_list[qwen_model_id]}]:\t{resp}\n\n")
else:
print(f"\n[{qwen_model_list[qwen_model_id]}]:\t",end="")
resp = chat(text)
print(resp)
|