Fisher精确检验与无监督学习
第六次生物统计学助教课的备课笔记。
本文为生统助教课备课过程的一些记录,主要涉及差异表达分析、基因富集分析、无监督学习的相关知识点,其中的重点包括差异倍数(Fold change)的计算,以及Fisher精确检验。
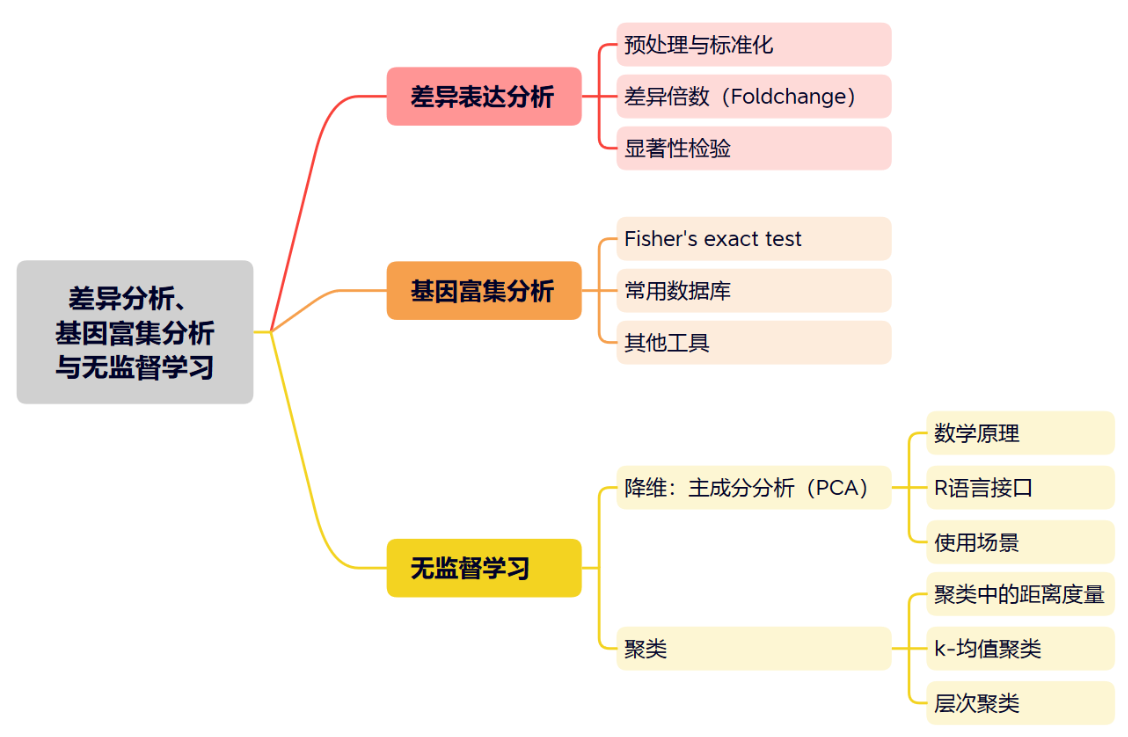
一张图展示本文知识大纲:
一、差异表达分析的基本步骤
- step1 预处理:
- 标准化、填补缺失值
- step2 差异倍数(Fold Change)的计算 :
- $E = mean(group1)$
- $B = mean(group2)$
- $FC = (E-B)/min(E,B)$
- Fold change的threshold一般设为2,但是也可以是其他值
- 缺点:未考虑组内方差
- step3 显著性检验
- 在合适的场景使用合适的检验手段
- 考虑样本量大小、样本是否配对、场景与影响因素数量…
- step4 多重校正
- step5 后续分析:
- 基因集富集分析
- 绘制热图heatmap/pheatmap
- ……
对每个基因进行显著性检验
- 实验组 vs. 对照组
- 大样本,服从正态分布:t.test,根据具体情况判断参数(是否为配对样本、方差是否相等…)
- 小样本:wilcox.test
- 单个影响因素,多种场景(分三组分别给药A/B/C):
- one-way ANOVA
- 多个影响因素,每个因素下多种场景(分多组对应不同给药种类和剂量)
- multiple-way ANOVA
二、基因富集分析与Fisher精确检验
基因富集分析一般是为了解决下面的这些问题

常用的注释数据库(以及资源)如下:

富集分析需要解决的统计学问题是,当我们观察到一部分差异基因落在了GO term或者pathway的基因集里面以后,如何确定这个GO term或者pathway就是显著的。

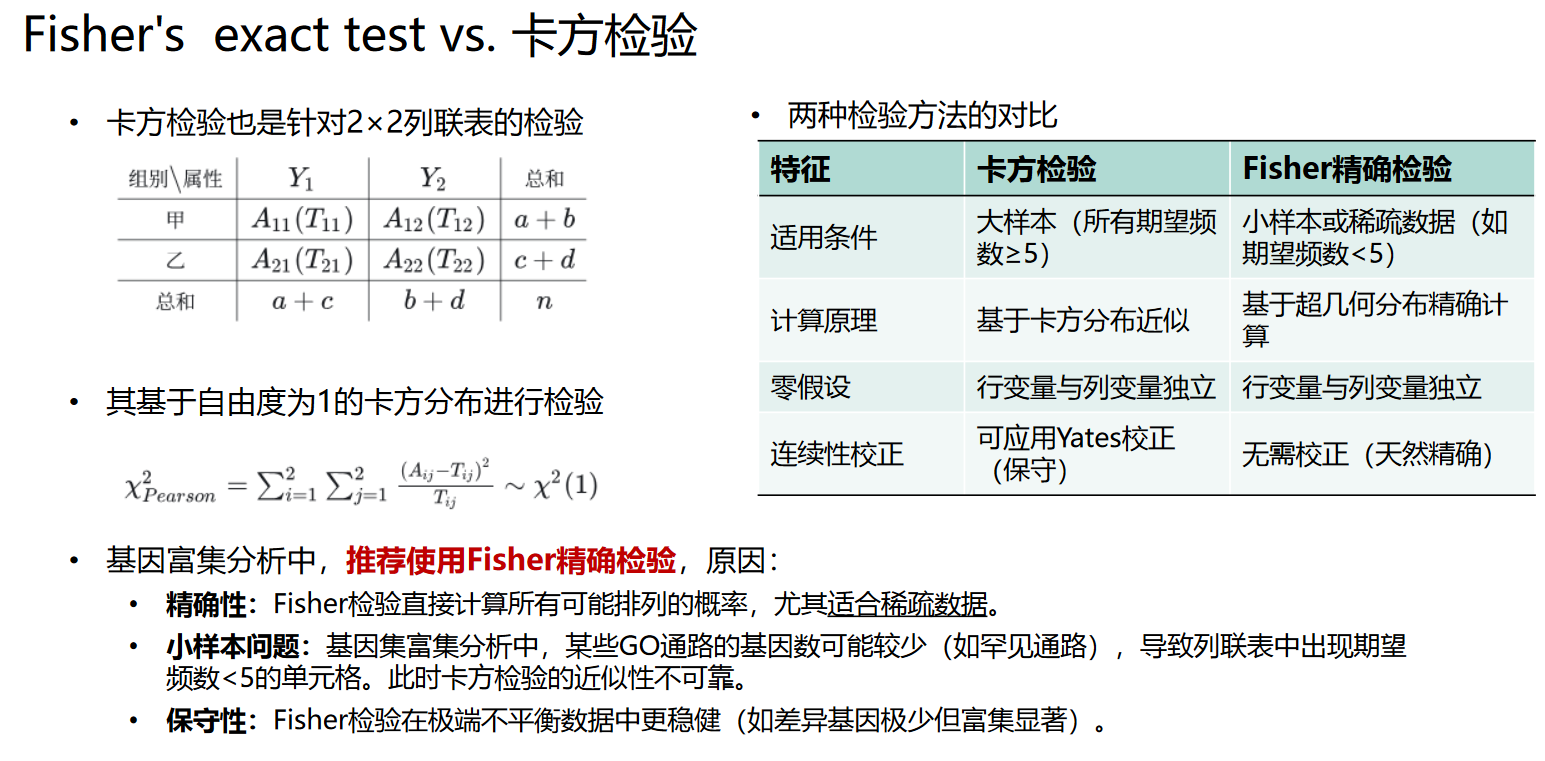
要解决这个问题,一般需要进行2×2列联表检验。2×2列联表检验常用的方法有两种:Fisher精确检验,以及Pearson卡方检验。基因富集分析里面最合适的检验方法是Fisher精确检验
Fisher精确检验
Fisher检验利用了超几何分布的数学原理:


在R语言中,进行Fisher检验可以直接调用 fisher.test(matrix(data=c(a,b,c,d),nrow=2)) ,也可以利用超几何分布的函数接口进行计算:
-
P_val <- min(1-cumsum(dhyper(0:(y-1),X, N-X, n))) -
P_val <- phyper(y-1, X, N-X, n, lower.tail = FALSE)

Fisher精确检验和Pearson卡方检验的比较
基因富集分析中,推荐使用Fisher精确检验,原因:
- 精确性:Fisher检验直接计算所有可能排列的概率,尤其适合稀疏数据。
- 小样本问题:基因集富集分析中,某些GO通路的基因数可能较少(如罕见通路),导致列联表中出现期望频数<5的单元格。此时卡方检验的近似性不可靠。
- 保守性:Fisher检验在极端不平衡数据中更稳健(如差异基因极少但富集显著)。
下面是一道例题。数据和代码见图片,最终的结果是 P=0.1302>0.05 因此检验结果不显著,这条GO通路未被富集。

三、无监督学习
这一部分的知识点相对较少,仅以两页PPT总结:
PCA

聚类
