轻量级LaTeX环境安装与jupyter导出PDF的一些探索
通过R安装了TinyTeX这一LaTeX发行版,并探索了用其编译jupyter notebook的方法。
背景
参考:
TeX是一种基于宏的排版语言,早在上个世纪70年代就被发明了出来。原版的TeX语法晦涩难懂,于是有了LaTeX (或写作 $L^AT_EX$ ),后者是建立在TeX 基础上的宏语言,依然使用TeX的排版引擎但语法更加简单。
随着排版语言的进一步发展,LaTeX 又出现了许多变种,如pdfLaTeX 能够将TeX代码编写的文档直接编译到PDF格式(在pdfLaTeX 诞生的年代,LaTeX只能做到将文档编译到PostScript打印机排版格式),再之后出现了XeTeX(XeLaTeX是其别名),可以原生处理utf-8编码的各种文字(例如中文),因此对于非英文编写的文档也可也正确编译。
上面提到的这些都属于排版引擎,而更多情况下我们接触到的是 排版引擎+宏包+格式+驱动+编辑器+... 形成的一个整体,即所谓“发行版”。常见的LaTeX发行版包括MikTex、CTeX、MacTex、TeX Live等。
要想深入区分排版引擎和发行版的区别,可以阅读文章 《LaTeX引擎、格式、宏包、发行版大梳理》 - Rabbyt的文章 - 知乎
TinyTeX
参考: TinyTeX英文版介绍 与 中文版介绍
TinyTeX是一个TeX Live的修改版,由R语言大佬、Rmarkdown核心开发人员谢益辉开发,主要用于R markdown文档向PDF的编译。其编译引擎是XeLaTeX。
熟悉Rstudio的同学应该对Rstudio的knitr一键编译功能印象深刻,这一功能可以实现从R markdown笔记源代码编译到好看的html网页。然而knitr是可以进行设置的,通过一些高级设置,可以让R markdown笔记直接编译到PDF格式,这一功能就是通过TinyTeX实现的。不过今天我们要讲的并非TinyTeX在Rstudio里的应用,而是在系统的命令行中调用这一工具,以及借助TinyTeX将jupyter notebook转换为PDF格式的文档。
TinyTex的安装方法如下(需要在R语言解释器中执行下面的代码):
1 | install.packages('tinytex') # 安装`tinytex`R包,这个包并非TinyTeX本身,而是后者的安装程序 |
安装完成以后,可以直接在R语言中调用tinytex进行文档渲染。
当然,tinytex也提供了命令行调用的方式,即 xelatex <arguments> 。可以在命令行中使用xelatex --version查看版本信息(如下代码块所示)
1 | ~$ xelatex --version |
Pandoc
jupyter notebook可以将.ipynb格式的笔记本导出为各种格式,包括.html格式,Latex源代码格式(.zip),PDF格式等。其中,jupyter对.html格式拥有原生的支持,而其他格式则需要一些额外的工具(换句话说,pandoc)。
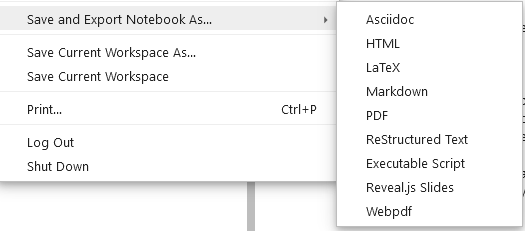
当我们想将.ipynb格式的笔记本导出为其他各种文件格式时,jupyter会调用pandoc这一工具。当系统里面没有安装pandoc时,会出现如下的报错:
至于pandoc,官网对其的介绍如下:
If you need to convert files from one markup format into another, pandoc is your swiss-army knife.
(如果你需要将文件从一种标记语言格式转换为另一种格式,pandoc就是你的瑞士军刀)
pandoc支持几十种格式之间的互转,具体支持的格式和使用方法请参考官方文档。安装方法见这个页面上的介绍 。简单来说,在不同的系统上,可以分别使用下面的指令进行安装:
| 系统 | 指令 |
|---|---|
| Windows | choco install pandoc |
| macOS | brew install pandoc |
| Linux(Debian,Ubuntu,etc.) | sudo apt-get install pandoc |
| Chrome OS | crew install pandoc |
除了使用指令安装以外,还可以从其GitHub仓库的release页面上直接下载编译好的二进制版本pandoc程序或安装包。
安装完成后,可以使用which pandoc指令检查pandoc的安装路径是否加入了系统的环境变量当中(除了Windows系统——Windows上没有which这个指令)。当然,也可也在命令行中输入pandoc --version查看pandoc是否安装成功。
1 | ~$ which pandoc |
借助pandoc这一外部工具,就可以实现ipython notebook导出到各种文件格式的功能,其中导出到Latex源码格式只需要pandoc支持,而导出到PDF同时需要pandoc和latex引擎。
从.ipynb到PDF
大体上讲,有两种方法可以将jupyter notebook的文档导出为PDF:
- 先导出为HTML,然后在浏览器中使用“打印当前网页为PDF”的功能获得PDF
- 通过LaTeX直接编译为PDF
两种方法各有优劣。前一种方法兼容性最强,除了浏览器外基本不需要额外的软件;后一种可以生成媲美出版物的高质量PDF。
鉴于前一种方法非常简单无需多言,下面我们重点讲后一种方法的实现。
当然,前排提醒,经过笔者测试,后一种方法依然存在一点小问题,不过不影响使用。
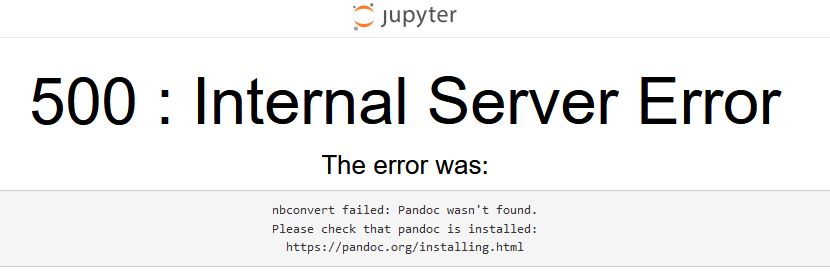
(上图:目前存在的一些“小问题”。貌似jupyter生成的LaTeX源代码中存在一些XeLaTeX无法识别的控制语句。)
鉴于直接在jupyter里面导出到PDF可能会出错,我们可以先导出文档到latex源代码格式(File→Export and Save Notebook as→LaTeX),然后再渲染。
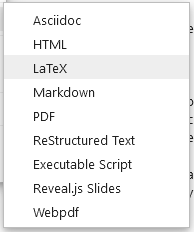
如上图,点击这个按钮后,会有一份.zip格式的源代码包被导出。我们首先要做的是解压这个源代码包。
1 | C:\Users\ab124\Downloads>unzip model-test-2024-1-15.zip -d model-test-2024-1-15 |
压缩包里面的东西很少,只有一个.tex格式的源码文件和一些图片资源文件。
接下来,只需要运行下面的指令即可进行PDF编译:
1 | xelatex model-test-2024-1-15.tex |
输出大致如下图所示:
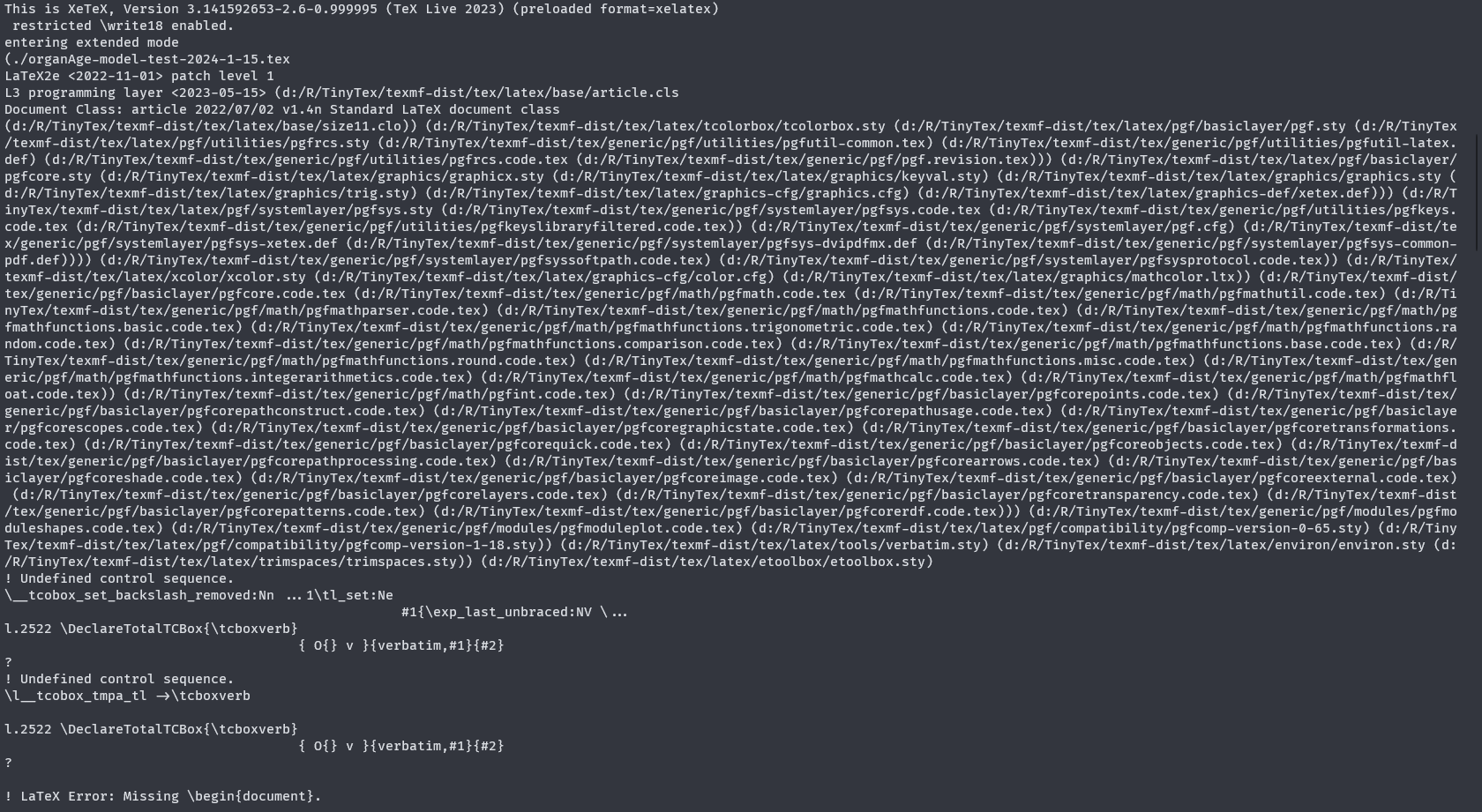
注意到,在前面jupyter提到的一些报错信息,这里我们也遇到了。
但是,但是,但是!
这些报错其实是无关紧要的!(至少目前是这样,感觉是jupyter的锅。可以无视它们直接按回车键。最终会得到一份PDF文件)
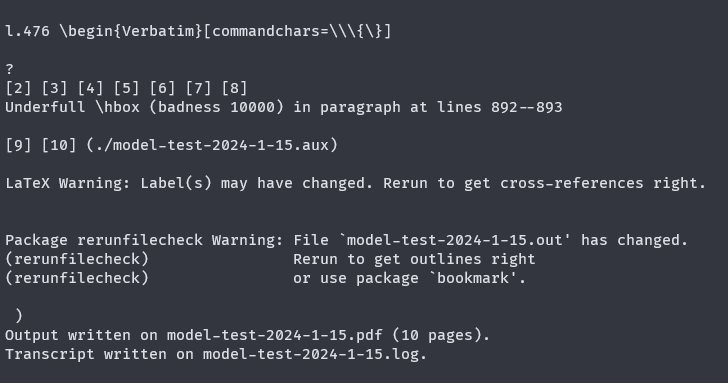
所以我们一路摁回车,忽略这些报错信息。最终的输出如下图,其中列出了一些信息,包括日志文件路径和最终编译生成的PDF文件名称。
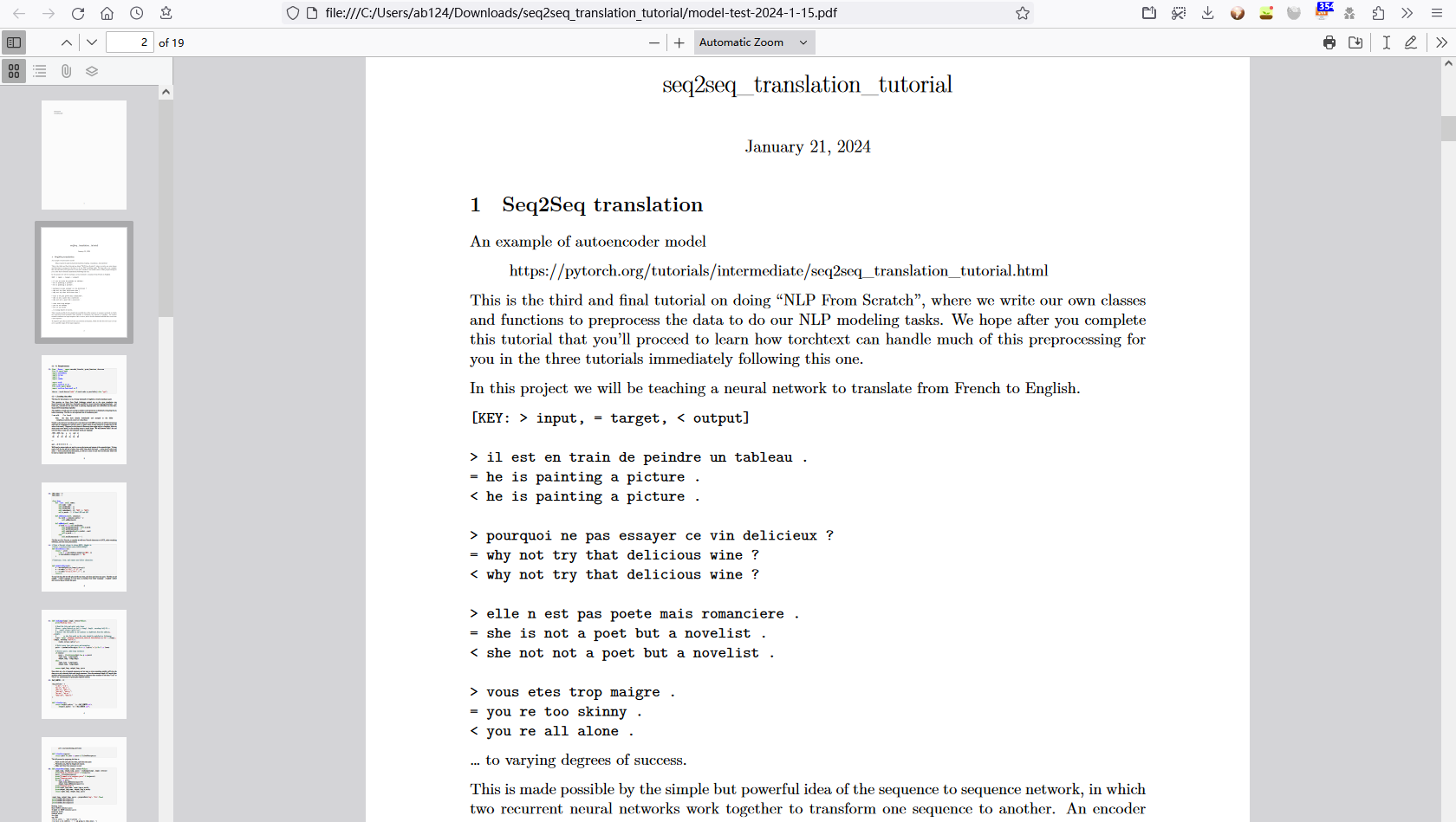
输出的PDF最终效果展示:
当然,这个时候juyter notebook依然无法编译PDF,因为jupyter notebook无法自动忽略上面的那些报错。目前这个问题无解。
一些问题的解决方法
1. LaTeX缺少宏包的问题处理
第一次编译latex可能会报错,这个时候可以看报错内容。有时候报错内容如下
1 | ! LaTeX Error: File `times.sty' not found. |
这种类型的报错意味着宏包没有安装完整,例如上面这段报错表明times.sty没有安装。这个时候我们可以搜索一下缺失的sty文件属于哪个包。可以使用tlmgr指令进行查找,后者是TeX Live自带的包管理器指令。
1 | $ tlmgr search --global --file "/times.sty" |
如上的结果表明,sty文件属于psnfss包。于是我们可以使用下面的指令进行安装:
1 | tlmgr install psnfss |
其他宏包的缺失问题使用同样的方法解决。
2. 含有中文字符的LaTeX文档编译
LaTeX原生只支持英文字符,如果文档含中文,编译出的PDF会在原本该出现中文的地方产生大片的空白。
要实现latex对中文的支持,需要在latex源代码文档首部添加如下的两行代码:
1 | %-- coding: UTF-8 -- |
同时安装Ctex包:
1 | tlmgr install ctex |
1 | D:\R\TinyTex>tlmgr install ctex |
之后,就可以编译含中文字符的文档了。