Attention机制与self-attention详解(二)——Transformer架构
时隔半年,再次复习一下attention机制,并学习一下什么是self-attention。
一、引言:Self-attention(Seq2seq)的常见应用
- 语音识别
- 文本翻译
- 语音翻译(直接将一种语言的音频转化为另一种语言的音频,对于一些没有语言的文字,或者一些语言方言的翻译很有用)

上图:使用1500小时的台语(闽南语?)乡土剧视频资料(带有中文字幕)进行训练,训练前不处理背景音乐的noise问题、语音与字母可能对不上的问题等(所谓“硬train一发”),得到的机器学习模型依然表现出了很强的闽南语识别与翻译的能力。
Seq2seq用于聊天机器人任务(ChatBot)
- 训练集:对话数据。
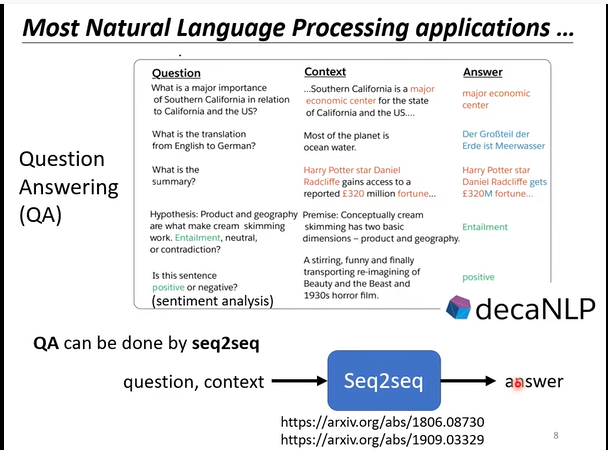
- 许多任务也可以抽象为“Question-Answering(QA)”的模型,例如文本翻译、文章摘要、情感判断等,并使用Transformer训练。
- 当然,对于这些特定任务,其实也不一定用QA这种模型,用一些针对特定任务设计的专用模型可能更好(所谓杀鸡焉用牛刀)
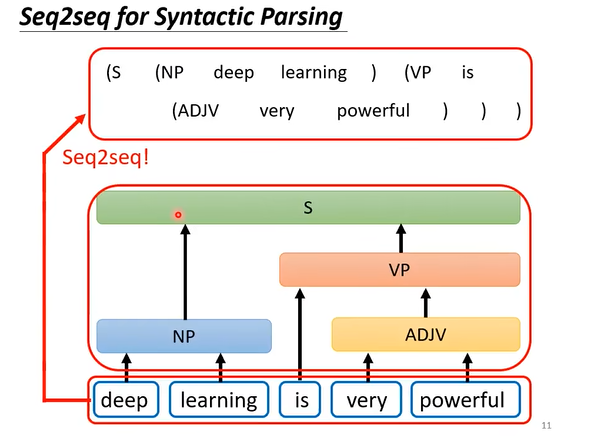
seq2seq用于文法剖析(syntactic parsing)
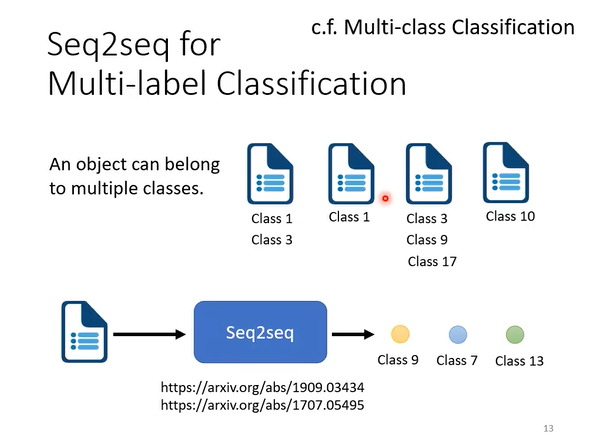
seq2seq用于多标签分类问题(multi-label classification)
- 注意与多类别分类问题(multi-class classification)的区别:一个输入对象可能属于多个分类(class),但只对应一个标签(label)
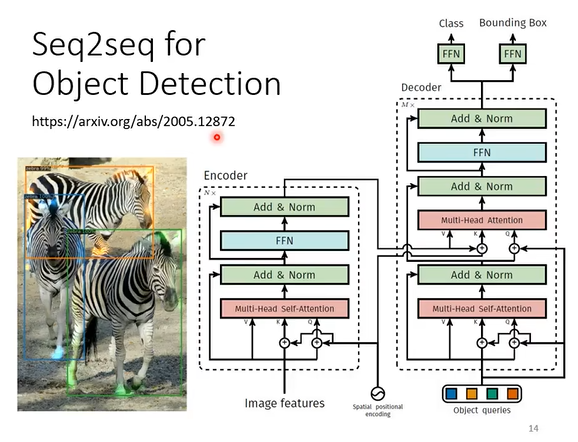
- seq2seq也可以用于图像中的对象识别(虽然有一种硬解的味道在里面)
二、transformer模型(Seq2seq模型)的结构
(一)结构:Encoder-Decoder
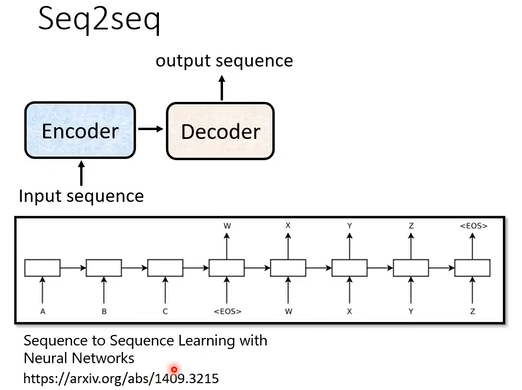
上图是最早提出的Seq2seq模型,用于文本翻译。
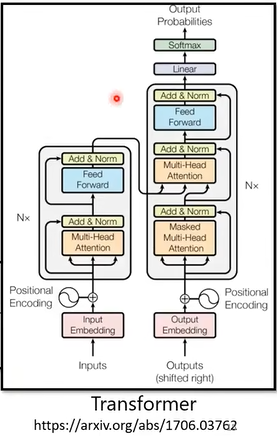
改进后的seq2seq模型,即Transformer
1. Encoder
结构图如下:
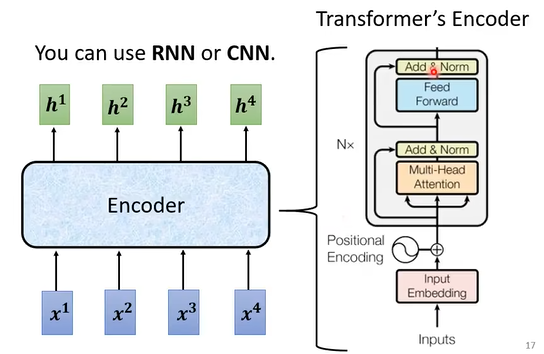
在encoder内部,是self-attention结构。
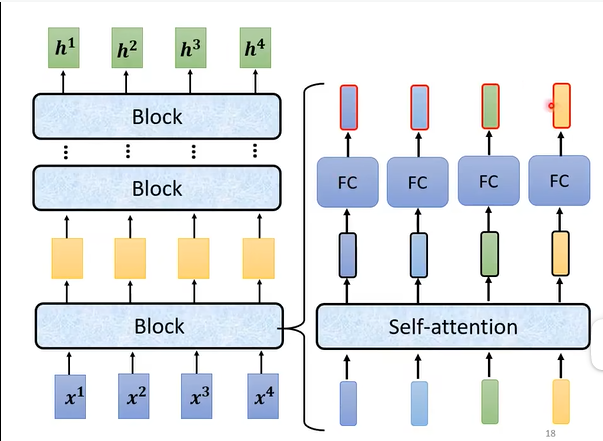
更具体地来看,一个encoder包含了多个block,每个block都是self-attention和全连接神经网络(Fully-connected netwok,FC)的叠加。
下面看看每个block内部的情况:
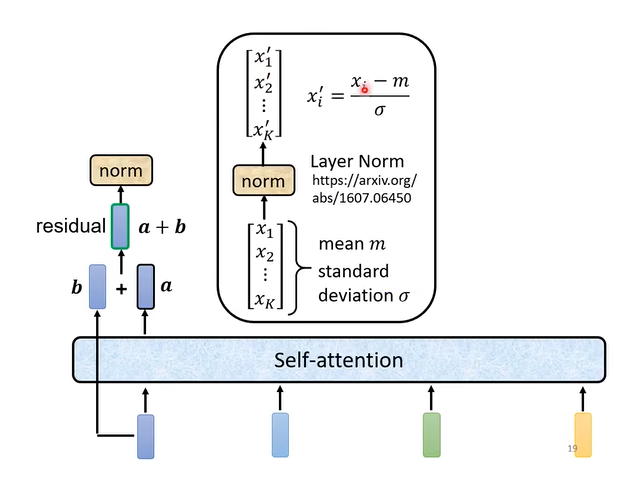
如上图,对于Transformer模型的self-attention层,其采用了一种residual network的机制,其输出等于self-attention的输出与输入的线性加和。此后经过一个layer norm层,输出经过归一化的向量。
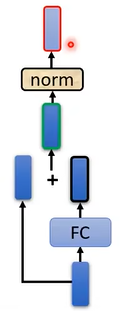
在self-attention层之后,还需要经过FC层的处理。和self-attention层类似,FC层处理后也需要经过residual network的加和处理和norm layer的归一化。
2. Decoder
2.1 autoregressive decoder (AT)
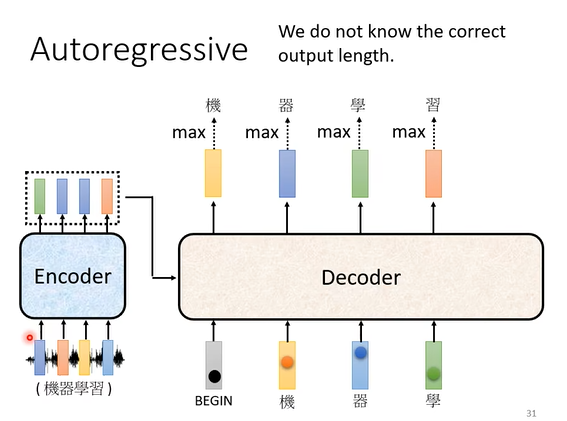
最常用的decoder叫做autoregressive decoder
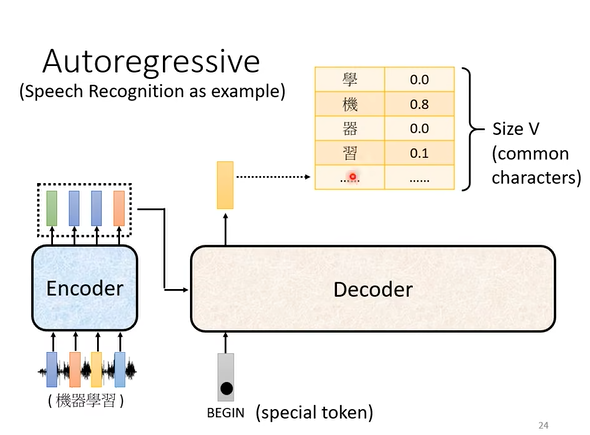
如上图,autoregressive的输入是一个特殊标识符“BEGIN”。(当然,autoregressive decoder也接受encoder的输入,但这一块内容将在后文中讲述)
当一个标识符输入时,autoregressive会输出一个长度为V的向量(其中V代表token词表的大小。以中文文本处理模型为例,token词表是所有汉字,那么V就是所有的汉字数量),这个输出向量的每个元素代表对应token出现在当前位置上的概率。
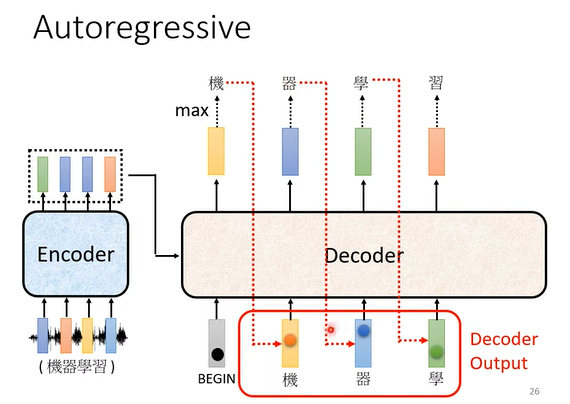
autoregressive会依次产生输出向量,并且第一位的输出会作为第二位的输入进行处理,从而顺序地预测出下一个将要出现的词的概率(可以回想一下,chatGPT在对话的时候,输出内容是一句话一句话往外蹦出的,因为先输出的文字会再次作为输入以用于预测下一句话的输出)
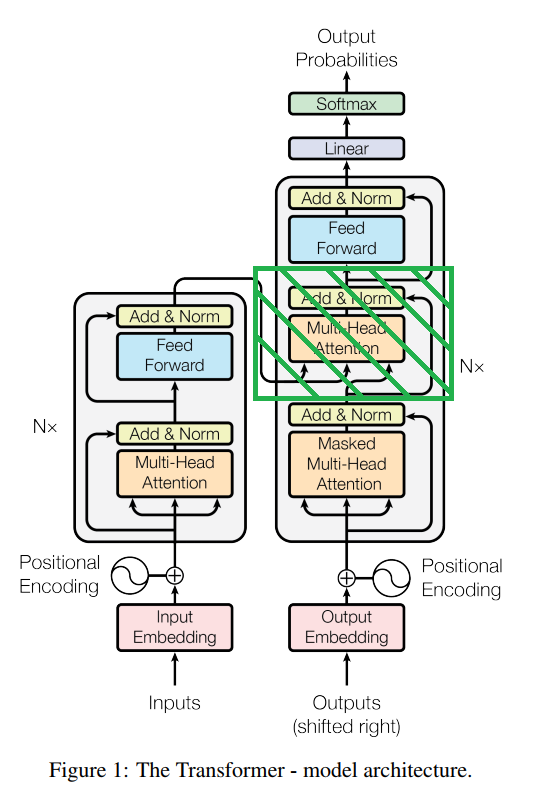
上图为transformer的结构,其中左边为encoder部分,右边为decoder部分。如果我们将decoder部分中间的那个block(图中绿色阴影部分)删除,则decoder与encoder的结构完全一致。也就是说,decoder其实和encoder很像,除了decoder多了中间那一部分的结构。
另外注意一下,decoder的第一个block中,使用的是masked的多头注意力机制,这与encoder也不一样。
所谓“masked”,其具体内容如下图所示,即预测当前位置的输出时,只使用当前位置之前的输入信息,而不考虑这个位置以后的信息。例如,预测 $b^2$ 时,只使用 $[a^1,a^2]$ 的信息;预测 $b^3$ 时,只使用 $[a^1,a^2,a^3]$ 的信息。
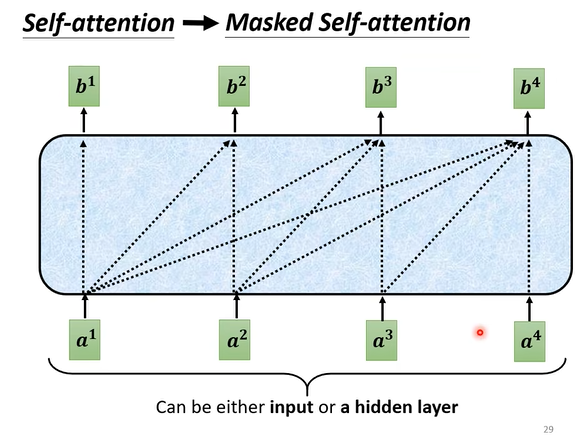
这么做的原因很符合直觉。在transformer模型中,encoder要做的是处理所有输入,因此使用的是没有masked的self-attention;而decoder要做的是按顺序的输出信息,后输出的内容要建立在先前输出的内容的基础上(就像人类思考和说话那样),因此需要这样一个mask的机制。
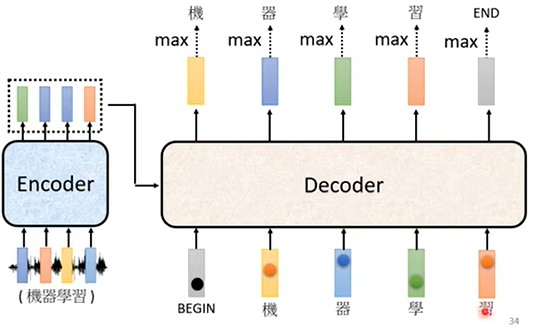
另一个问题是decoder如何决定停下。例如,decoder的前四个输出是“机器学习”,如果没有停止机制,则decoder可能将第四个输出“习”作为输入,然后预测出第五个输出“惯”(假定这个decoder在训练中学习过“习惯”这个词)。
为了防止这种情况产生,我们还需要加入一个特殊的符号“END”,用来表示停止输出,这样,在输出“机器学习”四个字以后,继续输出得到“END”符号,那么此时的模型就知道输出结束,从而停下。
2.2 non-autoregressive decoder (NAT)
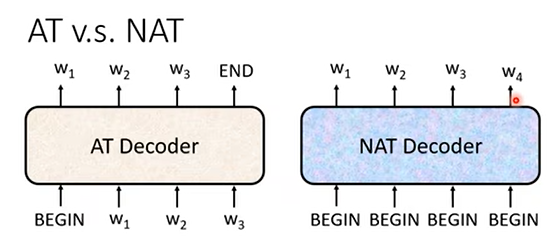
二者的区别如上图。autoregressive decoder只接受一个begin,后续的的输入都来自前一个输出,而non-autogressive decoder可以同时接受多个begin,并同时产生一整句话的输出。
- 如何决定NAT解码器的输出长度?
- 使用另一个预测器获得输出长度
- 或者输出一个很长的序列,然后忽略END之后的标记
- 优点:NAT可以并行处理加速输出,输出长度可控
- 缺点:NAT的表现并不如AT,其中的问题有很多,例如multi-modality问题
(二)Encoder与Decoder的连接
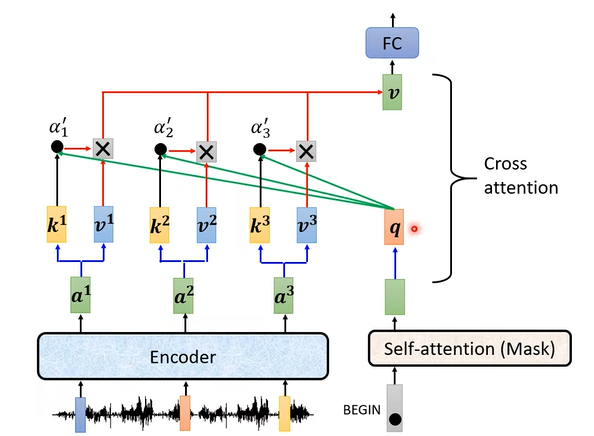
Encoder与Decoder的连接使用了一种叫做cross-attention的机制,如上图所示。这张图就是之前那张transformer结构图中,绿色阴影部分的block内部的结构。
- 注意到,在上图中,encoder部分对输入进行处理,得到一组向量 $[a^1,a^2,a^3,…]$ ,这一组向量再通过数学上的处理得到 $K,V$ 矩阵(即上图的 $[k^1,k^2,k^3,…]$ 和 $[v^1,v^2,v^3,…]$ )。
- 与此同时,decoder部分也会进行处理,从第一个token即“BEGIN”开始,通过数学上的处理得到 $Q$ 矩阵(即上图的 $[q,…]$)。
- 随后就是矩阵乘法的操作即 $\text{softmax}(\frac{Q\times K^T}{\sqrt{d_k}})V$ ,得到输出矩阵 $V$ (即上图中的 $[v,…]$ )
- 输出还会经过全连接神经网络(FC)的处理,从而进入下一层。
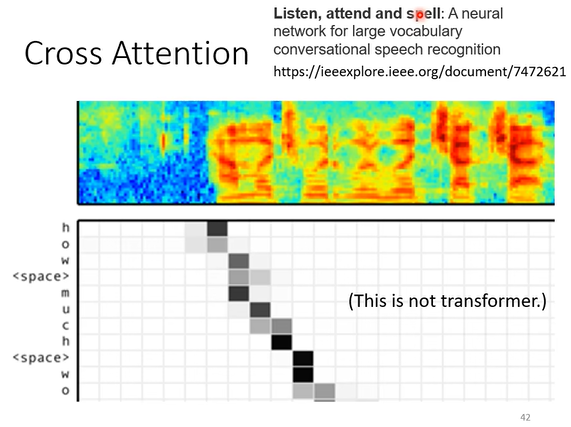
cross-attention机制最早在一项语音翻译模型的工作中被提出,此时还没有Transformer的架构。如上图,展示了cross-attention的attention score,其中横坐标是输入的音频信号的frame位置,纵坐标是输出的字母的位置,图中方块颜色的深浅代表了对应音频信号frame获得的注意力大小,颜色越深注意力越强。。
- 输出从上到下进行,每生成一个字母,这个模型都会将当前字母和输入的音频信号进行处理,并计算最有可能出现在下一个位置上的字母
- 而图中的热图就代表了每输出一个字母时,音频信号中的哪一部分获得了最大的注意。
- 这就是为什么随着输出的进行,注意力最集中的位置也在随音频frame的进行而向右移动(但是这种移动不是完全向右不带回头的)
三、Transformer的训练
(一)输出结果度量
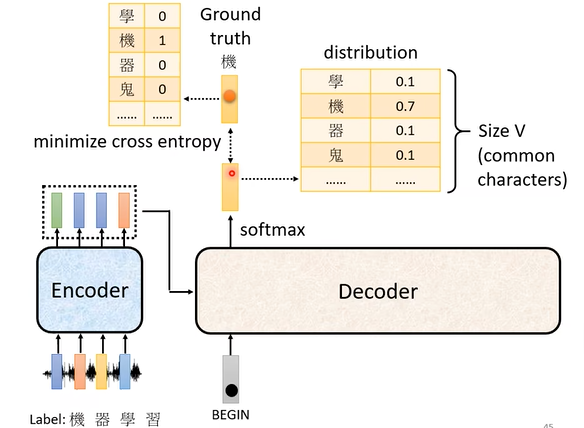
transformer使用交叉熵(cross-entropy)对输出结果进行度量,如上图所示,所谓交叉熵度量的是模型在一个位置的输出与这个位置上的真实输出(ground-truth)之间的差异性。训练目标是最小化交叉熵。
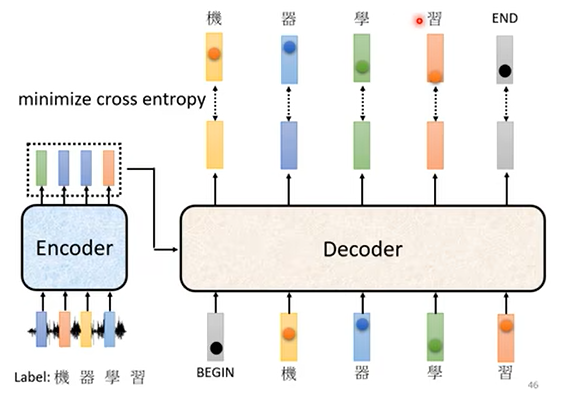
对于每个位置上的输出,都会计算一次交叉熵。
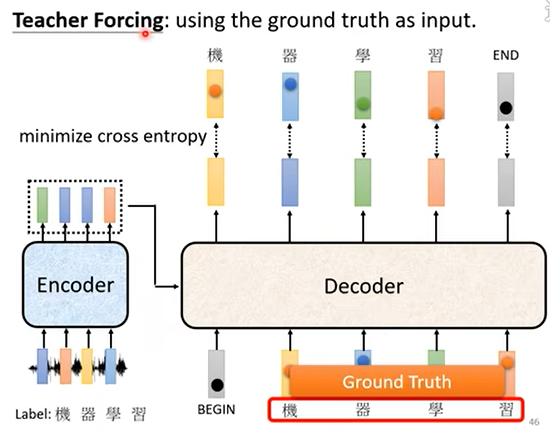
在训练过程中还使用了一种策略,叫做“teacher forcing”,就是在训练时,不论上一个位置上的实际输出是什么,在预测下一个位置上的输出时都使用ground truth的字符作为输入。
(二)扩展知识点
复制机制(copy-mechanism):模型的输出不一定需要自己生成,也可以直接从输入的内容中复制一小部分。如下图,在聊天机器人任务中,输出内容的部分词汇来自输入的情况很常见;此外,在文章摘要任务中,输出内容来自输入的文章的主旨段落,因此也需要这种机制。


想要了解更多,可以查看上述论文。
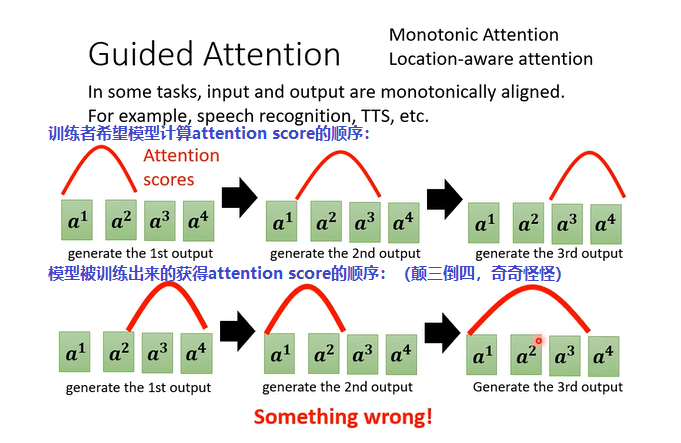
引导学习(guided attention) :硬train一发可能出问题,例如模型忽略了输入中的一些文字,导致输出内容不全(例如文本翻译中一些句子被忽略;语音合成中部分文字被忽略,如下图)。一种方法是通过人工的方法,告诉机器必须采用我们所指定的顺序和方式处理输入内容,从而保证所有的输入都会被用到。一些关键词:Monotonic Attention, Location-aware attention
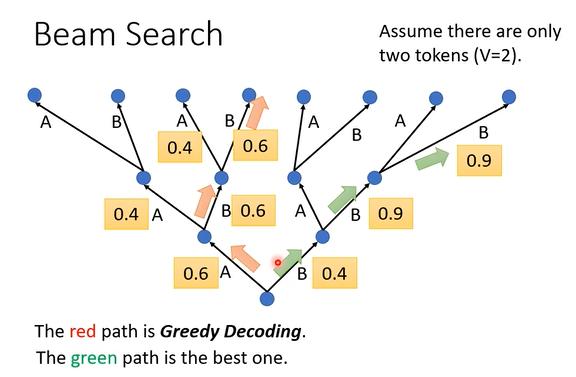
集束搜索(Beam Search) :如下图,decoder在产生每一步的输出时,会采用一种贪心算法选择当前最有可能的那个输出(红色路径)。然而,全局最优的输出可能是通过绿色的那条搜索路径获得的(但绿色路径在某些位置上不是局部最优)。要想获得全局最优,可以使用集束搜索的策略。
集束搜索也不一定在所有时候都好。因为这种策略类似于在模型中引入了一些随机性,这种随机性并不一定是好的。当进行语音识别任务时,当然是越精准越好,此时不应该有随机性的成分在里面;而在进行文本续写、文章创作、语音合成时,引入一定的随机性反而会使生成的结果富含创造性。

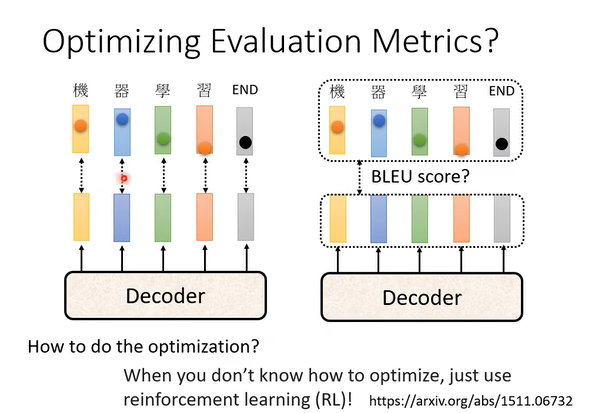
扩展:对输出结果的衡量标准能否进行优化?
- 如下图,左边是使用交叉熵衡量输出结果的准确性,相当于每个词各自计算相关性,然而这样有时候并不太好。
- 另一种方法是将输出的整个句子和ground-truth进行相关性的比较,如右图所示,可以使用一种叫做BLEU score的方法进行。
- 然而后者的计算量很大,模型也更复杂,所以不是很推荐
- 如果真的要使用BLEU score,或许可以配合上reinforcement learning的策略,“硬train一发”,就可以得到很好的结果
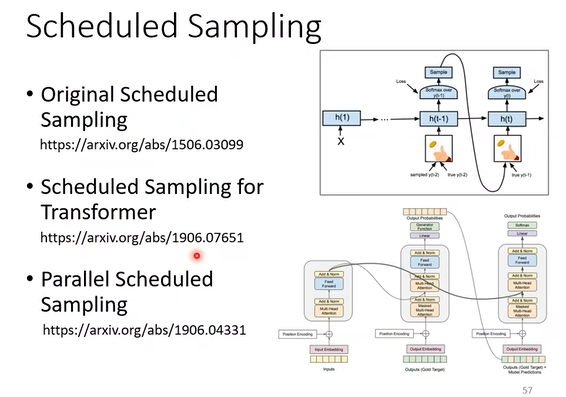
计划采样(Scheduled sampling): 在训练过程中引入噪音(例如,随机替换输入中的一些字符),以增强模型的稳健性。